







众所周知,线性回归主要是用于预测,而当我们所研究的问题是一个分类问题,这里简化为一个二分类(假定两类为0和1)问题的话,由于线性回归目标函数y的输出域为负无穷到正无穷,因此线性回归就无法满足我们的需求。因此,我们就想到要将一般线性回归模型的输出从负无穷到正无穷映射至0到1之间(这里假定为输出的是将样本划分为1的概率),这样当目标函数的输出大于0.5时,我们将该样本划分为1;当目标函数小于0.5时,我们将该样本划分为0。
基于这种想法,我们将对线性回归做一个变化,将其输出域从正无穷到负无穷映射到零一之间。假定线性回归函数为:
引入非线性函数
g(z)
后,原来的函数就变成了
其中,
g(z)=11+e−z
,这里的
g(z)
被称为sigmoid函数,这样我们就能得到引入非线性变换后的表达式了:
此时
hθ(x)
定义为给定一个样本
x
,输出
sigmoid函数
g(z)
图像如下所示:
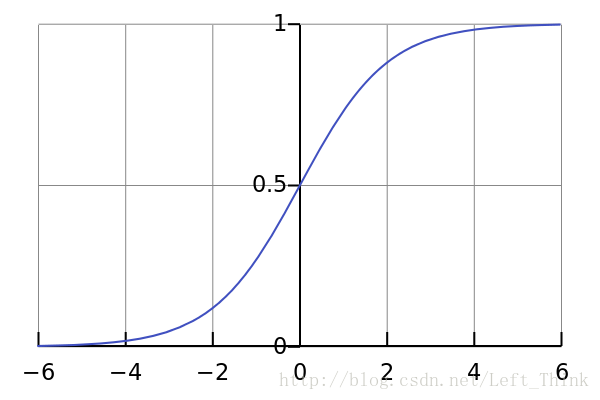
分析预测策略:
- 当 hθ(x)≥0.5 时,也就是 g(θTx)≥0.5 ,通过观察上图中当纵坐标大于等于0.5时,横坐标是大于等于0的,也就是 θTx≥0
- 当 hθ(x)<0.5 时,也就是 g(θTx)<0.5 ,通过观察上图中当纵坐标小于0.5时,横坐标是小于0的,也就是 θTx<0
因此,在Logistic回归中以
hθ(x)=0.5
为我们的决策边界(当
hθ(x)≥0.5
时,
y=1
;当
hθ(x)<0.5
时,
y=0
)。用
θ
和
x
表示就是
损失函数
上面介绍了决策边界,一单我们确立了决策边界就可以对未知的样本做预测了。而决策边界是由模型的参数所决定的,因此我们需要定义一个损失函数来对参数进行优化,使我们的决策边界划分样本的准确率达到最佳。
在线性回归中,我们定义的损失函数是误差平方和:
如果我们按照线性回归中定义误差函数的方式来定义Logistic回归的损失函数,那么损失函数形如:
由于我们的损失函数中 hθ(x) 为非线性函数,因此上面定义的损失函数 Cost(hθ(x),y) 是一个非凸函数,对于非凸函数,我们想要求其最优解十分困难。于是,我们便想要去构造一个凸的损失函数来代替这个非凸的损失函数。
我们通过定义一个新的损失函数如下所示:
当 y=1 时, 损失函数的图像如下所示:
如果我们的输出 hθ(x) 接近于0,说明预测值和真实值误差很大,那么损失函数趋向于无穷大;而当我们的输出 hθ(x) 接近于1,说明预测值和真实值误差很小,那么损失函数则趋向于0。
当 y=0 时, 损失函数的图像如下所示:
如果我们的输出 hθ(x) 接近于0,说明预测值和真实值误差很小,那么损失函数则趋向于0;而当我们的输出 hθ(x) 接近于1,说明预测值和真实值误差很大,那么损失函数趋向于无穷大。


这样我们就得到了一个凸的损失函数了,将分段的损失函数合并为一个函数:
因此整个数据集上的损失函数为:

















 1787
1787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









