






 本文介绍如何使用Python爬虫抓取雪球网的搜索结果。通过分析请求方式和参数,发现需要`sortId`、`q`(搜索关键词)、`count`和`page`。在添加了cookie到headers后,成功获取数据。文章提供测试代码及完整代码示例,数据存储可使用pandas。后续文章将继续分享Python爬虫相关知识。
本文介绍如何使用Python爬虫抓取雪球网的搜索结果。通过分析请求方式和参数,发现需要`sortId`、`q`(搜索关键词)、`count`和`page`。在添加了cookie到headers后,成功获取数据。文章提供测试代码及完整代码示例,数据存储可使用pandas。后续文章将继续分享Python爬虫相关知识。
前言
本文是该专栏的第8篇,后面会持续分享python爬虫案例干货,记得关注。
地址:aHR0cHM6Ly94dWVxaXUuY29tLw==
需求:根据目标搜索词,获取搜索结果数据
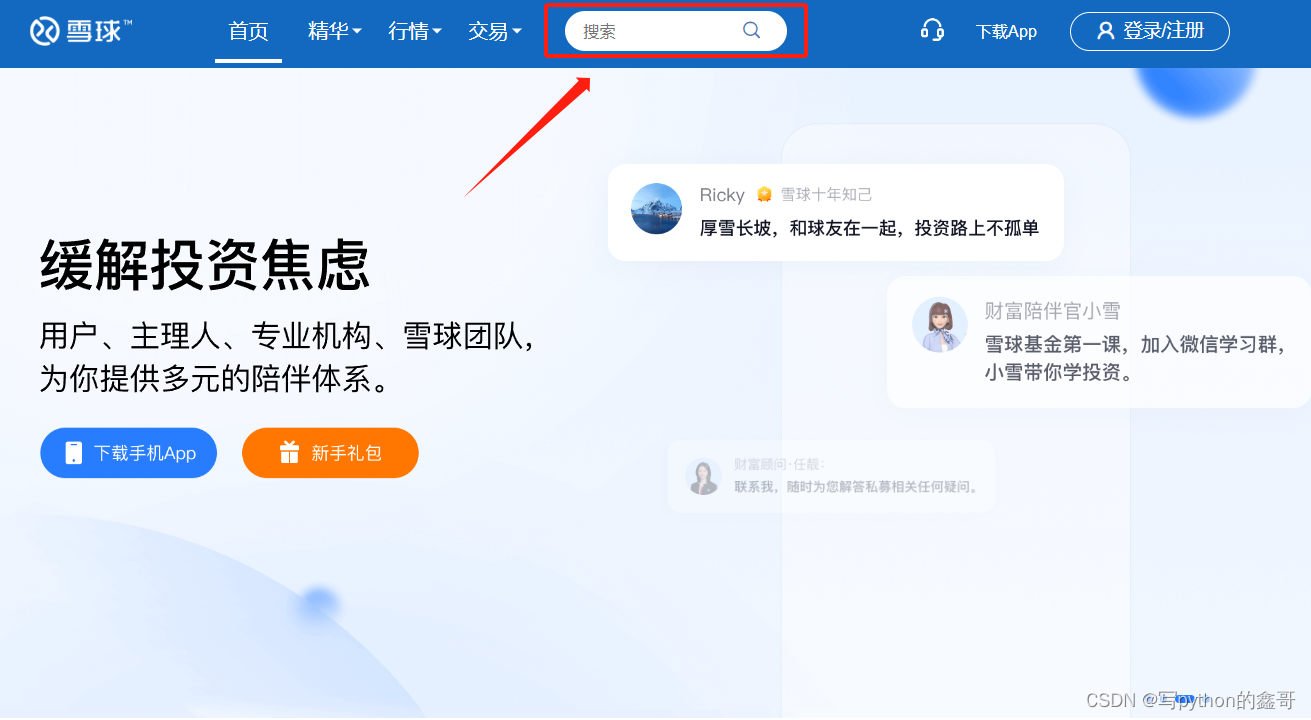
废话不多说,跟着笔者直接往下看详细内容。(附带完整代码)
正文
1. 请求方式和参数分析
使用浏览器打开链接之后,直接F12键启动控制台。并在关键词输入框处随机输入某关键词,如下图所示:

前言
本文是该专栏的第8篇,后面会持续分享python爬虫案例干货,记得关注。
地址:aHR0cHM6Ly94dWVxaXUuY29tLw==
需求:根据目标搜索词,获取搜索结果数据
废话不多说,跟着笔者直接往下看详细内容。(附带完整代码)
正文
使用浏览器打开链接之后,直接F12键启动控制台。并在关键词输入框处随机输入某关键词,如下图所示:
 1069
9095
1618
1069
9095
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























