







线性代数基础
- 线性方程组有解时系数矩阵可逆,反之亦然
- 范数:度量向量的大小(也可以理解成向量到零点的距离)的函数,需要满足以下三个条件:
f ( x ) = 0 → x = 0 f ( x + y ) ≤ f ( x ) + f ( y ) f ( α x ) = ∣ α ∣ f ( x ) , ∀ α ∈ R f(x)=0\to x=0\\ f(x+y)\leq f(x)+f(y)\\ f(\alpha x)=\vert\alpha\vert f(x),\forall \alpha\in \mathbb R f(x)=0→x=0f(x+y)≤f(x)+f(y)f(αx)=∣α∣f(x),∀α∈R - p范数 L p ( x ) = ∥ x ∥ p = ( ∑ i ∣ x i ∣ p ) 1 p L^p(x)=\Vert x\Vert_p=(\sum_i |x_i|^p)^\frac1p Lp(x)=∥x∥p=(∑i∣xi∣p)p1
- 无穷范数 L ∞ ( x ) = ∥ x ∥ ∞ = max i ∣ x i ∣ L^\infty(x)=\Vert x\Vert_\infty=\max_i |x_i| L∞(x)=∥x∥∞=maxi∣xi∣
- 正交矩阵: A T = A − 1 A^T=A^{-1} AT=A−1
- 每个实对称矩阵都可实正交分解
- 奇异值分解: A = U D V T A=UDV^T A=UDVT
- 穆尔-彭罗斯广义逆矩阵:对m
×
\times
×n阶矩阵A,存在唯一n
×
\times
×m阶矩阵X满足以下四个条件:
A X A = A X A X = X ( A X ) ∗ = X A ( X A ) ∗ = A X AXA=A\\ XAX=X\\ (AX)^*=XA\\ (XA)^*=AX AXA=AXAX=X(AX)∗=XA(XA)∗=AX
概率论基础
- 方差: Var [ f ( x ) ] = E [ ( f ( x ) − E [ f ( x ) ] ) 2 ] \text{Var}[f(x)]=\mathbb E[(f(x)-\mathbb E[f(x)])^2] Var[f(x)]=E[(f(x)−E[f(x)])2]
- 协方差: Cov [ f ( x ) , g ( y ) ] = E [ ( f ( x ) − E [ f ( x ) ] ) ( g ( y ) − E [ g ( y ) ] ) ] \text{Cov}[f(x),g(y)]=\mathbb E[(f(x)-\mathbb E[f(x)])(g(y)-\mathbb E[g(y)])] Cov[f(x),g(y)]=E[(f(x)−E[f(x)])(g(y)−E[g(y)])]
- 高斯分布: N ( x ; μ , σ 2 ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) N(x;\mu,\sigma^2)=\sqrt{\frac1{2\pi\sigma^2}}\exp\big(-\frac{(x-\mu)^2}{2\sigma^2}\big) N(x;μ,σ2)=2πσ21exp(−2σ2(x−μ)2)
- 多元高斯分布: N ( x ; μ , Σ ) = 1 ( 2 π ) n det ( Σ ) exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) N(x;\mu,\Sigma)=\sqrt{\frac1{(2\pi)^n\det(\Sigma)}}\exp\big(-\frac12(x-\mu)^T\Sigma^{-1}(x-\mu)\big) N(x;μ,Σ)=(2π)ndet(Σ)1exp(−21(x−μ)TΣ−1(x−μ))
- 狄拉克函数:
δ ( x ) = 0 ( x ≠ 0 ) ∫ − ∞ + ∞ δ ( x ) d x = 1 \delta(x)=0(x\neq0)\\ \int_{-\infty}^{+\infty}\delta(x)\text d x=1 δ(x)=0(x=0)∫−∞+∞δ(x)dx=1 - 经验分布(Empirical ): f ( x ) = 1 m ∑ i = 1 m δ ( x − x i ) f(x)=\frac1m\sum_{i=1}^m\delta(x-x_i) f(x)=m1∑i=1mδ(x−xi)
- 拉普拉斯分布:
f ( x ; μ , b ) = 1 2 b exp ( − b ∣ x − μ ∣ ) f(x;\mu, b)=\frac1{2b}\exp(-\frac b{|x-\mu|}) f(x;μ,b)=2b1exp(−∣x−μ∣b)
信息论基础
- 自信息: I ( x ) = − log P ( x ) I(x)=-\log P(x) I(x)=−logP(x)
- 信息熵:度量事件的期望信息 H ( x ) = − ∑ i P ( x i ) log P ( x i ) H(x)=-\sum_iP(x_i)\log P(x_i) H(x)=−∑iP(xi)logP(xi)
- KL散度:度量两个分布间的差异(非对称): D K L ( p ∣ ∣ q ) = ∑ i p ( x i ) [ log p ( x i ) − log q ( x i ) ] D_{KL}(p||q)=\sum_ip(x_i)[\log p(x_i)-\log q(x_i)] DKL(p∣∣q)=∑ip(xi)[logp(xi)−logq(xi)]
优化理论基础
- 梯度下降:梯度方向是最快下降方向,但不知道步长
- 鞍点:梯度为零但不是极值点的点
常用函数
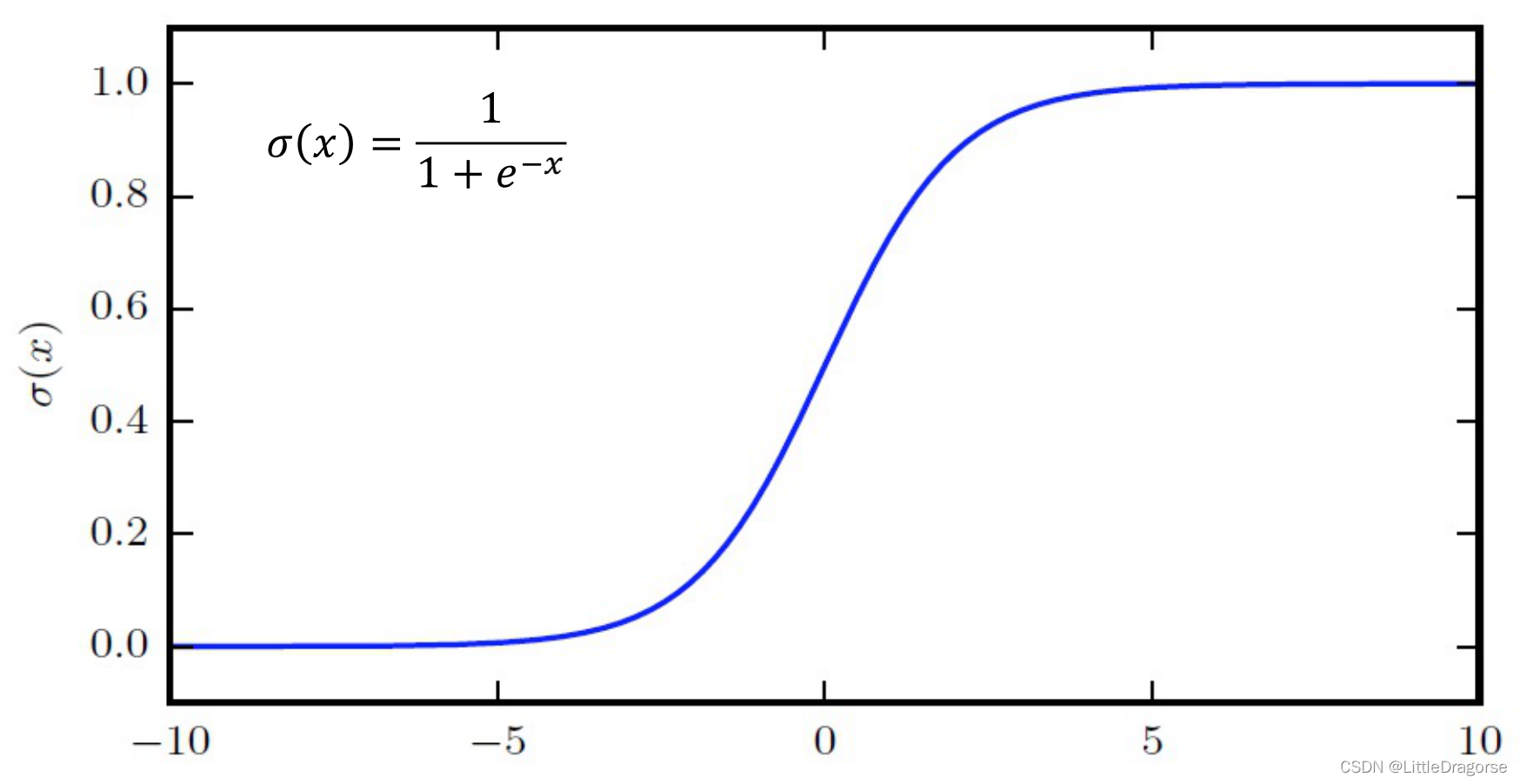
- logistic sigmoid:
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac1{1+e^{-x}}
σ(x)=1+e−x1
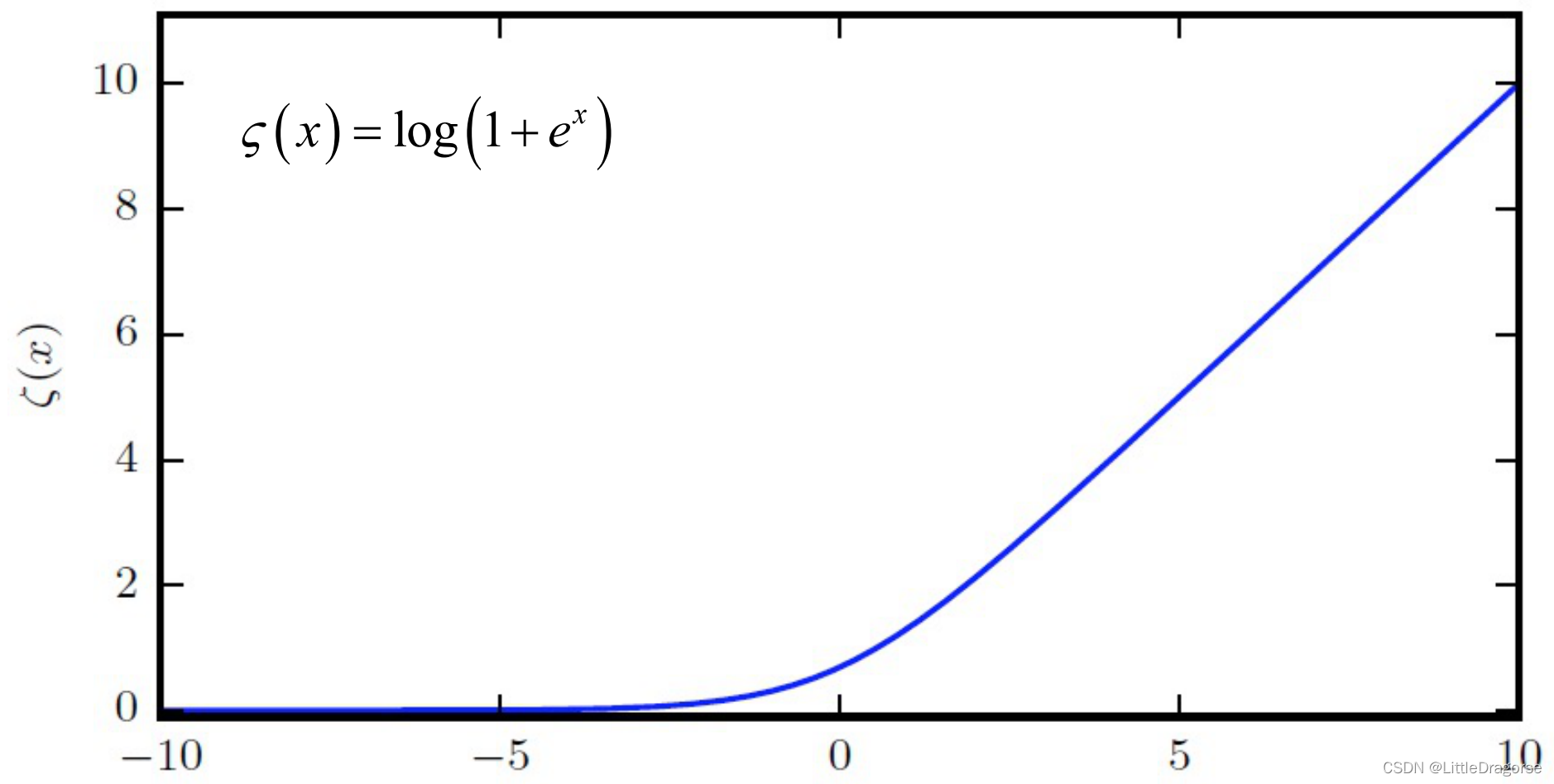
- softplus:
ς
(
x
)
=
log
(
1
+
e
x
)
\varsigma(x)=\log(1+e^x)
ς(x)=log(1+ex)
深度学习分类
- 有监督、无监督、半监督
- 分类、回归
- 判别、生成
损失函数
- 均方误差:常用于回归,公式: MSE = 1 N ∑ i ( f ( x i ) − y i ) 2 \text{MSE}=\frac1N\sum_i(f(x_i)-y_i)^2 MSE=N1∑i(f(xi)−yi)2
- 交叉熵损失:常用于分类,公式: CE = 1 N ∑ i log P ( Y = y i ∣ x i ) \text{CE}=\frac1N\sum_i\log P(Y=y_i|x_i) CE=N1∑ilogP(Y=yi∣xi)
泛化与鲁棒
泛化性
- 假设所有样本符合分布 p ( x , y ) p(x,y) p(x,y),则泛化误差 GE = ∫ x , y p ( x , y ) Error ( f ( x ) , y ) \text{GE}=\int_{x,y}p(x,y)\text{Error}(f(x),y) GE=∫x,yp(x,y)Error(f(x),y)
- 在分布未知时使用测试集来评估泛化性能: Performance = 1 M ∑ i Error ( f ( x i ) , y i ) \text{Performance}=\frac1M\sum_i\text{Error}(f(x_i),y_i) Performance=M1∑iError(f(xi),yi)
容量
- 泛化误差是容量的U型函数
如何确定线性层层数
没有隐藏层:仅能够表示线性可分函数或决策
隐藏层数=1:可以拟合任何“包含从一个有限空间到另一个有限空间的连续映射”的函数
隐藏层数=2:搭配适当的激活函数可以表示任意精度的任意决策边界,并且可以拟合任何精度的任何平滑映射
隐藏层数>2:多出来的隐藏层可以学习复杂的描述(某种自动特征工程)
如何确定单层神经元个数
经验公式
N
h
=
N
s
α
(
N
o
+
N
i
)
N_h=\frac{N_s}{\alpha(N_o+N_i)}
Nh=α(No+Ni)Ns
其中
N
i
N_i
Ni是输入向量长度;
N
o
N_o
No是输出层神经元个数;
N
s
N_s
Ns是训练集的样本数;
α
\alpha
α是可以范围在[2,10]之间的常数。
经验准则
- 隐藏神经元的数量应在输入层的大小和输出层的大小之间。
- 隐藏神经元的数量应为输入层大小的2/3加上输出层大小的2/3。
- 隐藏神经元的数量应小于输入层大小的两倍。
欠拟合
- 模型不够复杂
- 训练轮次不够
过拟合
- 模型相对于样本量而言容量过大
正则化
通过对复杂模型添加惩罚项来防止过拟合,相当于在可以作为学习器解决方案的函数集上施加优先级
Dropout
dropout是一种训练时技术,通过让一部分神经元不参加训练输出来提高模型的鲁棒性。关于其效果的解释众说纷纭,
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
避免维数灾难
- PCA降维:前t大特征值对应的特征向量是样本的主成分
深度学习模块
全连接
卷积
局部连接、权值共享、多个滤波器、池化
循环
用于建模前向长距离上下文关系
LSTM
注意力
深度学习任务方向
视觉领域(CV)
视觉领域大型数据集
- ImageNet
- COCO
- YouTube 8M
典型任务
- 物体检测/分割
- 物体识别/检索
- 运动行为/分析
- 场景理解 视觉+语言
- 视频分类
- 行为识别
- 姿态估计
- 视觉跟踪
- 视频注释生成
- 行人再识别
- 人脸识别
- 虹膜识别
- 步态识别
- 语义分割
- 视频超分辨率
自然语言领域(NLP)
未来方向
- 大规模深度学习
- 多GPU学习
- 分布式系统
- AI for science
- 多模态学习
- 脑启发的深度模型















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









