






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
前言
本文将采用VGG16网络实现咖啡豆识别。简单讲述实现代码与执行结果,并浅谈涉及知识点。
关键字:VGG16详解、模型轻量化-全局平均池化层代替全连接层、Batch Normalization详解。
一、我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm
- 深度学习环境:TensorFlow 2.10.1
- 显卡:NVIDIA GeForce RTX 4070
二、代码实现与执行结果
1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import tensorflow as tf
from tensorflow.keras import datasets, layers, models, regularizers
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, BatchNormalization
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.设置GPU(如果使用的是CPU可以忽略这步)
''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
本人电脑前期无独显,故该步骤被注释,未执行,后觉得没有GPU加速实在太慢,新增显卡,则取消注释。
3.导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\CoffeeBean"
data_dir = Path(data_dir)
4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.png')))
print("图片总数为:", image_count)
image_list = list(data_dir.glob('Green/*.png'))
image = Image.open(str(image_list[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.show()
执行结果:
图片总数为: 1200
PNG (224, 224) RGB
5.加载数据
'''数据预处理-加载数据'''
batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 1200 files belonging to 4 classes.
Using 960 files for training.
Found 1200 files belonging to 4 classes.
Using 240 files for validation.
['Dark', 'Green', 'Light', 'Medium']
6.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(25, 20))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 4, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]], fontsize=40)
plt.axis("off")
# 显示图片
plt.show()

7.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(32,180,180,3)。这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(32,)的张量,这些标签对应32张图片
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
运行结果
(32, 224, 224, 3)
(32,)
8.配置数据集
本人电脑无GPU加速,故并未起到加速作用
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
# shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
# prefetch():预取数据,加速运行
# cache():将数据集缓存到内存当中,加速运行
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
# 查看归一化后的数据
print(np.min(first_image), np.max(first_image))
运行结果
0.0 1.0
本人电脑不带GPU,故prefetch无效
9.构建CNN网络模型
'''构建CNN网络'''
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(len(class_names), (img_width, img_height, 3))
model.summary()
网络结构结果如下:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 4) 16388
=================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
10.编译模型
'''编译模型'''
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
11.训练模型
'''训练模型'''
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
训练记录如下:
Epoch 1/20
30/30 [==============================] - 267s 9s/step - loss: 1.3496 - accuracy: 0.2573 - val_loss: 1.1989 - val_accuracy: 0.5708
Epoch 2/20
30/30 [==============================] - 282s 9s/step - loss: 0.8790 - accuracy: 0.5396 - val_loss: 0.6942 - val_accuracy: 0.5875
Epoch 3/20
30/30 [==============================] - 282s 9s/step - loss: 0.6644 - accuracy: 0.6521 - val_loss: 0.6914 - val_accuracy: 0.6208
Epoch 4/20
30/30 [==============================] - 282s 9s/step - loss: 0.6401 - accuracy: 0.6917 - val_loss: 0.4857 - val_accuracy: 0.8167
Epoch 5/20
30/30 [==============================] - 283s 9s/step - loss: 0.5974 - accuracy: 0.7000 - val_loss: 0.4269 - val_accuracy: 0.8417
Epoch 6/20
30/30 [==============================] - 284s 9s/step - loss: 0.4448 - accuracy: 0.8021 - val_loss: 0.4033 - val_accuracy: 0.8333
Epoch 7/20
30/30 [==============================] - 283s 9s/step - loss: 0.3612 - accuracy: 0.8604 - val_loss: 0.3296 - val_accuracy: 0.8500
Epoch 8/20
30/30 [==============================] - 282s 9s/step - loss: 0.3452 - accuracy: 0.8396 - val_loss: 0.2594 - val_accuracy: 0.9042
Epoch 9/20
30/30 [==============================] - 281s 9s/step - loss: 0.1486 - accuracy: 0.9438 - val_loss: 0.1974 - val_accuracy: 0.9375
Epoch 10/20
30/30 [==============================] - 283s 9s/step - loss: 0.1229 - accuracy: 0.9563 - val_loss: 0.1365 - val_accuracy: 0.9417
Epoch 11/20
30/30 [==============================] - 281s 9s/step - loss: 0.0952 - accuracy: 0.9625 - val_loss: 0.1694 - val_accuracy: 0.9250
Epoch 12/20
30/30 [==============================] - 281s 9s/step - loss: 0.0992 - accuracy: 0.9667 - val_loss: 0.1305 - val_accuracy: 0.9542
Epoch 13/20
30/30 [==============================] - 282s 9s/step - loss: 0.1078 - accuracy: 0.9625 - val_loss: 0.2315 - val_accuracy: 0.9208
Epoch 14/20
30/30 [==============================] - 281s 9s/step - loss: 0.0620 - accuracy: 0.9802 - val_loss: 0.0593 - val_accuracy: 0.9792
Epoch 15/20
30/30 [==============================] - 280s 9s/step - loss: 0.0193 - accuracy: 0.9927 - val_loss: 0.0631 - val_accuracy: 0.9792
Epoch 16/20
30/30 [==============================] - 281s 9s/step - loss: 0.0380 - accuracy: 0.9875 - val_loss: 0.1255 - val_accuracy: 0.9625
Epoch 17/20
30/30 [==============================] - 281s 9s/step - loss: 0.0151 - accuracy: 0.9937 - val_loss: 0.0493 - val_accuracy: 0.9875
Epoch 18/20
30/30 [==============================] - 280s 9s/step - loss: 0.0084 - accuracy: 0.9979 - val_loss: 0.0912 - val_accuracy: 0.9750
Epoch 19/20
30/30 [==============================] - 293s 10s/step - loss: 0.0274 - accuracy: 0.9896 - val_loss: 0.0824 - val_accuracy: 0.9667
Epoch 20/20
30/30 [==============================] - 390s 13s/step - loss: 0.0210 - accuracy: 0.9917 - val_loss: 0.0904 - val_accuracy: 0.9750
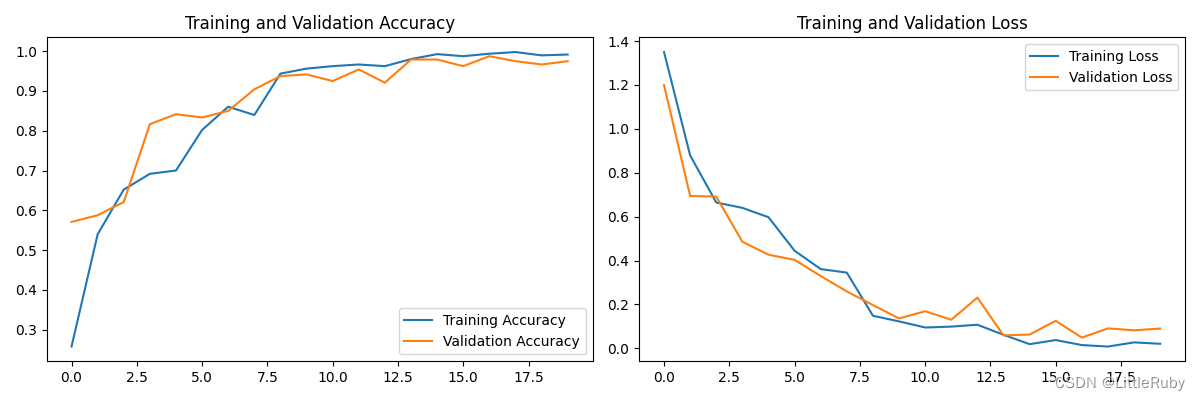
最好效果为loss: 0.0151 - accuracy: 0.9937 - val_loss: 0.0493 - val_accuracy: 0.9875
12.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
执行结果
三、知识点详解
1.VGG16详解
VGG优缺点分析:
● VGG优点
VGG的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
● VGG缺点
1)训练时间过长,调参难度大。2)需要的存储容量大,不利于部署。例如存储VGG-16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
1. 1 VGG16官方模型
官网模型调用:
def keras_vgg16(class_names, img_height, img_width):
model = tf.keras.applications.VGG16(
include_top=True,
weights=None,
input_tensor=None,
input_shape=(img_height, img_width, 3),
pooling=max,
classes=len(class_names),
classifier_activation="softmax",
)
return model
model = keras_vgg16(class_names, img_height, img_width)
model.summary()
或者
model = tf.keras.applications.VGG16(weights='imagenet')
model.summary()
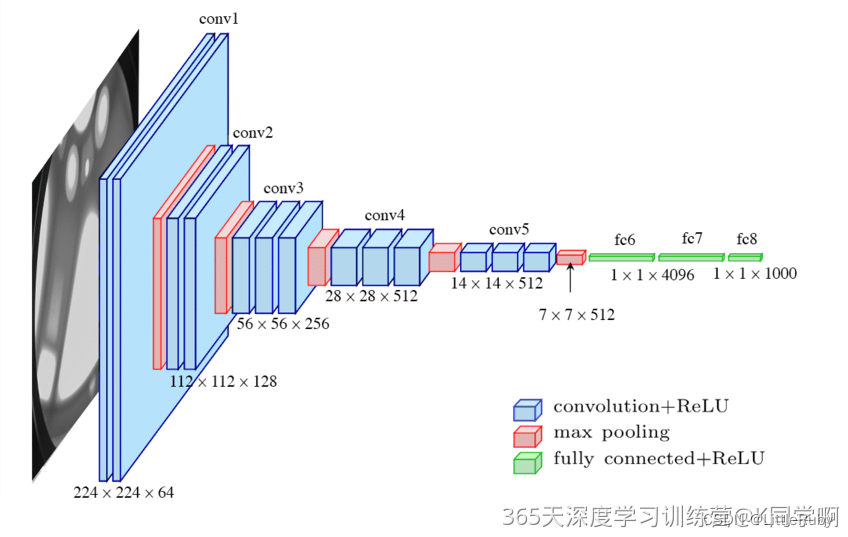
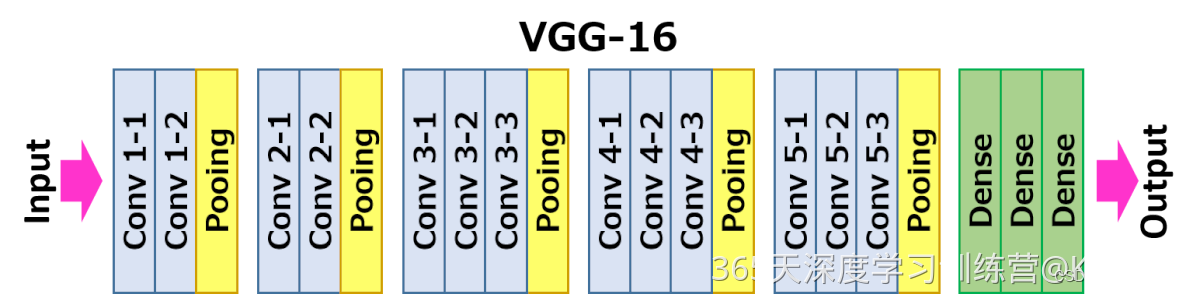
1. 2 VGG16 网络结构图
结构说明:
● 13个卷积层(Convolutional Layer),分别用blockX_convX表示
● 3个全连接层(Fully connected Layer),分别用fcX与predictions表示
● 5个池化层(Pool layer),分别用blockX_pool表示
VGG-16包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
1.3 保存最好参数模型+设置早停+动态设置学习率
'''编译模型'''
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 设置优化器
# opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
# model.compile(optimizer=opt,
# loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# metrics=['accuracy'])
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
'''训练模型'''
epochs = 50
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=10,
verbose=1)
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])
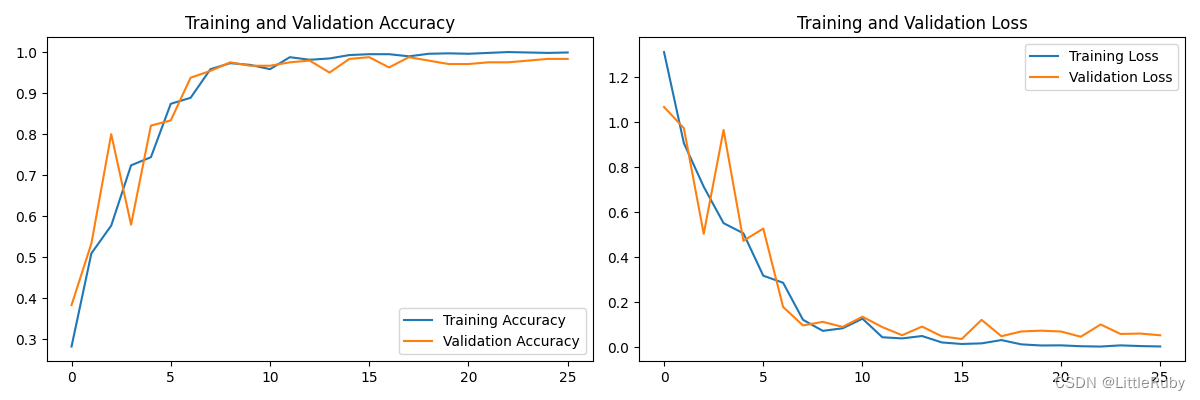
训练结果:
Epoch 1/50
30/30 [==============================] - ETA: 0s - loss: 1.3116 - accuracy: 0.2823
Epoch 1: val_accuracy improved from -inf to 0.38333, saving model to best_model.h5
30/30 [==============================] - 291s 10s/step - loss: 1.3116 - accuracy: 0.2823 - val_loss: 1.0678 - val_accuracy: 0.3833
Epoch 2/50
30/30 [==============================] - ETA: 0s - loss: 0.9069 - accuracy: 0.5094
Epoch 2: val_accuracy improved from 0.38333 to 0.53333, saving model to best_model.h5
30/30 [==============================] - 426s 14s/step - loss: 0.9069 - accuracy: 0.5094 - val_loss: 0.9735 - val_accuracy: 0.5333
......
Epoch 26: val_accuracy did not improve from 0.98750
30/30 [==============================] - 352s 12s/step - loss: 0.0037 - accuracy: 0.9990 - val_loss: 0.0536 - val_accuracy: 0.9833
Epoch 26: early stopping
最好效果为loss: 0.0148 - accuracy: 0.9948 - val_loss: 0.0370 - val_accuracy: 0.9875
从acc曲线图看,设置动态学习率可以更快的收敛。
2.模型轻量化-全局平均池化层代替全连接层
全连接存在的问题:参数量过大,降低了训练的速度,且很容易过拟合
全连接层将卷积层展开成向量之后不还是要针对每个feature map进行分类,而GAP的思路就是将上述两个过程合二为一,一起做了。
如图所示:
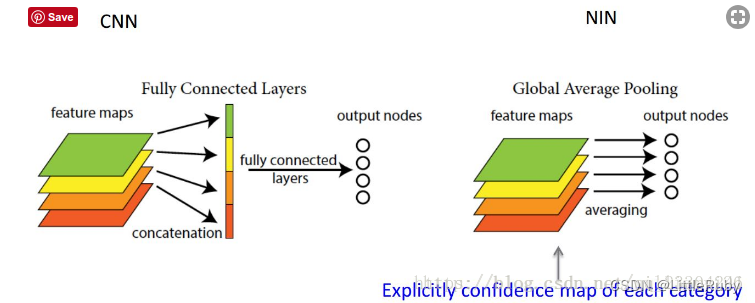
GAP替换掉密集的全连接层即卷积层+全局平均池化代替卷积层+全连接层,极大的减少了网络的参数量,减小模型大小,相当于在网络结构上做正则,防止模型发生过拟合。
CNN+FC结构的模型,对于训练过程而言,整个模型的学习压力主要集中在FC层(FC层的参数量占整个模型参数量的80%),此时CNN层学习到的特征更倾向于低层的通用特征,即使CNN层学习到的特征比较低级,强大的FC层也可以通过学习调整参数做到很好的分类
CNN+GAP结构的模型,因为使用GAP代替了FC,模型的参数量骤减,此时模型的学习压力全部前导到CNN层,相比于CNN+FC层,此时的CNN层不仅仅需要学习到低层的通用特征,还要学习到更加高级的分类特征,学习难度变大,网络收敛变慢
def VGG16_GAP(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# 2nd block
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# 3rd block
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# 4th block
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# 5th block
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
# GAP
x = layers.GlobalAveragePooling2D()(x) # GAP层
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x) # 输出层
model = Model(input_tensor, output_tensor)
return model
model = VGG16_GAP(len(class_names), (img_width, img_height, 3))
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
global_average_pooling2d (G (None, 512) 0
lobalAveragePooling2D)
predictions (Dense) (None, 4) 2052
=================================================================
Total params: 14,716,740
Trainable params: 14,716,740
Non-trainable params: 0
_________________________________________________________________
全局平均池化层代替全连接层后参数量由134,276,932降至14,716,740
训练结果:
Epoch 1/50
30/30 [==============================] - ETA: 0s - loss: 1.3810 - accuracy: 0.2531
Epoch 1: val_accuracy improved from -inf to 0.22083, saving model to best_model.h5
30/30 [==============================] - 312s 11s/step - loss: 1.3810 - accuracy: 0.2531 - val_loss: 1.3408 - val_accuracy: 0.2208
Epoch 2/50
30/30 [==============================] - ETA: 0s - loss: 1.1375 - accuracy: 0.4208
Epoch 2: val_accuracy improved from 0.22083 to 0.44583, saving model to best_model.h5
30/30 [==============================] - 392s 13s/step - loss: 1.1375 - accuracy: 0.4208 - val_loss: 1.1361 - val_accuracy: 0.4458
......
Epoch 31/50
30/30 [==============================] - ETA: 0s - loss: 0.0242 - accuracy: 0.9958
Epoch 31: val_accuracy did not improve from 0.99167
30/30 [==============================] - 395s 13s/step - loss: 0.0242 - accuracy: 0.9958 - val_loss: 0.0421 - val_accuracy: 0.9875
Epoch 31: early stopping
最好效果为loss: loss: 0.0578 - accuracy: 0.9792 - val_loss: 0.0394 - val_accuracy: 0.9917
acc和loss图
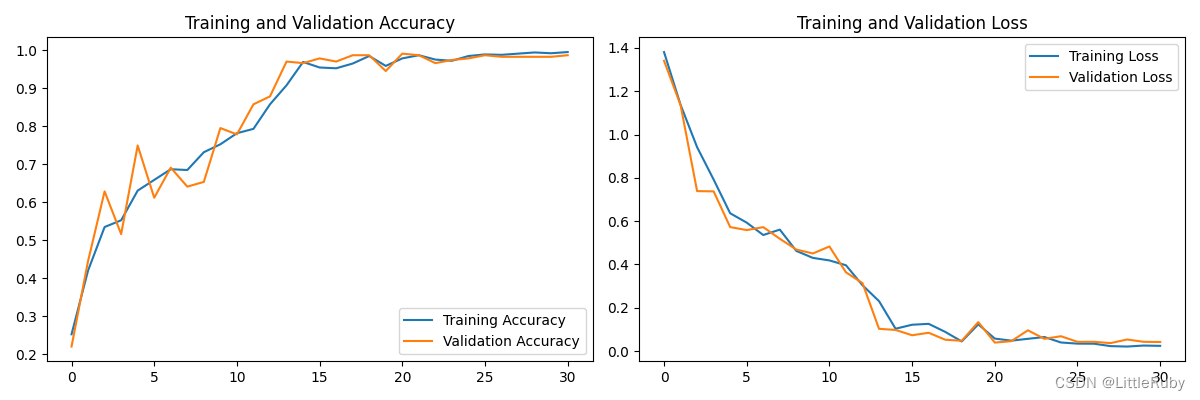
从acc曲线图看,既减少参数,识别率还有所提升。
3 Batch Normalization详解
Batch Normalization(BN),该方法对每个mini-batch都进行normalize,会把mini-batch中的数据正规化到均值为0,标准差为1,同时还引入了两个可以学的参数,分别为scale和shift,让模型学习其适合的分布。scale和shift是模型自动学习的,神经网络可以自己琢磨前面的正规化有没有起到优化作用,没有的话就"反"正规化,抵消之前的正规化操作带来的影响。
3.1 Batch Normalization作用
(1) 可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失
拿sigmoid激活函数距离,从图中,我们很容易知道,数据值越靠近0梯度越大,越远离0梯度越接近0,我们通过BN改变数据分布到0附近,从而解决梯度消失问题。
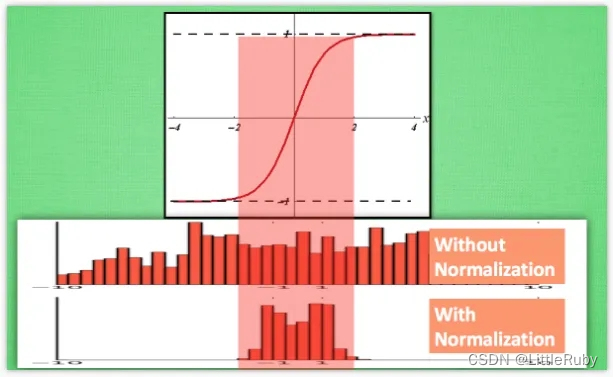
(2)解决了Internal Covariate Shift(ICS)问题
由于训练过程中参数的变化,导致各层数据分布变化较大,神经网络就要学习新的分布,随着层数的加深,学习过程就变的愈加困难,要解决这个问题需要使用较低的学习率,由此又产生收敛速度慢,因此引入BN可以很有效的解决这个问题。
(3)加速了模型的收敛
和对原始特征做归一化类似,BN使得每一维数据对结果的影响是相同的,由此就能加速模型的收敛速度。
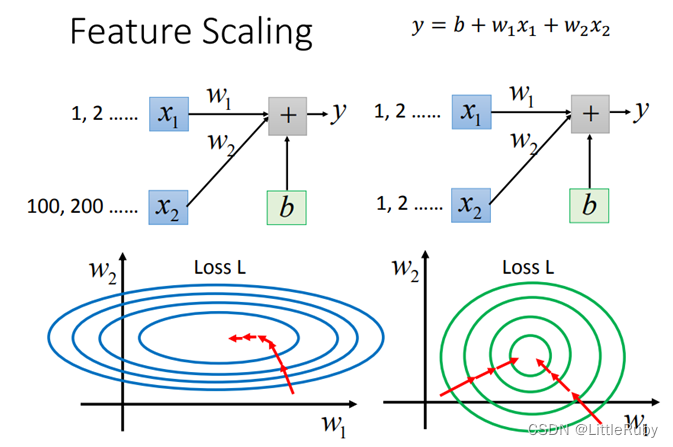
(4)具有正则化效果
BN层和正规化/归一化不同,BN层是在mini-batch中计算均值方差,因此会带来一些较小的噪声,在神经网络中添加随机噪声可以带来正则化的效果。
tips
Batch Normalization作用总结
(1)将输入神经网络的数据先对其做平移和伸缩变换,将数据分布规范化成在固定区间范围的标准分布
(2)可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失
(3)并且起到一定的正则化作用,几乎代替了Dropout。控制过拟合,可以少用或不用Dropout和正则
(4)降低网络对初始化权重不敏感
(5)允许使用较大的学习率
3.3 Batch Normalization放在哪个位置
在CNN中一般应作用与非线性激活函数之前,但是,实际上放在激活函数之后效果可能会更好。
BN消除了对dropout的依赖,因为BN也有和dropout本质一样的正则化的效果,像是ResNet, DenseNet等等并没有使用dropout,如果要用并用BN和dropout,还是建议BN放在dropout之前。
# 放在非线性激活函数之前
model.add(tf.keras.layers.Conv2D(64, (3, 3)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Activation('relu'))
# 放在激活函数之后
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
3.3 增加Batch Normalization的网络模型
# 模型轻量化-全局平均池化层代替全连接层+BN
def VGG16_BN_GAP(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# 2nd block
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# 3rd block
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# 4th block
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# 5th block
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
# GAP
x = layers.GlobalAveragePooling2D()(x) # GAP层
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x) # 输出层
model = Model(input_tensor, output_tensor)
return model
model = VGG16_BN_GAP(len(class_names), (img_width, img_height, 3))
model.summary()
模型结构
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
batch_normalization (BatchN (None, 224, 224, 64) 256
ormalization)
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
batch_normalization_1 (Batc (None, 112, 112, 128) 512
hNormalization)
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
batch_normalization_2 (Batc (None, 56, 56, 256) 1024
hNormalization)
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
batch_normalization_3 (Batc (None, 28, 28, 512) 2048
hNormalization)
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
batch_normalization_4 (Batc (None, 14, 14, 512) 2048
hNormalization)
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
global_average_pooling2d (G (None, 512) 0
lobalAveragePooling2D)
predictions (Dense) (None, 4) 2052
=================================================================
Total params: 14,722,628
Trainable params: 14,719,684
Non-trainable params: 2,944
_________________________________________________________________
训练结果:
Epoch 1/50
30/30 [==============================] - ETA: 0s - loss: 0.2237 - accuracy: 0.9083
Epoch 1: val_accuracy improved from -inf to 0.32083, saving model to best_model.h5
30/30 [==============================] - 321s 11s/step - loss: 0.2237 - accuracy: 0.9083 - val_loss: 1.6336 - val_accuracy: 0.3208
Epoch 2/50
30/30 [==============================] - ETA: 0s - loss: 0.0717 - accuracy: 0.9760
Epoch 2: val_accuracy did not improve from 0.32083
......
Epoch 11/50
30/30 [==============================] - ETA: 0s - loss: 4.2546e-04 - accuracy: 1.0000
Epoch 11: val_accuracy did not improve from 0.32083
30/30 [==============================] - 274s 9s/step - loss: 4.2546e-04 - accuracy: 1.0000 - val_loss: 8.0358 - val_accuracy: 0.3208
Epoch 11: early stopping
最好效果为loss: 0.0148 - accuracy: 0.9948 - val_loss: 0.0370 - val_accuracy: 0.9875
acc和loss图
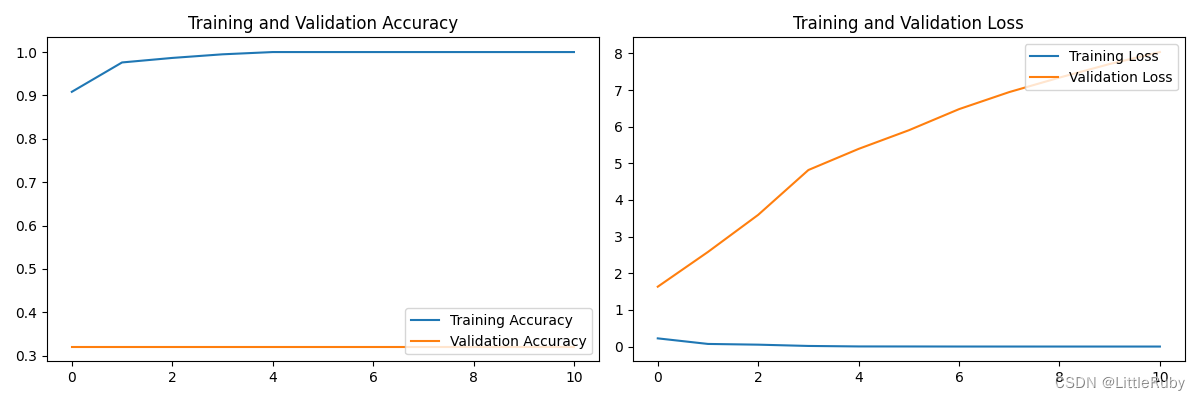
增大初始学习率initial_learning_rate = 0.01后,最好效果为loss: 0.0077 - accuracy: 1.0000 - val_loss: 0.0293 - val_accuracy: 0.9917
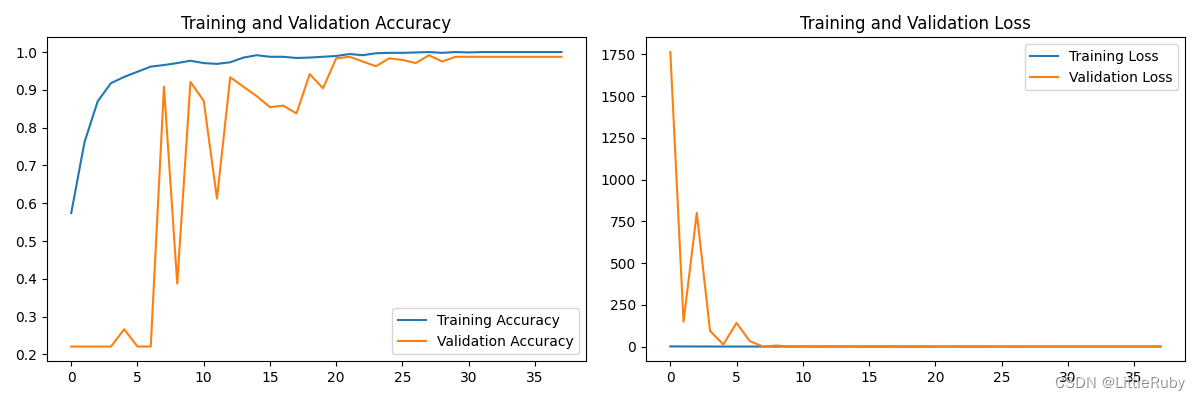
从结果看,增加BN层后,怎个网络不一定变好,因为BN层主要作用是解决过拟合的,而本文这个并未过拟合现象发生,因此慎用BN层。
总结
通过本次的学习,能通过tenserflow框架创建cnn网络模型进行猴痘病识别,学习本章节时设置保存权重可以便于查看模型效果最好时候的信息,尽管增加BN层有很多好处,但是他主要用于解决过拟合情况,在未发生过拟合的网络下增加BN层可能还有反效果。















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









