







本文为百度的Deep Speech的论文笔记,本人为深度学习小白,文章内如有错误,欢迎请各位指出~
附上我的github主页,欢迎各位的follow~~~献出小星星~
什么是端到端?
对于传统的语音识别,通常会分为3个部分:语音模型,词典,语言模型。语音模型和语言模型都是分开进行训练的,因此这两个模型优化的损失函数不是相同的。而整个语音识别训练的目标(WER:word error rate)与这两个模型的损失函数不是一致的。
对于端到端的语音识别,模型的输入就为语音特征(输入端),而输出为识别出的文本(输出端),整个模型就只有一个神经网络的模型,而模型的损失采用的CTC Loss。这样模型就只用以一个损失函数作为训练的优化目标,不用再去优化一些无用的目标了。
Deep Speech1
Deep Speech1的结构如下图所示:
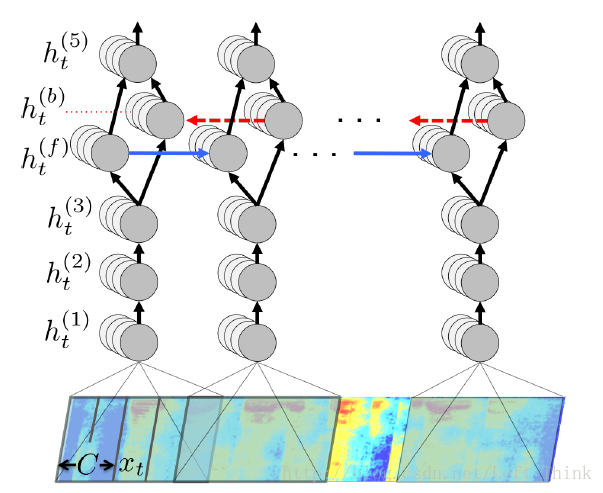
全连接层
网络的前三层为全连接层,第一个全连接层的输入为语音的频谱数据(注意:图中是把5帧的频谱数据当做一个 xt 输入到隐藏单元中,因为可能一个单词的发音对应了多个帧的频谱数据)。全连接层的输出计算公式为:
其中
g()
为隐藏单元的激活函数,本文中使用了clipped ReLu作为隐藏单元的激活函数,
W
为权重矩阵,
文章中使用的clipped ReLu函数表达式为:
双向RNN层
第4层为双向的RNN层,其中 h(f)t 为前向(从左至右)的rnn层, h(b)t 为反向(从右至左)的rnn层,计算公式如下所示:
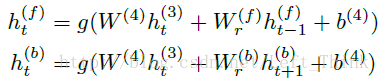
以前向RNN为例,其中
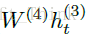
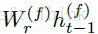
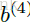
而此处的g()为之前叙述的clipped ReLu函数。
而网络的第五层则是非RNN层,主要是将第4层中的前向RNN和反向RNN求和作为隐藏单元的输出,然后经过的计算与普通的全连接层相同,其计算公式如下所示:
最后的第六层为softmax层,预测的是每个时间段内,将该段时间的语音识别为每个字母的概率。
模型采用的损失函数为CTC Loss,有关于CTC Loss的相关介绍可以查看我的另一篇博客。

















 2551
2551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









