






一:论文简介
YOLOv3:An Incremental Improvement
2018 CVPR
学习资料:3.1 YOLO系列理论合集(YOLOv1~v3)
二:内容
1.Backbone:Darknet-53
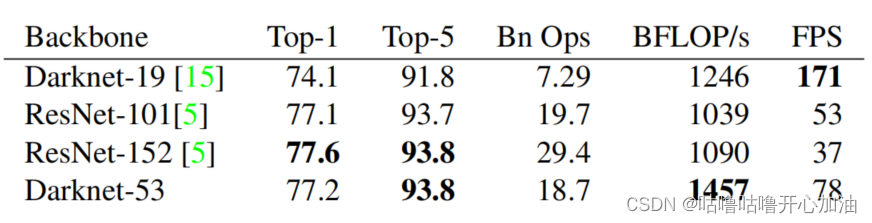
BFLOP/s:浮点运算次数,可以用来衡量算法/模型复杂度。
FPS:指画面每秒帧数
Darknet-53的FPS是ResNet-152的两倍,但准确度与其差不多,所以选取Darknet-53作为backbone。
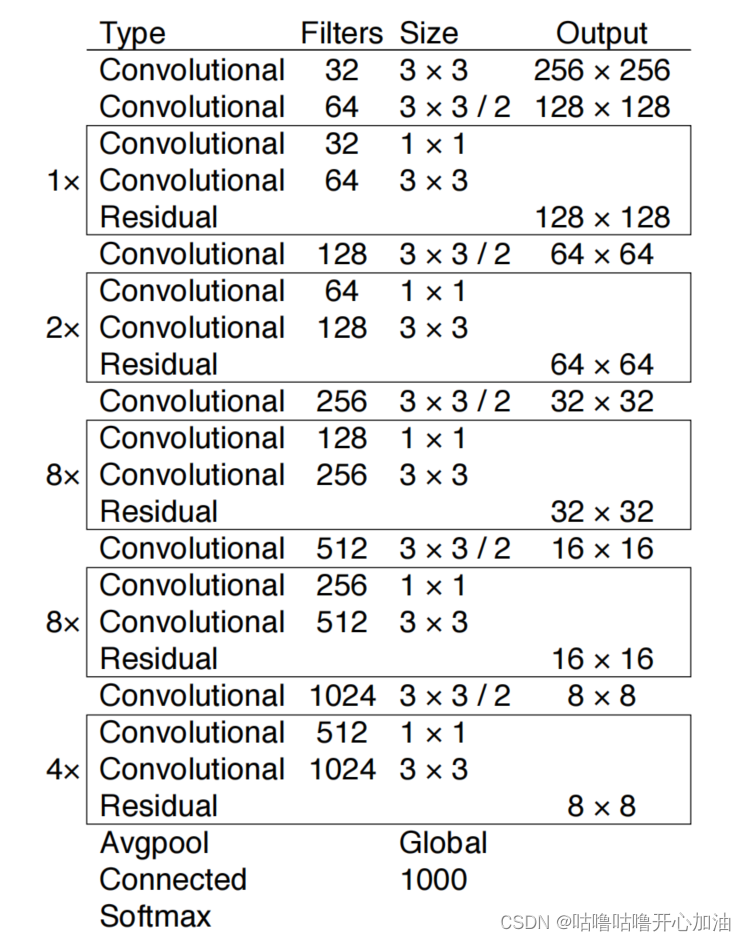
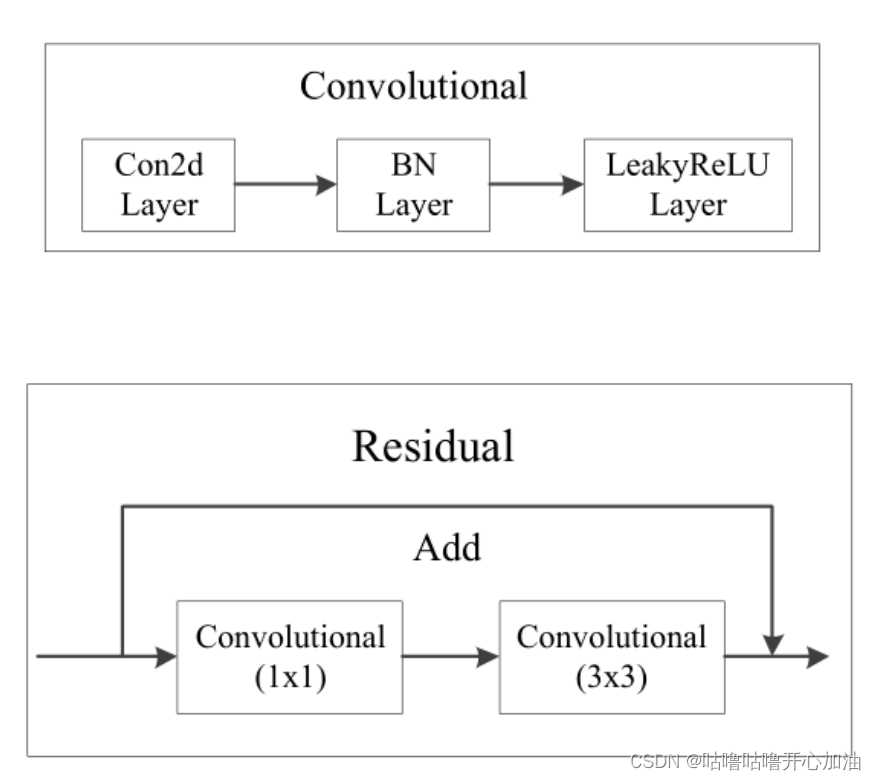
与ResNet相比,没有Maxpooling层,通过卷积进行下采样,所以检测精度提高;卷积核个数比ResNet少,网络参数则减少,则运算量减少,所以FPS提高。其中,卷积和残差结构如下图所示。
2.YOLOv3模型
YOLOv3在三个预测特征图上进行预测,每个预测特征图上会使用三种尺度的boxes,这三种尺度通过k-means聚类方法得到。所以最终的输出为N*N*[3*(4+1+80)],N代表预测特征图的大小。

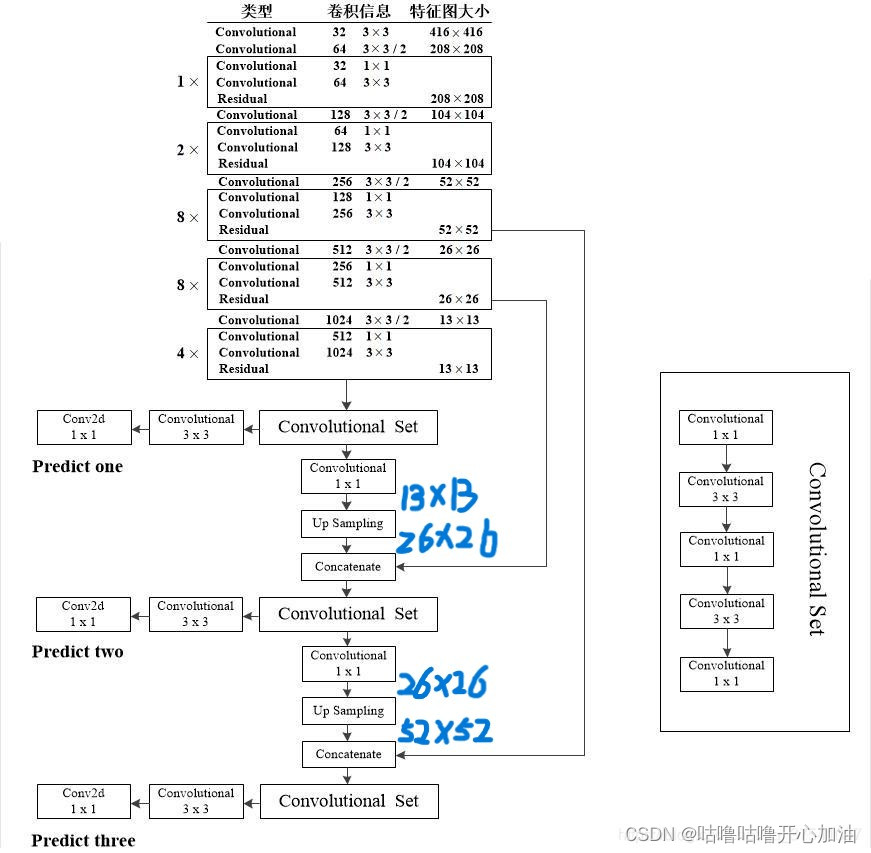
通过上采样层后,高和宽会扩大到原来的2倍,通过Concat,在深度进行拼接。预测特征图1是13*13,所以预测大目标;预测特征图2是26*26,所以预测中等目标;预测特征图3是52*52,所以预测小目标(大的特征图能够保留更多空间细节信息)。
3.目标边界框的预测
本文预测的中心点相对于网格的左上角而言。通过这些公式,将网络预测的参数(tx,ty,tw,th)转化成最终的边界框信息(bx,by,bw,bh)。其中( tx,ty )为网络预测的边界框中心偏移量,( tw,th )为宽高缩放因子。sigmoid函数其目的是将预测偏移量缩放到0到1之间(这样能够将每个Grid Cell中预测的边界框的中心坐标限制在当前cell当中,作者说这样能够加快网络收敛)。
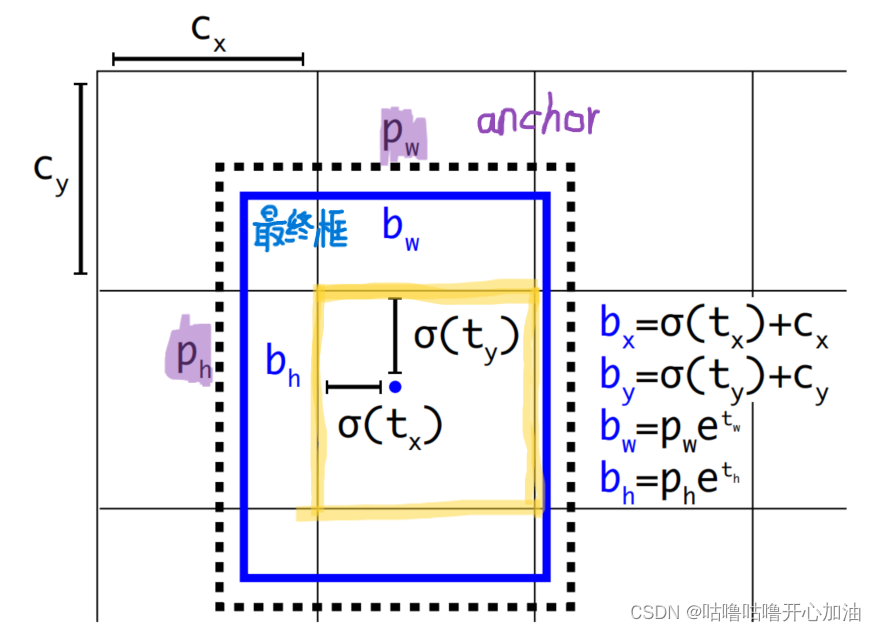
当1*1的卷积核滑到这个网格时,会针对每一个anchor模板都会预测4个回归参数,1个object参数和每个类别的分数。 相当于,YOLOv3网络在三个特征图中分别通过(4+1+c)*k个大小为1*1的卷积核进行预测,k为预设边界框(bounding box prior)的个数(在每个预测特征层中k默认取3),c为预测目标的类别数,其中4k个参数负责预测目标边界框的偏移量,k个参数负责预测目标边界框内包含目标的概率,ck个参数负责预测这k个预设边界框对应c个目标类别的概率。图中虚线矩形框为Anchor模板(这里只用看pw和ph,实线矩形框为通过网络预测的偏移量(相对Grid Cell的左上角)计算得到的预测边界框。其中(cx,cy)为网格的左上角坐标。
https://blog.csdn.net/qq_37541097/article/details/81214953
4.正负样本的匹配
在目标检测中不能将所有的预测框都进入损失函数进行计算,主要原因是框太多,参数量太大,因此需要先将正负样本选择出来,再进行损失函数的计算。训练负样本的目的是为了降低误检测率、误识别率,提高网络模型的泛化能力。通俗地讲就是告诉检测器,这些“不是你要检测的目标”。
对于每一个ground truth,会分配一个bounding box prior(正样本),也就是说,一张图片有几个目标就有几个正样本。分配的原则是bounding box和ground truth的重叠超过其他的bounding boxes,则为正样本。如果bounding box和ground truth的重叠不是最大但是超过了阈值,则丢弃这个预测。则剩下的样本为负样本。如果不是正样本,则没有定位损失和类别损失,只有置信度损失。但是这个规则去寻找正样本,正样本的数量很少,这将使得网络难以训练。作者尝试用focal loss来缓解正负样本不均匀的问题,但是并没有取得很好的效果,原因就在于负样本值参与了置信度损失,对loss的影响占比很小 。
https://www.cnblogs.com/AIBigTruth/p/16876004.html
https://blog.csdn.net/xiahan_qian/article/details/124897269
5.损失计算
(1)置信度损失
YOLOv3使用逻辑回归预测每个bounding box的目标分数。逻辑回归根据给定的自变量数据集来估计事件的发生概率,由于结果是一个概率,因此因变量的范围在 0 和 1 之间。在机器学习中,逻辑回归一般采用二元交叉熵损失,特别是在处理二分类问题时。
在二分类问题中,模型的目标是预测一个概率值,表示给定输入属于某个类别的概率。二元交叉熵损失函数测量的是模型预测的概率分布和真实标签的概率分布之间的差异。具体来说,它计算了真实标签和预测概率之间的对数差异。

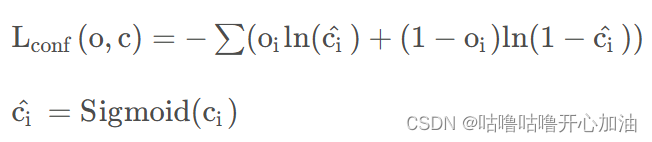
Oi表示预测目标边界框i中是否真实存在目标,正样本为1,负样本为0;Ci^表示预测目标矩形框i内是否存在目标的Sigmoid概率,即预测置信度;Ci为预测值,通过Sigmoid将其范围固定到0-1。
https://zhuanlan.zhihu.com/p/666619545
https://blog.csdn.net/xiahan_qian/article/details/124897269
(2)类别损失
同样,类别损失也是二元交叉熵损失,只考虑正样本。
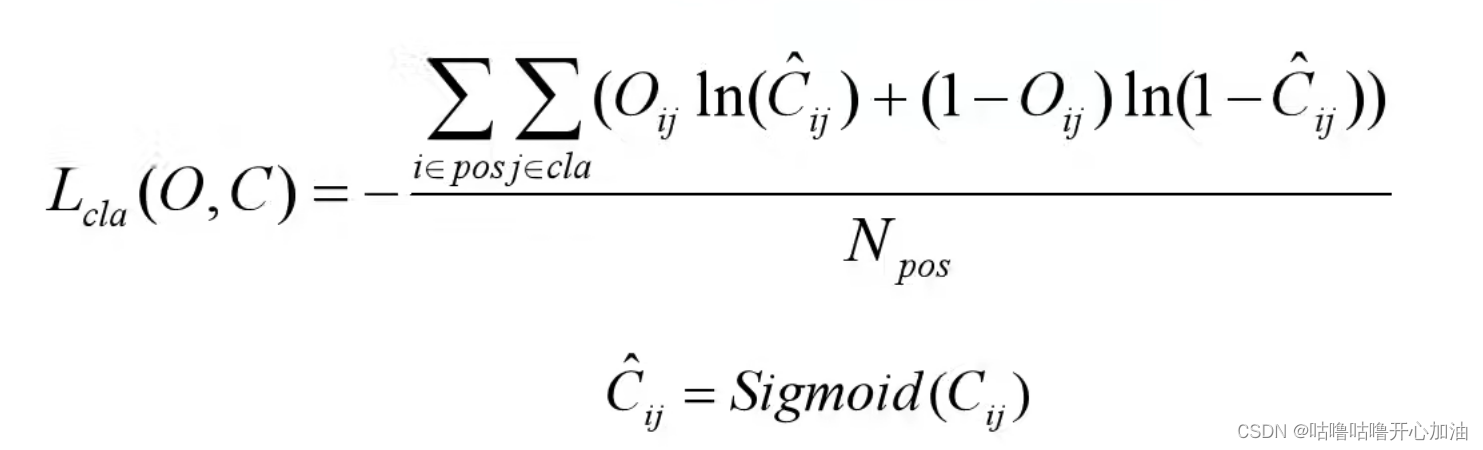
Oij表示预测目标边界框i中是否真实存在第j类目标,0表示不存在,1表示存在;Cij^表示网络预测目标边界框i内存在第j类目标的Sigmoid概率(将预测值Cij通过sigmoid函数得到)。
(3)定位损失
定位损失是Sum of Squared Error Loss,只考虑正样本。

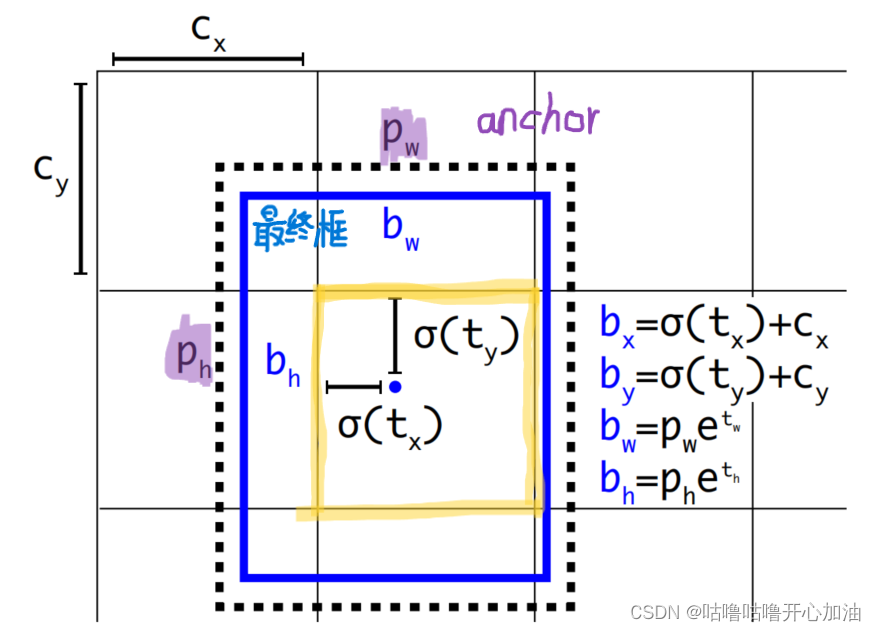
这里主要讲一下gw^是通过bw=Pwe^(tw)公式计算得到。这个损失函数只需要稍微了解即可,后面用的是新的损失函数。SSE主要是对预测所得anchor中心偏移量与宽高缩放因子进行误差分析,是对点进行回归分析。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









