







yolov3是在v2的基础上做出了进一步提升。文中不是选择以前的voc数据集,而是选择了coco数据集。coco数据集分类分为80个类
- 改进网络结构,更适合检测小目标
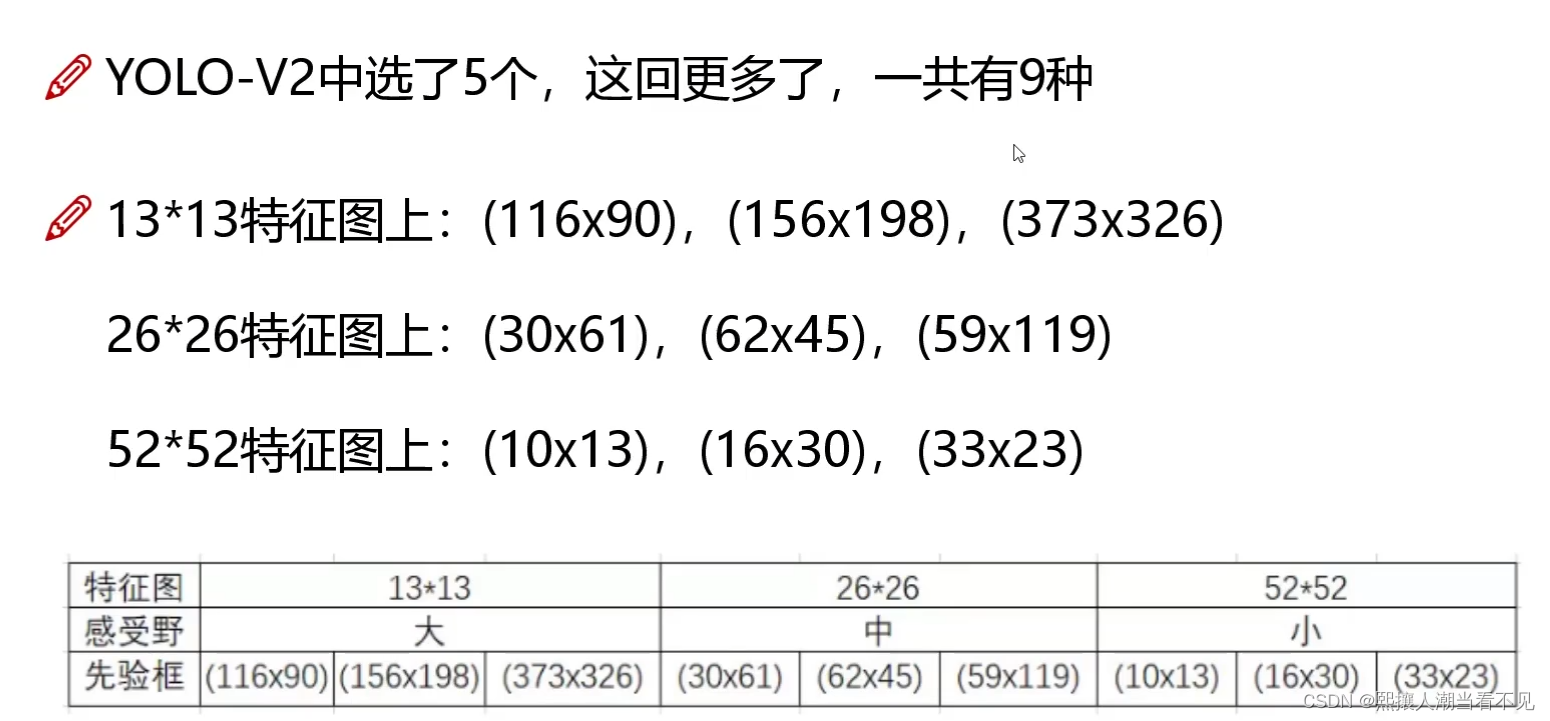
- 先验框更丰富了,有3种scal,每种3个规格,9种(v1有2种,v2有5种)
- softmax改进,预测多标签任务。一个物体打上多个标签
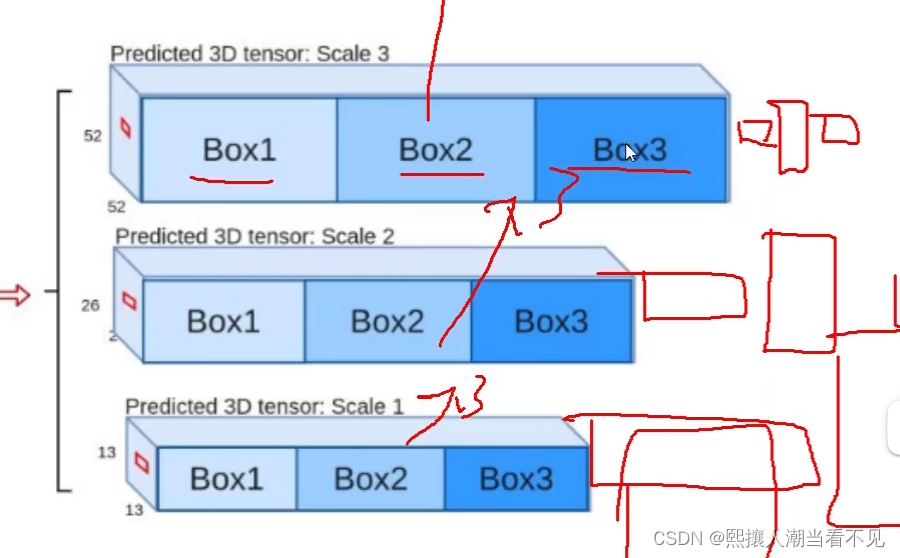
多scal
为了检测不同大小的物体,设计了3个scal的特征图。分别对大物体、中物体、小物体
v3设计了3种尺寸的特征图,每个尺寸负责预测大物体、中物体、小物体。
每个尺寸的特征图上,有3种尺寸的先验框
Q:怎么得到不同scal的特征图
1.单一的输入,经过若干层卷积,得到最终特征图。
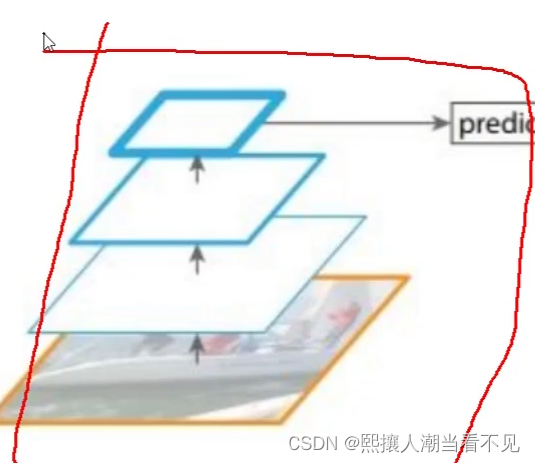
2.,多个输入,但是速度太慢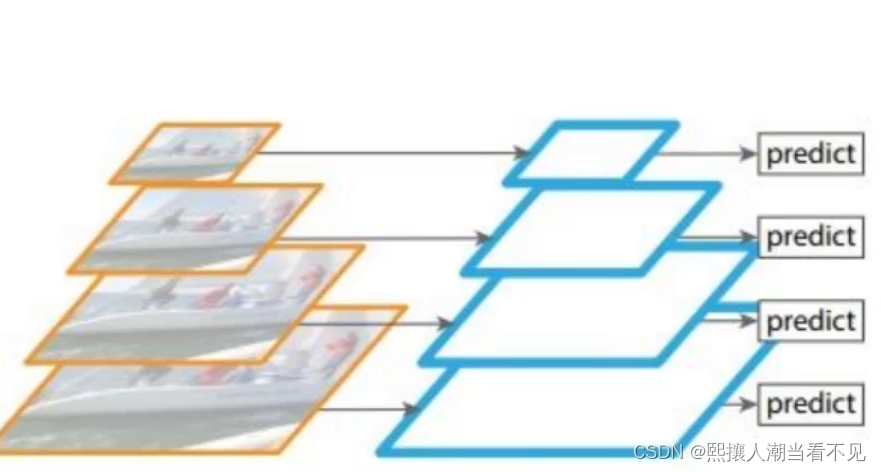
3.卷积过程对多个特征分别特征图
但是中间的层比如大尺寸和小尺寸的特征图 ,层数比较浅,所以可能不完全。因此需要和最后一层做特征融合
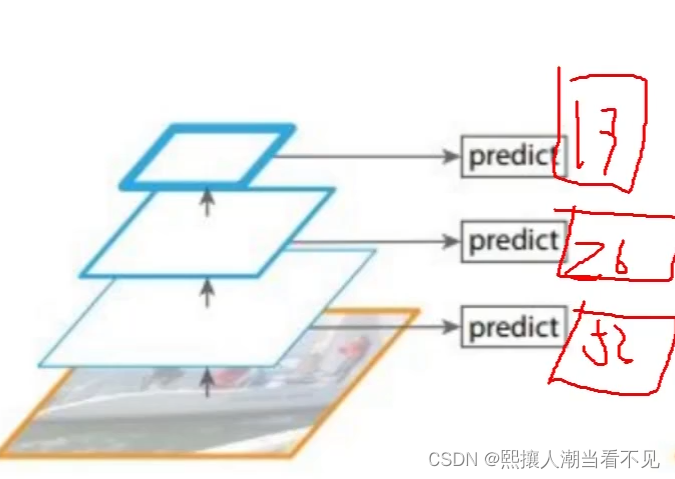
4. 特征融合预测(yoloV3选择的是这个)
13*13的是最终层,是全局性的所有特征提取的效果好。13*13的特征图检测后,进行上采样,然后与26*26的特征图进行融合。
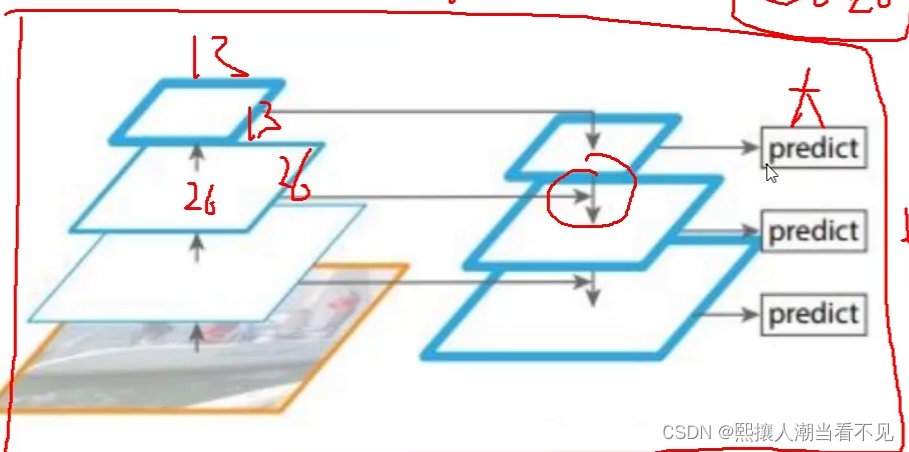
先验框
每个不同的特征图上,对应三种先验框

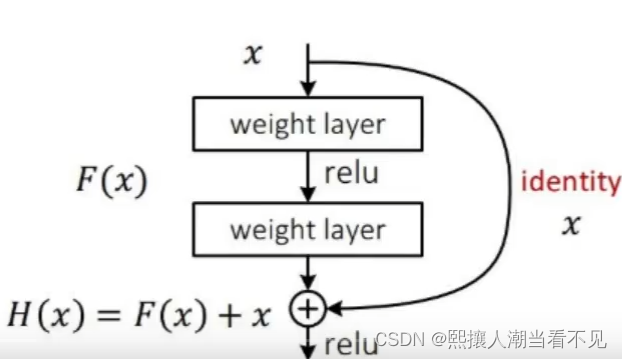
残差连接
残插连接
VGG网络发现网络层数越高效果越差(梯度消失)
在RestNet中使用了残差连接的思想。
如果19层效果好,52层差。那么中间可能出问题了,但不是所有层都有问题,因此,残差连接有个分支,让网络正常走,然后与原来求和。让网络自己选择合适路。(具体看RestNet)
softmax层替代
输出时一个目标可以有多个标签
特征提取网络
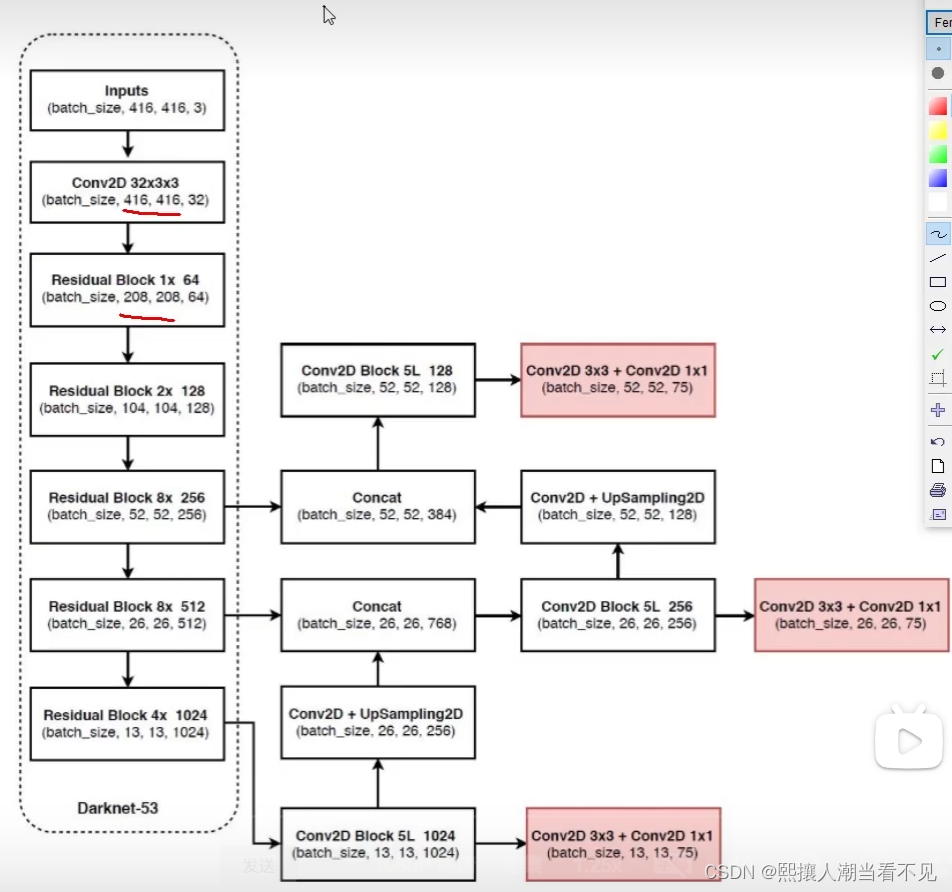
v3中把YOLOv2里面的Darknet19换成了Darknet53网络,如下图所示,53表示总共53个卷积层。
其中每一个Residual就是一个残插结构(resnet那种)。
- 没有池化层,全部卷积还有残插结构
- 下采样通过stride=2实现
- 输出有3种scal的特征图,每个scal又有3种先验框
- 最终特征图上采样与前面层进行特征融合
yolo结构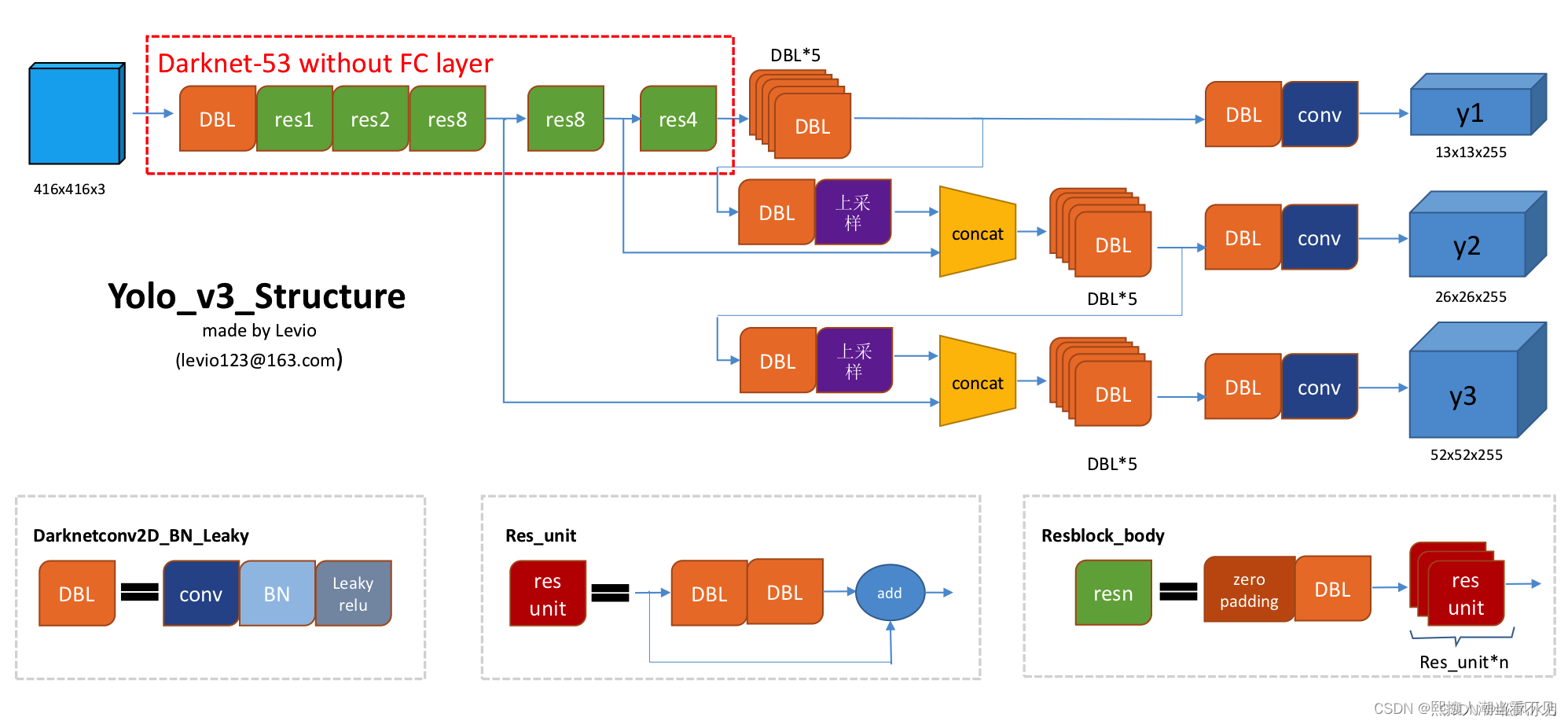
v3中使用了多尺度的一个特征提取,提取了三次特征,分别下采样了8倍,16倍和32倍,分别对应小物体、中物体和大物体的预测。
13*13*255:输出的是13*13的grid cell,每个grid cell有三个anchor ,每个anchor负责预测该cell,有4个位置参数,一个confidence,和80个类别参数。该特征层感受野大,负责预测大物体。
26*26*255:附则预测中物体。
52*52*255:负责预测小物体。
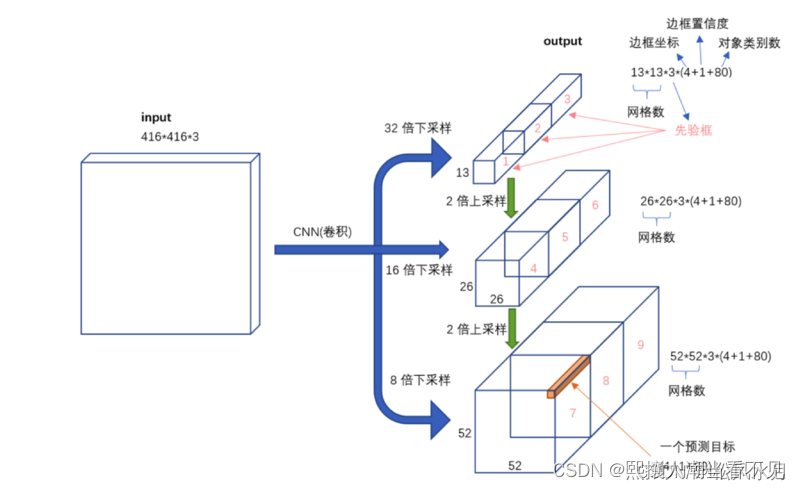















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









