









1.简介
上一篇文章里我们介绍了【图像生成】的GAN及其改进WGAN,还有对应的condition条件生成代码。这篇文章主要介绍另外一种生成网络VAE。
2.原理
VAE相对于GAN来说像是一种相反的存在:GAN是输入latent生成图像,再用生成的图像去修正网络;而VAE是输入图像生成latent,让latent的尽量接近原数据集的分布。这两者是不是有种奇妙的转置的感觉?
让我们从头来理解下VAE的由来和特点。首先我们从AE(Auto Encoder)说起,AE对图像进行encode后,生成一串可以表达图像特征的向量z,我们可以把这个特征向量z输入进decoder来还原出最初的图片。具体的流程图如下:

但是这样有个问题,AE结构只能对图像进行压缩和还原,并不能生成新的图像。那么怎么解决这个问题呢?把latent概率化就好了,这样我们就可以在特定的概率分布中获取一定的随机性。
VAE将latent表达为高斯的概率分布,同时通过网络去自动学习平衡图像生成的精确度和概率分布的拟合度,这两者可以分别用MSE和KL散度来计算。之所以使用高斯分布,是因为高斯分布可以去累加映射得到任何的数据分布,同时高斯分布可以通过参数重整化转换为标准正态分布的线性表达,因此VAE中的latent中包括了高斯分布的均值和标准差。具体的流程图如下:
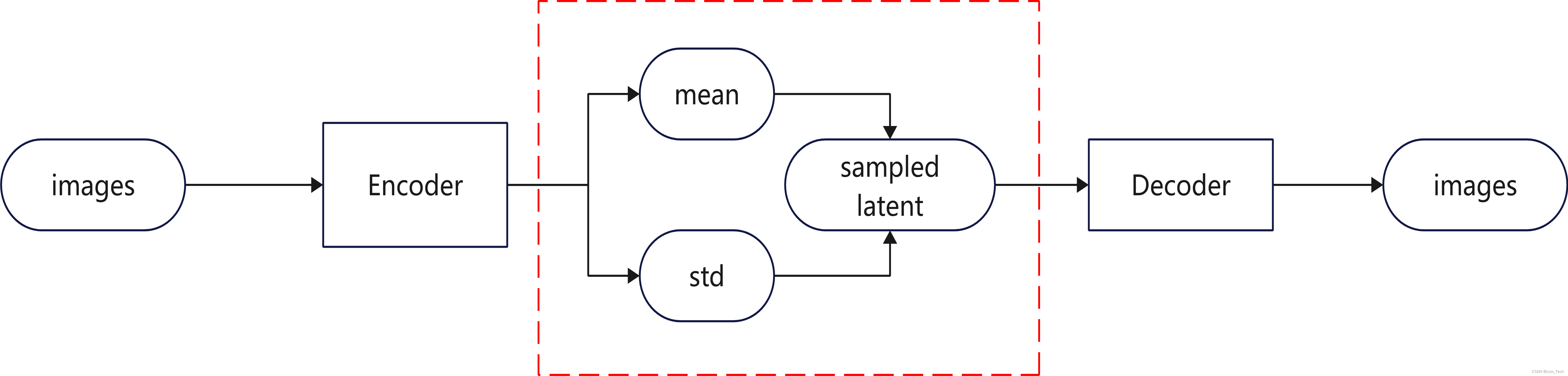
下图应该可以更加直观的理解,概率分布所表示的意义:
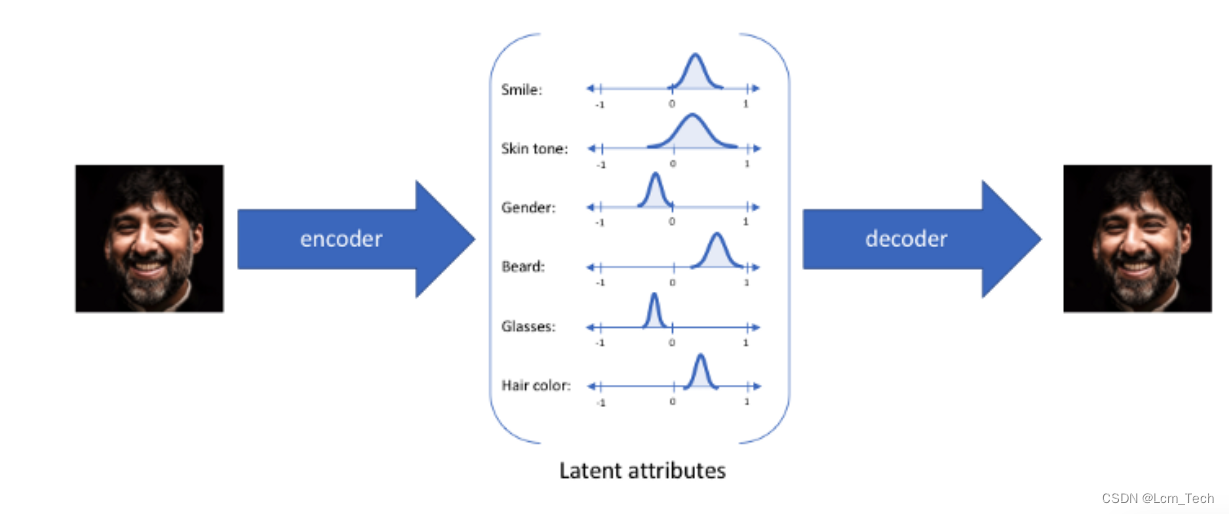
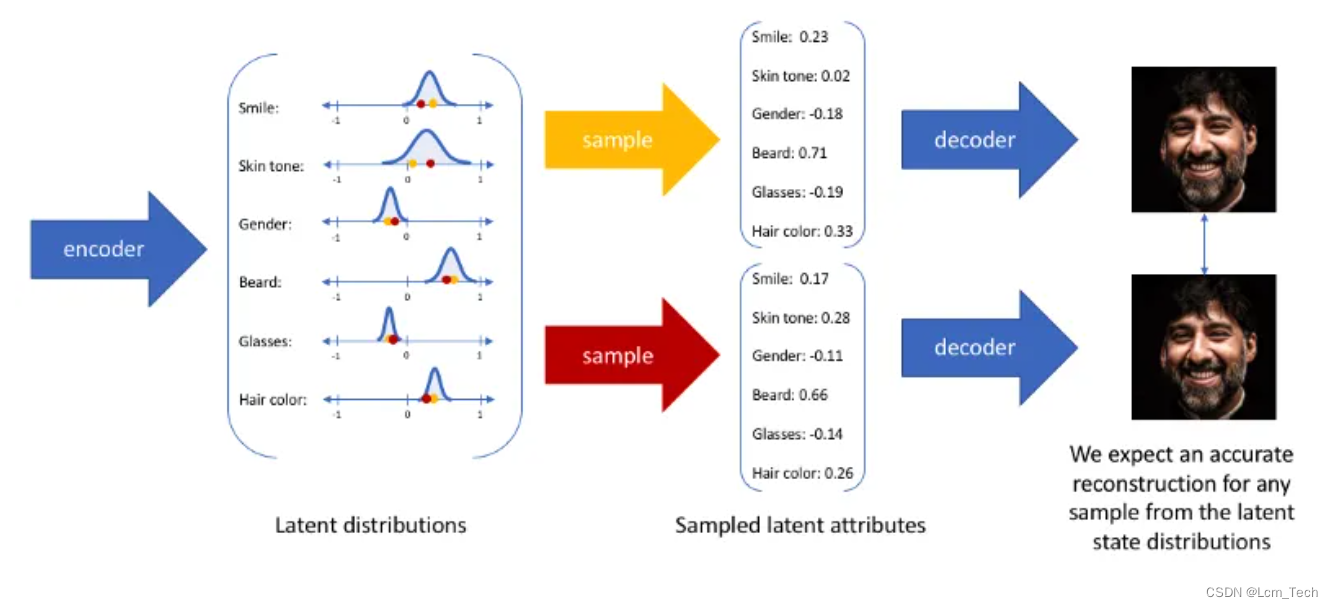
每个属性对应了一种特征,我们可以从每个特征的概率分布中去随机抽取,来得到对应的新生成的图像。
那么怎么具体训练才能得到每个特征具体的分布呢?刚才说了我们需要去平衡图像生成的精确度和概率分布的拟合度,这两者分布用MSE和KL散度来计算。MSE是去为了使latent输入进decoder的图像尽可能的接近输入encoder的真实图像,KL散度是为了让latent中的mean和std更接近于正态分布。
但是在实际过程中,如果直接去通过均值和方差随机生成高斯分布,是没办法进行梯度求导的,所以这里采用了一个技巧:参数重整化(Reparameterization),即将高斯分布表达为均值和标准差的线性组合,如下图所示:
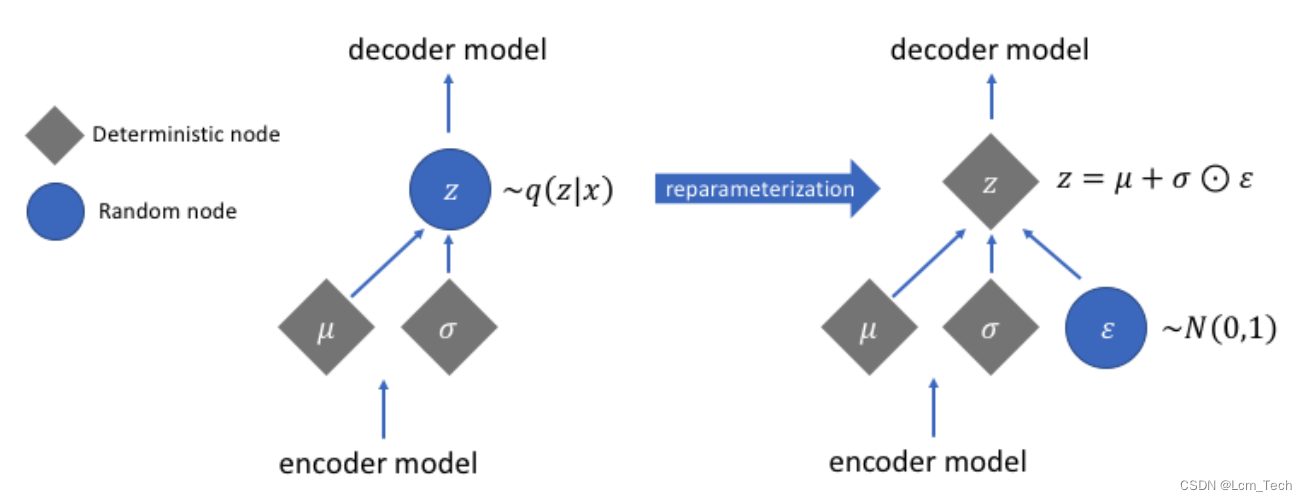
所以最后的训练流程图如下所示:

左图是直接用均值和标准差生成高斯分布,但这样梯度是没法反向推导的。右图是进行了参数重整化,引入随机的标准正态分布,这样使得训练成为可能(妙啊!)。
最后一个问题!!!可能有些同学还是不理解,为什么要让均值和标准差去逼近于标准正态分布。最开始我也有这个疑问,图像那块的重建loss很好理解,这块确实会比较抽象一点。
思来想去原来是一个很简单的道理:采样!!!
我们test的时候进行采样,不会用其他的均值和标准差,肯定是用的正态分布的latent,输入进decoder中生成图像。这里让均值和标准差尽可能去接近正态分布,为的就是让encoder去学习到数据的一个分布规律,并将它们映射到正态分布中,这样采样时直接用正态分布就可以包含所有的情况。
下图也和我的理解相似,将不同的分布映射到同一个区域,可以便于特征更好的融合和采样插值。
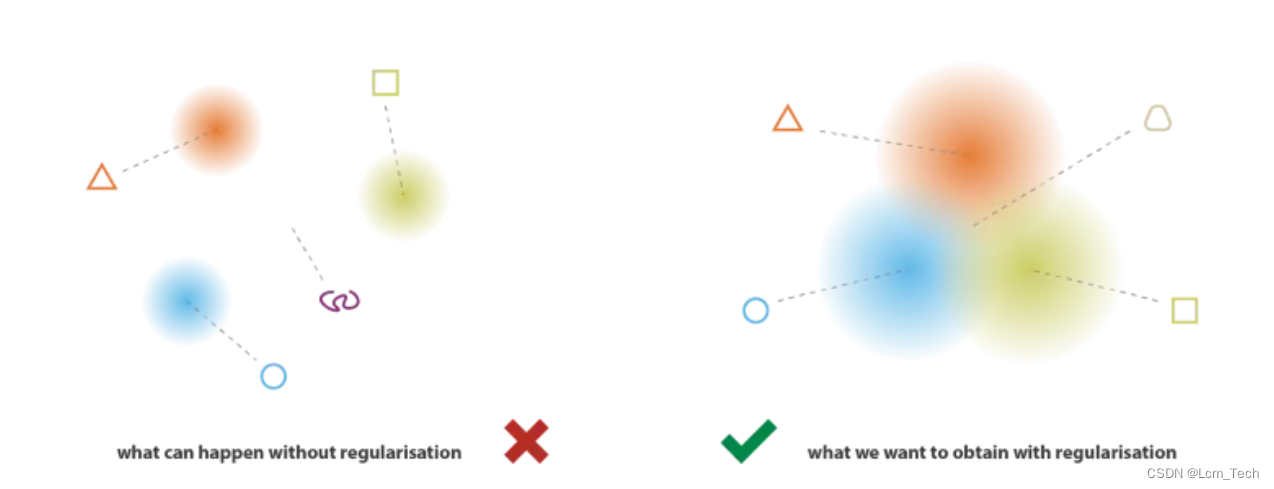
3.代码
接下来我们用pytorch来实现VAE在MNIST数据集上的生成。
3.1模型
encoder和decoder均用全连接层来简化,encoder中有两个分支,一个预测均值,一个预测标准差。decoder输入latent得到生成图像。
class VAE(nn.Module):
def __init__(self, input_dim=1, output_dim=1, middle_dim=400, latent_dim=20, class_num=10):
'''
初始化网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, middle_dim)
self.fc_mu = nn.Linear(middle_dim, latent_dim)
self.fc_logvar = nn.Linear(middle_dim, latent_dim)
self.fc2 = nn.Linear(latent_dim, middle_dim)
self.fc3 = nn.Linear(middle_dim, 784)
self.recons_loss = nn.BCELoss(reduction='sum')
def encode(self, x):
x = torch.relu(self.fc1(x))
mu = self.fc_mu(x)
logvar = self.fc_logvar(x)
return mu, logvar
def reparametrization(self, mu, logvar):
# sigma = 0.5*exp(log(sigma^2))= 0.5*exp(log(var))
std = torch.exp(logvar / 2)
eps = torch.randn_like(std)
# N(mu, std^2) = N(0, 1) * std + mu
z = eps * std + mu
return z
def decode(self, z):
x = torch.relu(self.fc2(z))
x = F.sigmoid(self.fc3(x))
return x
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrization(mu, logvar)
x_out = self.decode(z)
loss = self.loss_func(x_out, x, mu, logvar)
return loss
def loss_func(self, x_out, x, mu ,logvar):
reconstruction_loss = self.recons_loss(x_out, x)
KL_divergence = -0.5 * torch.sum(1 + logvar - torch.exp(logvar) - mu ** 2)
# KLD_ele = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
# KLD = torch.sum(KLD_ele).mul_(-0.5)
return reconstruction_loss + KL_divergence3.2训练
我们训练时先将图像通过encoder得到预测的均值和标准差,然后通过参数重整化计算得到latent,再将latent输入进decoder得到生成图像,最终计算重建loss和KL散度loss。
注意,这里的loss我们使用的是BCEloss,所以数据集加载进来不能再进行normalise,不然范围就不会在0-1之间。
def train(self):
self.model.train()
print('训练开始!!')
for epoch in range(self.epoch):
self.model.train()
loss_mean = 0
for i, (images, labels) in enumerate(self.train_dataloader):
images, labels = images.to(self.device), labels.to(self.device)
# 将latent和condition拼接后输入网络
loss = self.model(images.view(images.shape[0], -1))
loss_mean += loss.item()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
train_loss = loss_mean / len(self.train_dataloader)
print('epoch:{}, loss:{:.4f}'.format(epoch, train_loss))
self.visualize_results(epoch)3.3推理&可视化
在预测的时候就只用使用随机的正态分布latent输入进decoder就可以得到生成图像。
@torch.no_grad()
def visualize_results(self, epoch):
self.model.eval()
# 保存结果路径
output_path = 'results/VAE'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
# 生成对应sample个condition
z = torch.randn(tot_num_samples, self.latent_dim).to(self.device)
generated_images = self.model.decode(z)
generated_images = generated_images.view(generated_images.shape[0], 1, 28, 28)
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
可以看到结果比较模糊,这个是因为KL散度的loss不为0,代表着两个分布不能完全相似,只能得到一个大致的结果,所以才会导致模糊。
完整代码如下:
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, middle_dim=400, latent_dim=20, class_num=10):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, middle_dim)
self.fc_mu = nn.Linear(middle_dim, latent_dim)
self.fc_logvar = nn.Linear(middle_dim, latent_dim)
self.fc2 = nn.Linear(latent_dim, middle_dim)
self.fc3 = nn.Linear(middle_dim, 784)
self.recons_loss = nn.BCELoss(reduction='sum')
def encode(self, x):
x = torch.relu(self.fc1(x))
mu = self.fc_mu(x)
logvar = self.fc_logvar(x)
return mu, logvar
def reparametrization(self, mu, logvar):
# sigma = 0.5*exp(log(sigma^2))= 0.5*exp(log(var))
std = torch.exp(logvar / 2)
eps = torch.randn_like(std)
# N(mu, std^2) = N(0, 1) * std + mu
z = eps * std + mu
return z
def decode(self, z):
x = torch.relu(self.fc2(z))
x = F.sigmoid(self.fc3(x))
return x
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrization(mu, logvar)
x_out = self.decode(z)
loss = self.loss_func(x_out, x, mu, logvar)
return loss
def loss_func(self, x_out, x, mu ,logvar):
reconstruction_loss = self.recons_loss(x_out, x)
KL_divergence = -0.5 * torch.sum(1 + logvar - torch.exp(logvar) - mu ** 2)
# KLD_ele = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
# KLD = torch.sum(KLD_ele).mul_(-0.5)
return reconstruction_loss + KL_divergence
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 50
self.sample_num = 100
self.batch_size = 128
self.latent_dim = 20
self.lr = 0.001
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.model = VAE(latent_dim=self.latent_dim).to(self.device)
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('./data/',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('./data/',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False)
def train(self):
self.model.train()
print('训练开始!!')
for epoch in range(self.epoch):
self.model.train()
loss_mean = 0
for i, (images, labels) in enumerate(self.train_dataloader):
images, labels = images.to(self.device), labels.to(self.device)
loss = self.model(images.view(images.shape[0], -1))
loss_mean += loss.item()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
train_loss = loss_mean / len(self.train_dataloader)
print('epoch:{}, loss:{:.4f}'.format(epoch, train_loss))
self.visualize_results(epoch)
@torch.no_grad()
def visualize_results(self, epoch):
self.model.eval()
# 保存结果路径
output_path = 'results/VAE'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
# 生成对应sample个condition
z = torch.randn(tot_num_samples, self.latent_dim).to(self.device)
generated_images = self.model.decode(z)
generated_images = generated_images.view(generated_images.shape[0], 1, 28, 28)
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()
4. condition代码及结果
如果我们要生成condition条件下的图像,与之前的做法很类似,在encoder中将图像和标签的embedding向量拼接,在decoder中将latent和标签的embedding向量拼接:
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, middle_dim=400, latent_dim=20, class_num=10):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784 + class_num, middle_dim)
self.fc_mu = nn.Linear(middle_dim, latent_dim)
self.fc_logvar = nn.Linear(middle_dim, latent_dim)
self.fc2 = nn.Linear(latent_dim + class_num, middle_dim)
self.fc3 = nn.Linear(middle_dim, 784)
self.recons_loss = nn.BCELoss(reduction='sum')
def encode(self, x, labels):
x = torch.cat((x, labels), dim=1)
x = torch.relu(self.fc1(x))
mu = self.fc_mu(x)
logvar = self.fc_logvar(x)
return mu, logvar
def reparametrization(self, mu, logvar):
# sigma = 0.5*exp(log(sigma^2))= 0.5*exp(log(var))
std = torch.exp(logvar / 2)
eps = torch.randn_like(std)
# N(mu, std^2) = N(0, 1) * std + mu
z = eps * std + mu
return z
def decode(self, z, labels):
z = torch.cat((z, labels), dim=1)
x = torch.relu(self.fc2(z))
x = F.sigmoid(self.fc3(x))
return x
def forward(self, x, labels):
mu, logvar = self.encode(x, labels)
z = self.reparametrization(mu, logvar)
x_out = self.decode(z, labels)
loss = self.loss_func(x_out, x, mu, logvar)
return loss
def loss_func(self, x_out, x, mu ,logvar):
reconstruction_loss = self.recons_loss(x_out, x)
KL_divergence = -0.5 * torch.sum(1 + logvar - torch.exp(logvar) - mu ** 2)
# KLD_ele = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
# KLD = torch.sum(KLD_ele).mul_(-0.5)
return reconstruction_loss + KL_divergence
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 50
self.sample_num = 100
self.batch_size = 128
self.latent_dim = 20
self.lr = 0.001
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.model = VAE(latent_dim=self.latent_dim, class_num=10).to(self.device)
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('./data/',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('./data/',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False)
def train(self):
self.model.train()
print('训练开始!!')
for epoch in range(self.epoch):
self.model.train()
loss_mean = 0
for i, (images, labels) in enumerate(self.train_dataloader):
images, labels = images.to(self.device), labels.to(self.device)
labels = F.one_hot(labels, num_classes=10)
# 将latent和condition拼接后输入网络
loss = self.model(images.view(images.shape[0], -1), labels)
loss_mean += loss.item()
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
train_loss = loss_mean / len(self.train_dataloader)
print('epoch:{}, loss:{:.4f}'.format(epoch, train_loss))
self.visualize_results(epoch)
@torch.no_grad()
def visualize_results(self, epoch):
self.model.eval()
# 保存结果路径
output_path = 'results/VAE'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
# 生成对应sample个condition
z = torch.randn(tot_num_samples, self.latent_dim).to(self.device)
labels = F.one_hot(torch.Tensor(np.repeat(np.arange(10), 10)).to(torch.int64), num_classes=10).to(self.device)
generated_images = self.model.decode(z, labels)
generated_images = generated_images.view(generated_images.shape[0], 1, 28, 28)
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()

业务合作/学习交流+v:lizhiTechnology
如果想要了解更多图像生成相关知识,可以参考我的专栏和其他相关文章:
【图像生成】(一) DNN 原理 & pytorch代码实例_pytorch dnn代码-CSDN博客
【图像生成】(二) GAN 原理 & pytorch代码实例_gan代码-CSDN博客
【图像生成】(三) VAE原理 & pytorch代码实例_vae算法 是如何生成图的-CSDN博客
【图像生成】(四) Diffusion原理 & pytorch代码实例_diffusion unet-CSDN博客
如果想要了解更多深度学习相关知识,可以参考我的其他文章:
【优化器】(一) SGD原理 & pytorch代码解析_sgd优化器-CSDN博客














 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









