










 文章探讨了StableDiffusion对GPU的要求,包括影响速度的因素如分辨率、采样方法和GPU性能。推荐中高端显卡如RTX4090/4080,或12GBVRAM的RTX3060以平衡性能与预算。
文章探讨了StableDiffusion对GPU的要求,包括影响速度的因素如分辨率、采样方法和GPU性能。推荐中高端显卡如RTX4090/4080,或12GBVRAM的RTX3060以平衡性能与预算。
以Stable Diffusion为代表的AI生图工具,是AI技术在内容创作行业中不断发展的结果。要在本地计算机上运行Stable Diffusion,需要一款强大的显卡(GPU)来满足要求。
那么,Stable Diffusion需要什么档次的消费级显卡呢?你的显卡符合运行要求吗?一起来看下吧!
1.什么影响Stable Diffusion的速度?
(1)操作步骤
调整步骤会影响生成图像所需的时间,但不会改变每秒迭代的处理速度。虽然许多用户选择20到50步,但将步数增加到大约200步通常会在每次运行中产生更一致的结果。
(2)分辨率
图像分辨率不仅会对性能产生很大影响,还会影响生成图像所需的VRAM量。为了进行基准测试,你可以考虑使用512×512的分辨率,以确保与各种GPU型号的兼容性。
(3)采样方法(Euler、DPM等)
采样方法对生成时间有显著影响,其中某些选项所需时间大约是其他选项的两倍。 “Euler” 和 “Euler a” 是应用最广泛的方法,通常具有最佳性能。而其他方法(如 DPM2)通常需要大约两倍的时间。
(4)GPU
GPU对速度和图像质量影响最大。更强大的 GPU 具有更高的内存带宽和更多的 显存(VRAM),可以更快地生成高质量图像,特别是在较高分辨率下表现更出色。GPU 上的 VRAM 数量决定了可以生成的最高分辨率图像。建议至少选择8GB显存,若需要处理更高分辨率的图像,则建议选择12GB或更高。
(5)CPU
尽管 GPU 处理大部分繁重的工作,但快速的 CPU 仍然能在一定程度上提高性能。具有更多内核的 CPU 可以带来一定的性能提升。
(6)RAM
系统内存(RAM)同样重要,您可以使用 8GB RAM 运行Stable Diffusion。不过,16GB将显著提高性能和稳定性。使用 16GB 或更高内存将确保Stable Diffusion有足够的空间运行,而不会出现任何潜在的问题。
2.Stable Diffusion:GPU测试
“Tom's Hardware”在 45 个最新的 Nvidia、AMD 和 Intel GPU 上对 Stable Diffusion 进行了基准测试,看看它们的表现如何:
(1)Stable Diffusion 512×512性能
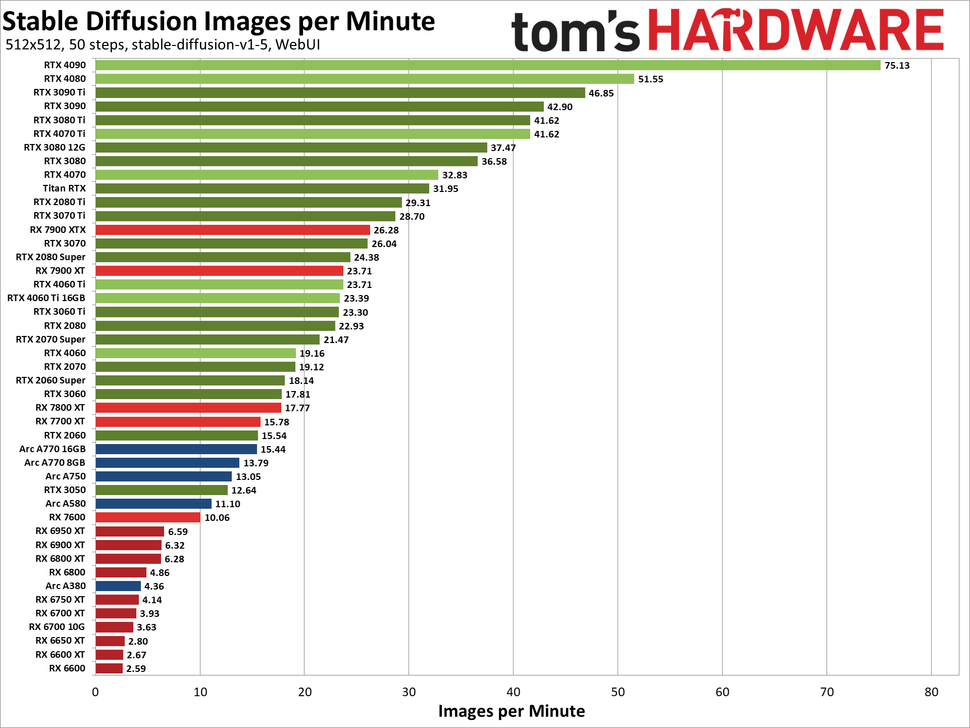
图源:Tom's Hardware
在测试中,RTX 4090以每秒超过一张图像的速度(每分钟75张)快速生成512x512图像。相比之下,AMD最快的GPU RX 7900 XTX仅达到该性能水平的三分之一左右,每分钟处理26个图像。而Intel当前最快的GPU Arc A770 16GB每分钟仅管理15.4个图像。
此外,较新的架构并不意味着性能一定更出色。例如,4080相较于3090 Ti性能提升了10%,计算能力提升了20%。然而,3090 Ti拥有更高的原始内存带宽(1008GB/s,而4080则为717GB/s),这显然也是一个重要因素。值得一提的是,即便是较老的图灵一代也表现出色,新发布的RTX 4070仅比RTX 2080 Ti快12%,理论上计算量仅增加了8%。
(2)Stable Diffusion 768×768性能
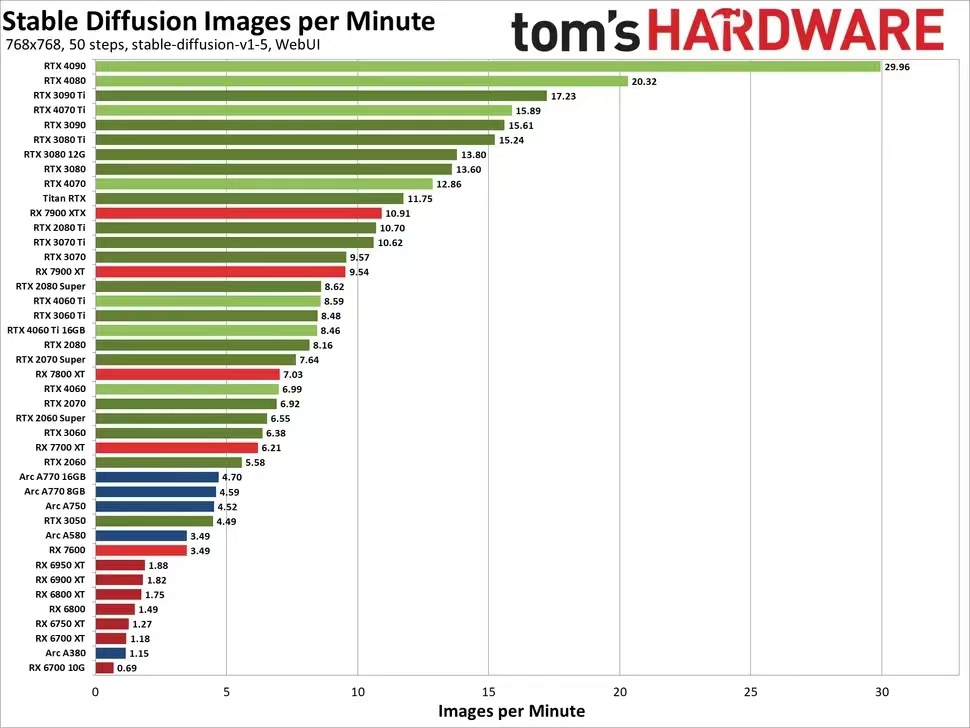
图源:Tom's Hardware
将分辨率提高至 768x768 后,要保证 Stable Diffusion 正常运行,需要更多的 VRAM。此外,内存带宽的重要性也变得更为突出。
虽然各种 Nvidia GPU 的排名没有发生太大变化,但在 AMD 的 RX 7000 系列中,RX 7800 XT 及以上版本取得了一定进展,而 RX 7600 则略有下降。在 512x512 分辨率下,7600 比 7700 XT 的表现慢了36%,但在 768x768 分辨率下,下降到了44%。
上一代 AMD GPU 的处境更加艰难。RX 6950 XT 甚至无法在一分钟内处理两张图像,而 8GB 的 RX 6650 XT、6600 XT 和 6600 更是无法渲染单个图像。此外,英特尔的 Arc GPU 也在更高分辨率下失去了优势。在处理 768x768 图像时,4090 比 Arc A770 16GB 快了6.4 倍。
3.总结
总之,在中档显卡运行Stable Diffusion是可行的,但生成AI图像的速度可能会不及高端显卡。如果预算允许,选择16或24GB VRAM的RTX 4090和4080是理想的选择;就性价比而言,目前选择12GB VRAM的RTX 3060显卡也是一个不错的选项,适用于AI生图、内容创作、游戏等多种场景。

你的显卡是什么型号呢?在你预算内,买什么显卡合适?欢迎留言,小编可以帮你出出主意哦~

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









