






一:论文简介
YOLO9000:Better,Faster,Stronger
2017 VCPR
448*448
学习的资料:https://www.bilibili.com/video/BV1yi4y1g7ro?p=2
二:YOLOv2的改进:Better
1.Batch Normalization
原文:Batch Normalization有利于提高收敛速度,帮助模型正则化减少其他形式正则化的需要。通过使用BN层,可以移除Dropout来减少过拟合。
BN层的作用是把一个mini-batch内的所有数据,从不规范的分布拉到正态分布。这样做的好处是使得数据能够分布在激活函数的梯度较大的区域,因此也提高了泛化能力,可以在一定程度上解决梯度消失的问题,同时可以减少dropout的使用。当参数更好地向前传播后,梯度的下降会更加稳定,可以使用更大的学习率来加快学习。对数据分布的不断调整也减轻了对参数初始化的依赖,利于整体调参。

(1)计算mini-batch中的均值
(2)计算mini-batch内的方差
(3)对每一个元素进行归一化
(4)进行尺度缩放与偏移操作(scale and shift):偏移和尺度为参数,通过训练来学习,目的是为了补偿网络的非线性表达能力。
https://blog.csdn.net/m0_56066265/article/details/125695934
2.High Resolution Classifer
在最后10个epoch,输入448*448像素的图片进行预训练,这使网络更好地适应高分辨率的输入,然后在test数据上进行微调。High Resolution Classifer提高了模型4%的mAP。
原因: 一般模型的训练都是以224 × 224 尺寸大小在ImageNet上进行训练的,而YOLOv1模型最后的输入图像448×448,如果一个模型原来是在小尺寸上进行训练的现在又在大尺寸上进行训练,那么网络就要学会切换这两种分辨率会带来模型性能的下降。
原文链接:https://blog.csdn.net/qq_38683460/article/details/126333243
3.Convolutional With Anchor Boxes
在卷积特征提取提取器的顶部,YOLO直接使用全连接层预测边界框的坐标,基于Anchor的一种边界框预测方式。预测偏移要与直接预测坐标而言简单许多,使网络更容易学习。
更详细的学习看:https://blog.csdn.net/qq_38683460/article/details/126333243
4.Dimension Cluetres 维度聚类
Faster-RCNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),设想能否一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就应该更容易学到准确的预测位置,YOLOv2使用k-means聚类算法对训练集中的边界框做了聚类分析,尝试找到合适尺寸的Anchor。
作者发现如果采用标准的k-means聚类,在box的尺寸比较大的时候其误差也更大,而希望的是误差和box的尺寸没有太大关系。所以通过IOU定义了如下的距离函数,使得误差和box的大小无关:
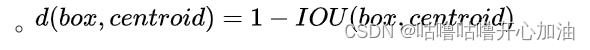
centroid为聚类时被选作中心的bounding box;box为其他的bounding box。
YOLOv2采用的5种Anchor可以达到的Avg IOU是61,而Faster-RCNN采用9种Anchor达到的平均IOU是60.9,也即是说本文仅仅选取5种Anchor就可以达到Faster-RCNN中9种Anchor的效果。
https://blog.csdn.net/zimiao552147572/article/details/105159170
https://blog.csdn.net/IanYue/article/details/126431408
k-means的实现:
(1)从样本中随机选取k个点作为聚类中心点
(2)对于任意一个样本点,求其到k个聚类中心的距离,然后,将样本点归类到距离最小的聚类中心,直到归类完所有的样本点(聚成k类)
(3)对每个聚类求平均值,然后将k个均值分别作为各自聚类新的中心点
(4)重复2、3步,直到中心点位置不在变化或者中心点的位置变化小于阈值
优点:原理简单,实现起来比较容易;收敛速度较快,聚类效果较优
缺点:初始中心点的选取具有随机性,可能会选取到不好的初始值。
5.Direction location prediction
作者发现模型预测的不稳定大部分来自锚框x,y导致。
作者在引入anchor机制后遇到的第二个问题就是在模型训练的初期,预测框的坐标以前的计算公式参考了Faster RCNN的方法,公式如下:
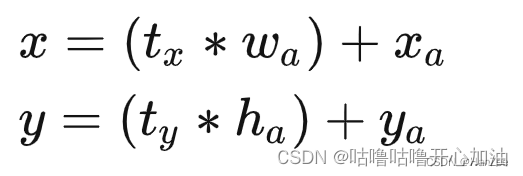
但是这个方法tx、ty是不受限制的,在训练初期数值不稳定,于是作者对其做了归一化处理,对tx ty做了sigmid归一化。tx、ty为模型输出的偏移量。使用此方法提高了%5。我其实对这个公式和定义不太理解,但我觉得大概意思是:模型预测tx、ty,但大小不受限制,加入Sigmoid函数后,输出为0-1,其大小受到限制,有利于模型的学习。使每个Anchor负责预测目标中心落在某个grid cell区域内的目标。
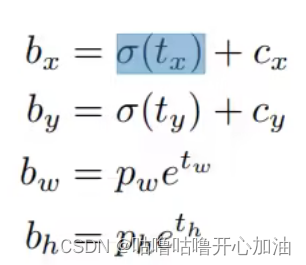
备注:
(1)Bounding box和Anchor box
而Bounding box和Anchor box总是搞混,查了一下资料,感觉Bounding box(边界框)是最终框住目标的框,也就是最终看到结果的框;Anchor box(锚框)是在目标检测中预定义的框,比如提前设定的5种大小的框。
(2)Sigmoid
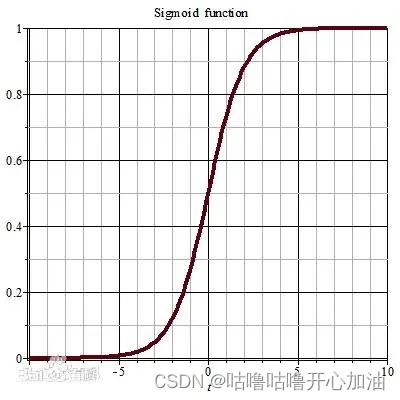
sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid函数为神经网络中的激励函数,是一种光滑且严格单调的饱和函数。
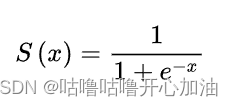
优点:平滑、易于求导。
缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
6.Fine-Grained Features
在最终的预测特征图上,再去结合 一些更底层的特征信息,因为底层的信息包含了更多的图像细节在里面,而这些细节在需要检测小目标是需要的。所以,作者将高层信息和低层信息进行融合。模型提高了1%。
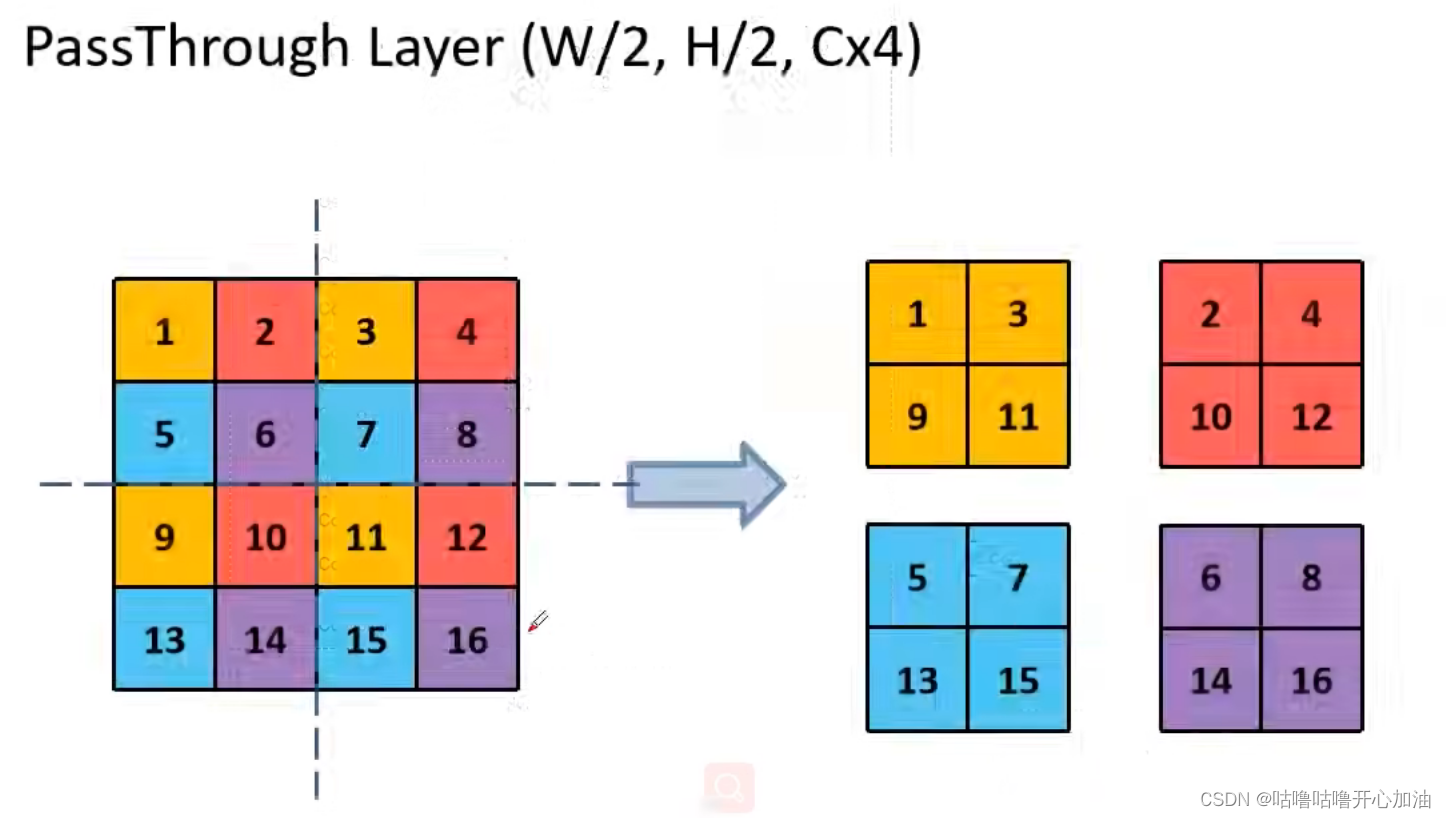
Faster R-CNN和SSD在网络中输出不同的特征层来得到大范围的分辨率,本文采取不一样的方法,通过passthrough layer将相对低层的特征图和高层特征图进行融合。YOLOv2最终得到的特征图是13*13,将26*26通过passthrough layer与13*13进行融合。
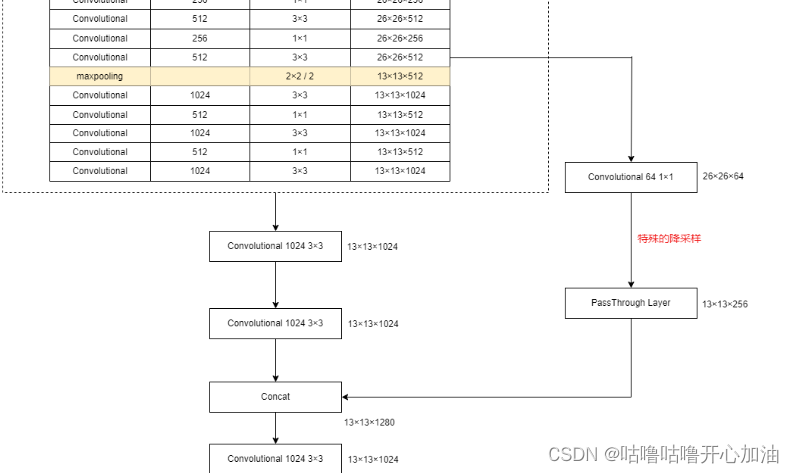
先将26*26通过1*1卷积核进行降维:(26-1+2*0)/1+1=26,然后通过pathrough layer得到13*13*256。最后将13*13*256(低)和13*13*1024(高)在深度上进行拼接,最终得到13*13*1280。
7.Multi-Scale Training
作者希望YOLOv2对于各种尺寸的图像输入具有鲁棒性。每10个batches,网络的输入尺寸在(320、352、...、608)内进行随机选择。由于模型的下采样因子为32,由于输入是416,最终得到的是13,416/13=32,所以,输入网络的尺寸为32的整数倍。
三:Faster
1.Backbone
Darknet-19(共有19个卷积层)

Darknet-19以224*224作为输入,在ImageNet上Top-1的准确率为72.9%,Top-5的准确率为91.2%。这里以224*224作为输入,是因为大部分网络模型都以224*224作为输入,便于与其他模型进行比较。
2.模型框架
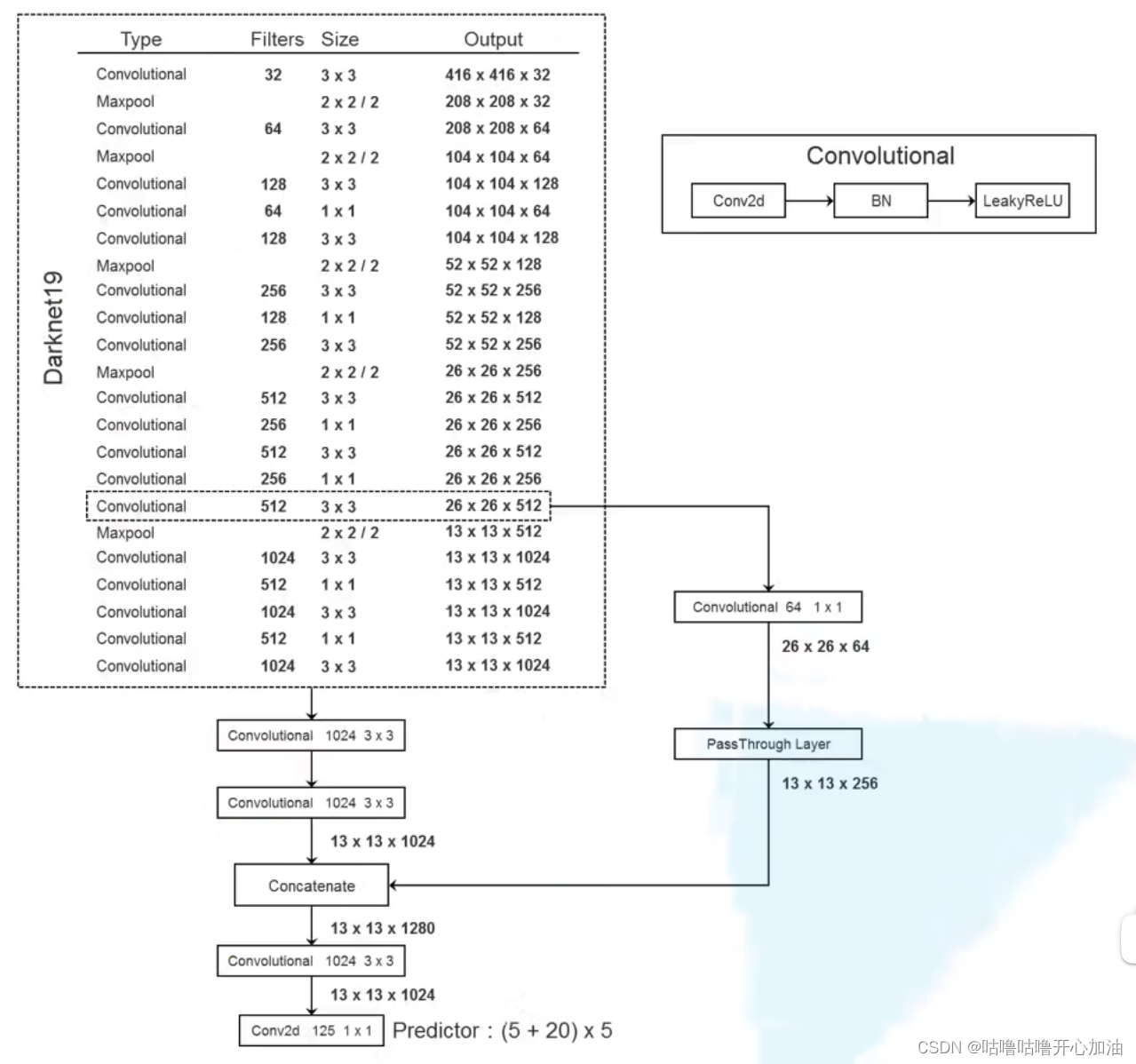
将Darknet-19最后的卷积、平均池化和softmax删除,添加3个3*3卷积核个数为1024的卷积层,最终加入一个1*1卷积核个数为125的卷积。对于VOC数据集,会预测5个boxes,包含5个定位信息和20个类别,5*(5+20)=125















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









