






基于Mineru的PDF和word文档解析
1.Mineru 介绍
MinerU是一款将PDF转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。
2.主要功能
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为LaTeX格式
- 自动识别并转换文档中的表格为HTML格式
- 自动检测扫描版PDF和乱码PDF,并启用OCR功能
- OCR支持84种语言的检测与识别
- 支持多种输出格式,如多模态与NLP的Markdown、按阅读顺序排序的JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检
- 支持纯CPU环境运行,并支持 GPU(CUDA)/NPU(CANN)/MPS 加速
-
兼容Windows、Linux和Mac平台
3.主要原理
参考官网:MinerU
4.镜像地址
阿里云地址:docker pull crpi-99azmmphmxwdoi76.cn-guangzhou.personal.cr.aliyuncs.com/lijinxuan/mineru:v2
DockerHub: docker pull leekinxun/mineru
启动命令:
docker run -itd --name=mineru_v2 -v {挂载提取图片的路径,非必需}:/output/images -e IMAGE_PATH={挂载识别图片的路径,非必需} --gpus=all -p 9988:8000 leekinxun/mineru:v2进入容器:
docker exec -it mineru_v2 /bin/bash
uvicorn app:app --host 0.0.0.0 --port 8000若需要获取解析后的图片,需填写两份挂载内容且必需保持一致,例如 -v /home/data:/output/images -e IMAGE_PATH=/home/data
5.接口文档
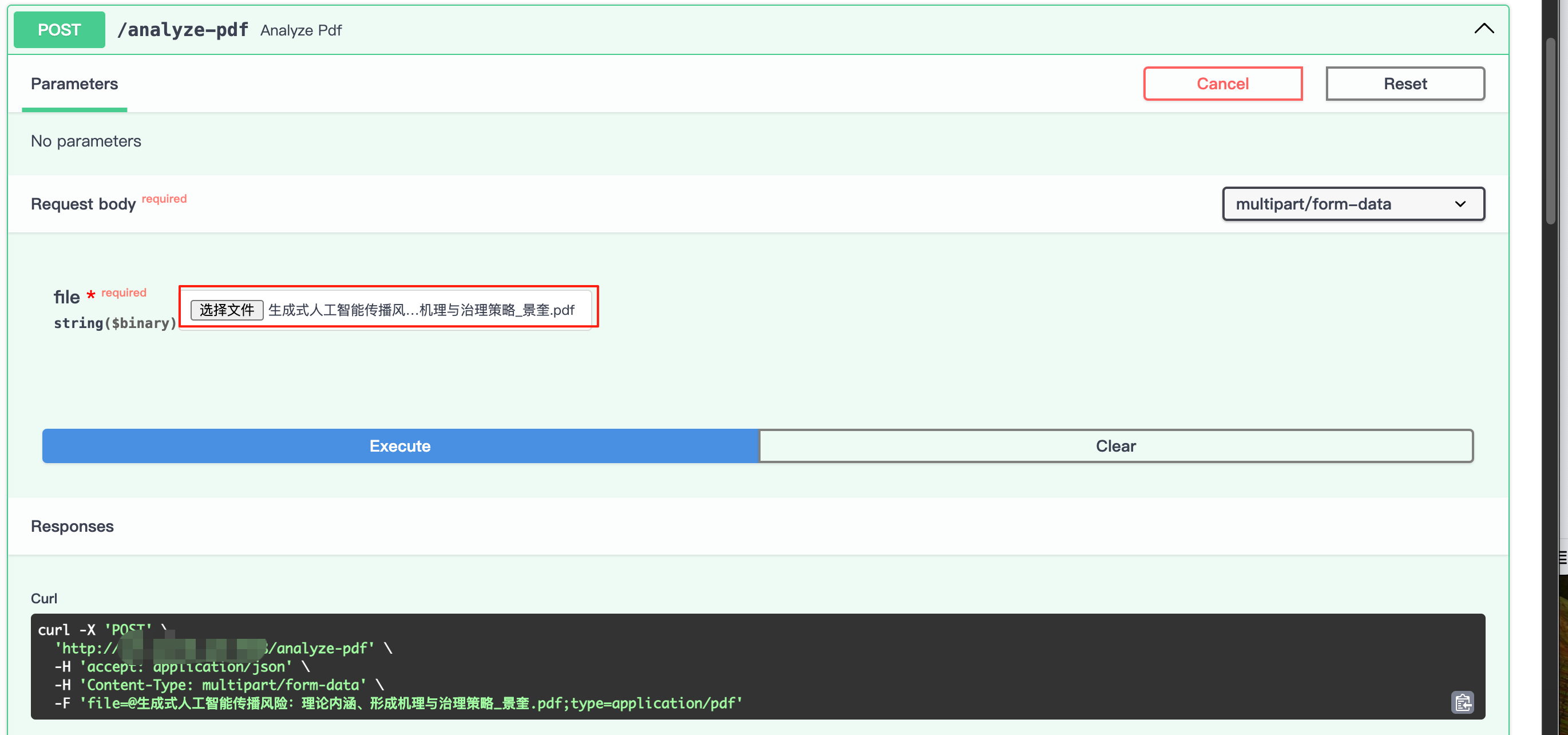
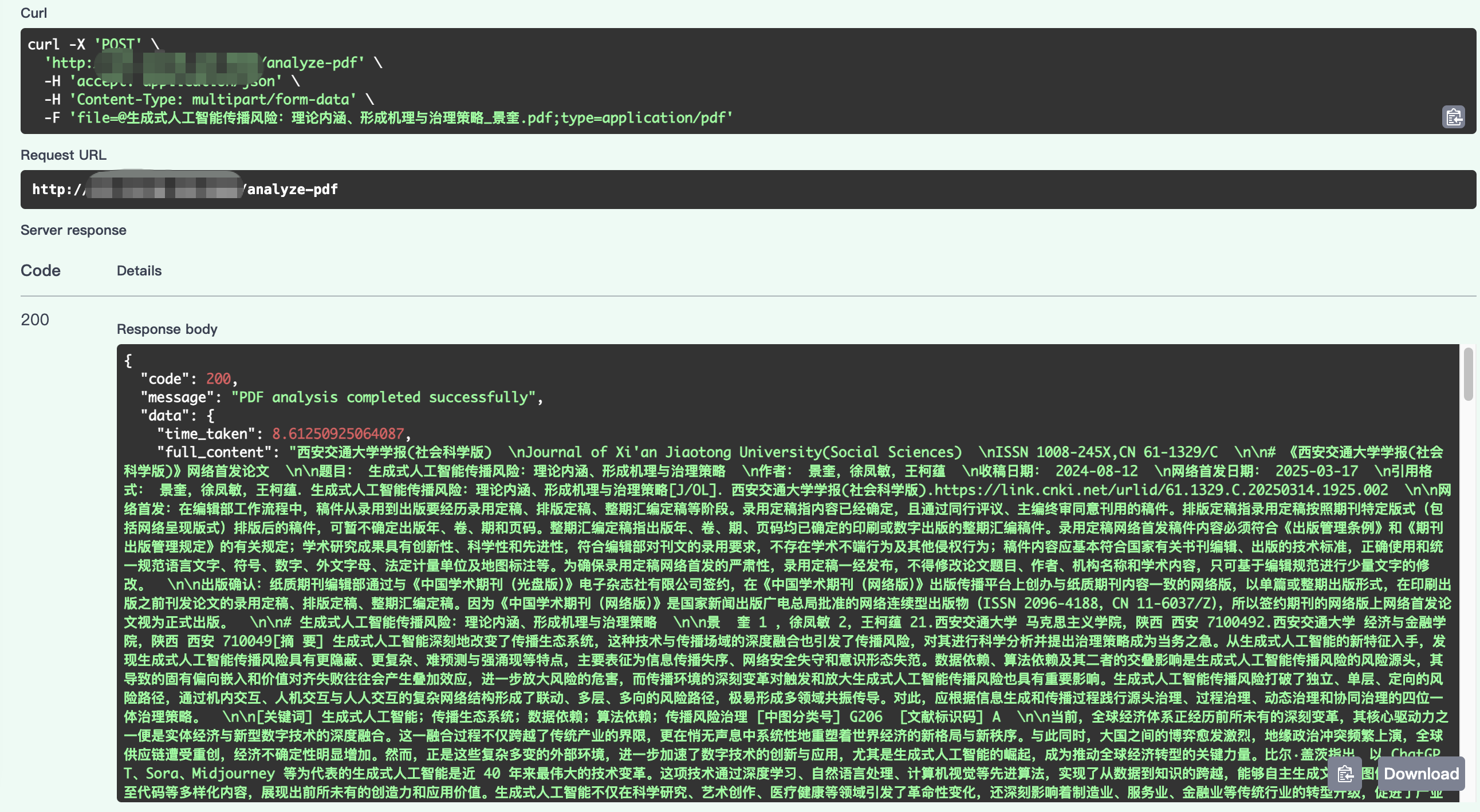
6.Python 调用示例:
async def process_pdf_logic(pdf_file):
"""
解析PDF文档
"""
# 验证文件类型
if not pdf_file.content_type.startswith("application/pdf"):
raise Exception(400, "仅支持 PDF 文件")
try:
target_url = "http://localhost:9988/analyze-pdf"
files = {
"file": (pdf_file.filename, pdf_file.file, "application/pdf")
}
async with httpx.AsyncClient(timeout=120.0) as client:
response = await client.post(
target_url,
files=files,
headers={"Accept": "application/json"}
)
response.raise_for_status()
result = response.json()
content_list = result["data"]["full_content"]
return content_list
except httpx.RequestError as e:
raise Exception(503, f"无法连接到解析服务: {str(e)}")
except Exception as e:
raise Exception(500, f"服务器内部错误: {str(e)}")async def process_doc_logic(doc_file):
"""
解析Word文档(PPT/PPTX/DOC/DOCX)并转发到解析服务
"""
allowed_extensions = {".doc", ".docx", ".ppt", ".pptx"}
file_ext = os.path.splitext(doc_file.filename)[1].lower()
if file_ext not in allowed_extensions:
raise HTTPException(status_code=400, detail="仅支持doc、docx、ppt、pptx格式文件")
# 根据文件类型设置MIME类型
mime_types = {
".doc": "application/msword",
".docx": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
".ppt": "application/vnd.ms-powerpoint",
".pptx": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
try:
target_url = "http://localhost:9988/analyze-doc"
files = {
"file": (doc_file.filename, doc_file.file, mime_types[file_ext])
}
async with httpx.AsyncClient(timeout=120.0) as client:
response = await client.post(
target_url,
files=files,
headers={"Accept": "application/json"}
)
response.raise_for_status()
result = response.json()
return result["data"]["full_content"]
except httpx.HTTPStatusError as e:
raise HTTPException(
status_code=e.response.status_code,
detail=f"文档解析服务返回错误: {str(e)}"
)
except httpx.RequestError as e:
raise HTTPException(
status_code=503,
detail=f"无法连接到解析服务: {str(e)}"
)
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"服务器内部错误: {str(e)}"
)7.温馨提示
mineru:v2版本做了文件类型限制,目前仅支持PDF、DOC、Docx,若需要增加PPT和PPTx,需要删除docker中app.py中的97行内容:
if file_ext not in ['.doc', '.docx']:
raise HTTPException(status_code=400, detail="Only .doc and .docx files are supported")8.返回结果展示:
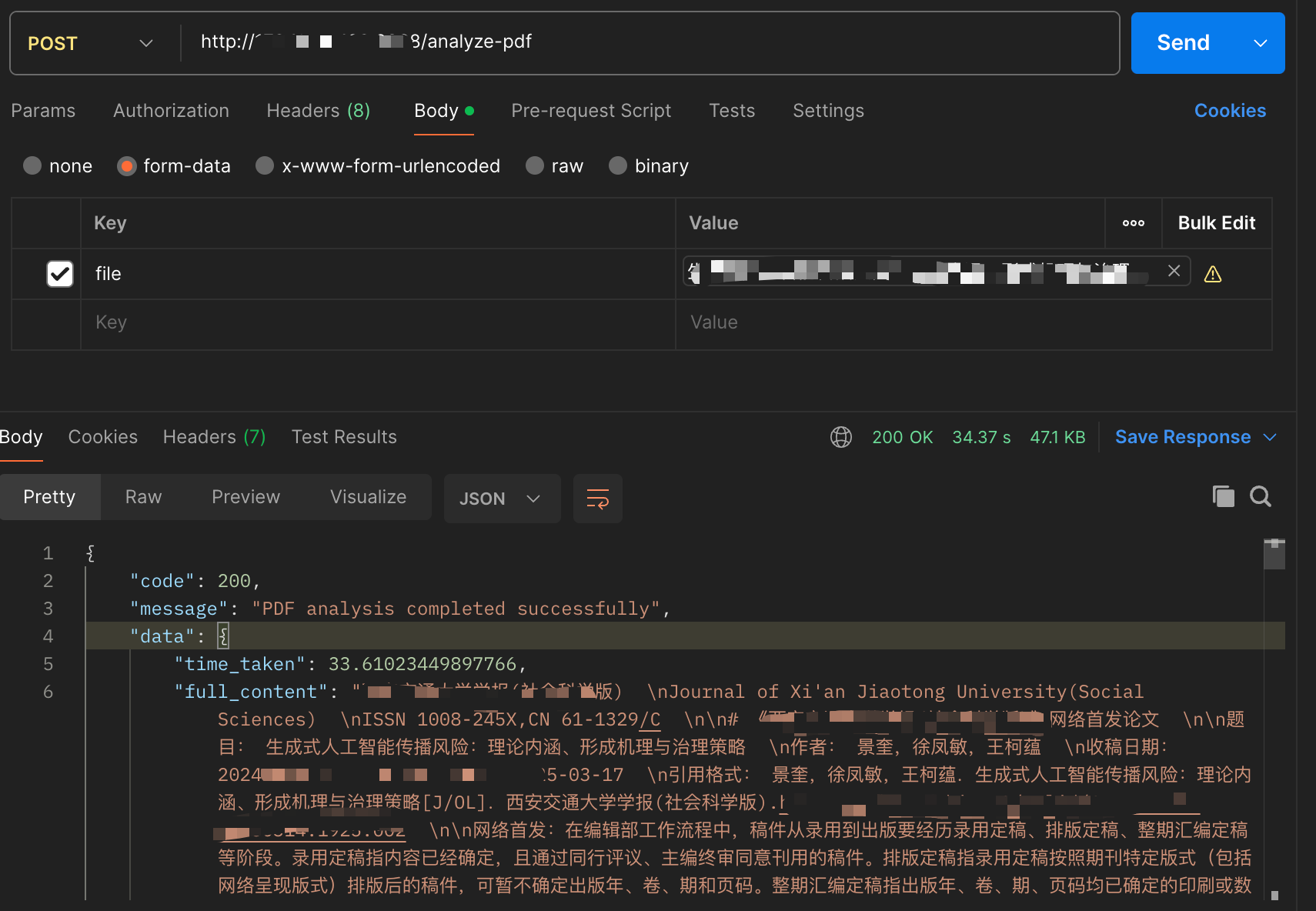

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









