






1.安装motmetrics
使用命令pip install motmetrics安装,如果安装不上,可以进入其网址直接下载轮子安装https://pypi.org/project/motmetrics/。
也可下载github代码后,通过setup.py安装。github代码py-motmetrics。
setup.py安装命令如下:
#打开cmd,到达安装目录,执行安装
python setup.py build
python setup.py install
2.评估算法调用
2.1准备测试数据
创建一个测试数据存放的文件夹,我的文件夹为py_motmetrics/yourdata,gt数据与测试数据存放目录结构为
gtfiles = ['yourdata/test1/gt/gt.txt',
'yourdata/test2/gt/gt.txt',]
tsfiles = ['yourdata/test1.txt',
'yourdata/test2.txt',]
数据存储格式参考MOT16,评价指标说明参考详解MOT多目标跟踪评价指标及计算代码。
官方给出的评价为
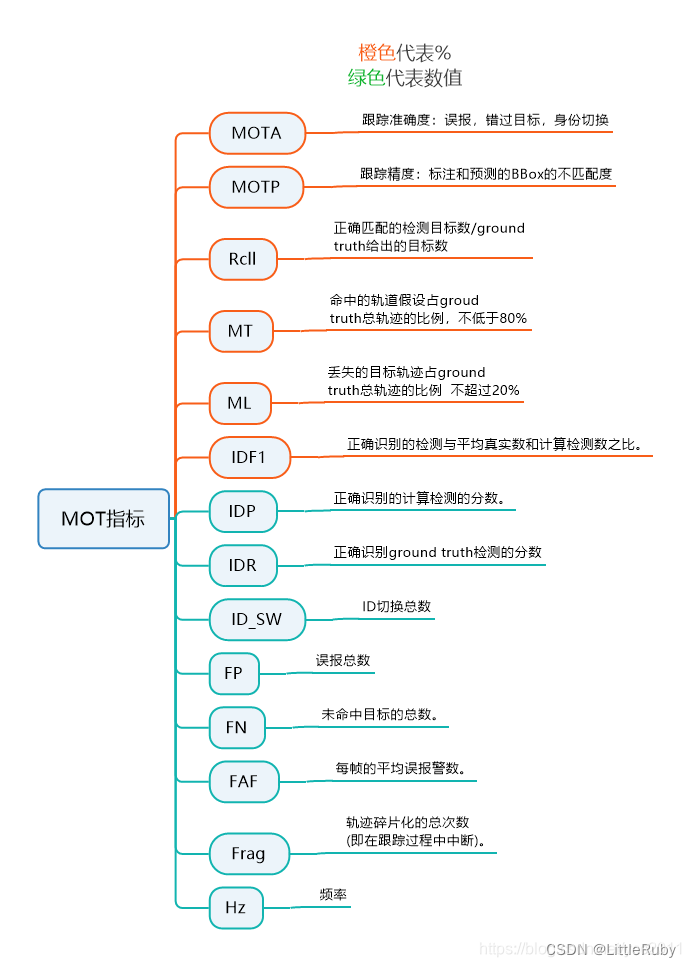
2.2执行评估程序
找到安装路径下的D:\Anaconda3\envs\deploy\Lib\site-packages\motmetrics-1.4.0-py3.8.egg\motmetrics\apps\eval_motchallenge.py文件,复制出来,我修改了txt的读取目录,直接写死,将txt内容加载至字典时,其中min_confidence值错误,改为min_confidence=-1,因为我在采用MOT16数据集的gt.txt做为测试结果与自己做比较时,发现mota的结果为负,就是这里错误。
gt = OrderedDict([(Path(f).parts[-3], mm.io.loadtxt(f, fmt=args.fmt, min_confidence=-1)) for f in gtfiles])
完整py文件如下:
# py-motmetrics - Metrics for multiple object tracker (MOT) benchmarking.
# https://github.com/cheind/py-motmetrics/
#
# MIT License
# Copyright (c) 2017-2020 Christoph Heindl, Jack Valmadre and others.
# See LICENSE file for terms.
"""Compute metrics for trackers using MOTChallenge ground-truth data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
from collections import OrderedDict
import glob
import logging
import os
from pathlib import Path
import motmetrics as mm
def parse_args():
"""Defines and parses command-line arguments."""
parser = argparse.ArgumentParser(description="""
Compute metrics for trackers using MOTChallenge ground-truth data.
Files
-----
All file content, ground truth and test files, have to comply with the
format described in
Milan, Anton, et al.
"Mot16: A benchmark for multi-object tracking."
arXiv preprint arXiv:1603.00831 (2016).
https://motchallenge.net/
Structure
---------
Layout for ground truth data
<GT_ROOT>/<SEQUENCE_1>/gt/gt.txt
<GT_ROOT>/<SEQUENCE_2>/gt/gt.txt
...
Layout for test data
<TEST_ROOT>/<SEQUENCE_1>.txt
<TEST_ROOT>/<SEQUENCE_2>.txt
...
Sequences of ground truth and test will be matched according to the `<SEQUENCE_X>`
string.""", formatter_class=argparse.RawTextHelpFormatter)
# parser.add_argument('groundtruths', type=str, help='Directory containing ground truth files.')
# parser.add_argument('tests', type=str, help='Directory containing tracker result files')
parser.add_argument('--loglevel', type=str, help='Log level', default='info')
parser.add_argument('--fmt', type=str, help='Data format', default='mot15-2D')
parser.add_argument('--solver', type=str, help='LAP solver to use for matching between frames.')
parser.add_argument('--id_solver', type=str, help='LAP solver to use for ID metrics. Defaults to --solver.')
parser.add_argument('--exclude_id', dest='exclude_id', default=False, action='store_true',
help='Disable ID metrics')
return parser.parse_args()
def compare_dataframes(gts, ts):
"""Builds accumulator for each sequence."""
accs = []
names = []
for k, tsacc in ts.items():
if k in gts:
logging.info('Comparing %s...', k)
accs.append(mm.utils.compare_to_groundtruth(gts[k], tsacc, 'iou', distth=0.5))
names.append(k)
else:
logging.warning('No ground truth for %s, skipping.', k)
return accs, names
def main():
# pylint: disable=missing-function-docstring
args = parse_args()
loglevel = getattr(logging, args.loglevel.upper(), None)
if not isinstance(loglevel, int):
raise ValueError('Invalid log level: {} '.format(args.loglevel))
logging.basicConfig(level=loglevel, format='%(asctime)s %(levelname)s - %(message)s', datefmt='%I:%M:%S')
if args.solver:
mm.lap.default_solver = args.solver
# gtfiles = glob.glob(os.path.join(args.groundtruths, '*/gt/gt.txt'))
# tsfiles = [f for f in glob.glob(os.path.join(args.tests, '*.txt')) if not os.path.basename(f).startswith('eval')]
os.chdir(r"F:\gittask\py_motmetrics")
os.getcwd()
gtfiles = ['yourdata/test1/gt/gt.txt',
'yourdata/test2/gt/gt.txt',]
tsfiles = ['yourdata/test1.txt',
'yourdata/test2.txt',]
logging.info('Found %d groundtruths and %d test files.', len(gtfiles), len(tsfiles))
logging.info('Available LAP solvers %s', str(mm.lap.available_solvers))
logging.info('Default LAP solver \'%s\'', mm.lap.default_solver)
logging.info('Loading files.')
gt = OrderedDict([(Path(f).parts[-3], mm.io.loadtxt(f, fmt=args.fmt, min_confidence=-1)) for f in gtfiles])
ts = OrderedDict([(os.path.splitext(Path(f).parts[-1])[0], mm.io.loadtxt(f, fmt=args.fmt)) for f in tsfiles])
mh = mm.metrics.create()
accs, names = compare_dataframes(gt, ts)
metrics = list(mm.metrics.motchallenge_metrics)
if args.exclude_id:
metrics = [x for x in metrics if not x.startswith('id')]
logging.info('Running metrics')
if args.id_solver:
mm.lap.default_solver = args.id_solver
summary = mh.compute_many(accs, names=names, metrics=metrics, generate_overall=True)
print(mm.io.render_summary(summary, formatters=mh.formatters, namemap=mm.io.motchallenge_metric_names))
logging.info('Completed')
if __name__ == '__main__':
main()
有个小伙伴因为数据的特殊性,在计算距离时采用的欧式距离,做了如下修改,可参考github代码https://github.com/ddz16/py-motmetrics

eval_motchallenge.py 可同时计算多个数据集,也可写一个测试单独数据集的demo
import motmetrics as mm
import numpy as np
import os
#评价指标
metrics = list(mm.metrics.motchallenge_metrics)
#导入gt和ts文件
# gt_file="/path/to/gt/gt.txt"
# ts_file="/path/to/test/0000.txt"
gt_file = "./gt.txt"
ts_file = "./gt.txt"
gt=mm.io.loadtxt(gt_file, fmt="mot16", min_confidence=-1)
ts=mm.io.loadtxt(ts_file, fmt="mot16")
name=os.path.splitext(os.path.basename(ts_file))[0]
#计算单个acc
acc=mm.utils.compare_to_groundtruth(gt, ts, 'iou', distth=0.5)
mh = mm.metrics.create()
summary = mh.compute(acc, metrics=metrics, name=name)
print(mm.io.render_summary(summary, formatters=mh.formatters,namemap=mm.io.motchallenge_metric_names))
3.安装xmltodict
用例的运行依赖xmltodict,首先,需要安装xmltodict库。
可以使用pip来安装它,只需运行以下命令:
pip install xmltodict
如果安装失败,可下载代码安装,xmltodict github地址
4.安装 lap
conda install -c conda-forge lap

















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









