







在帮师兄弄项目时接触了RangiLyu大佬的nanodet-plus,故写下这篇文章方便自己以后复习
整体结构
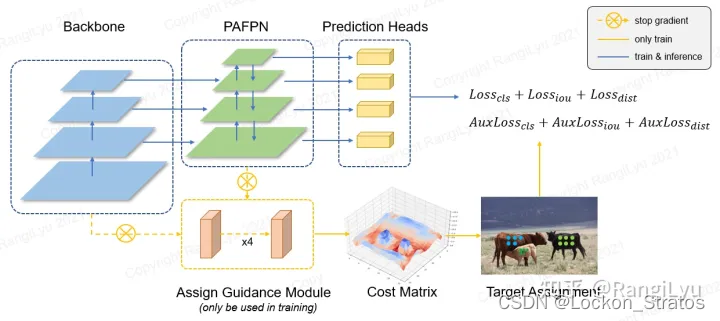
上图是RangiLyu大佬知乎文章中给出的nanodet结构,可以看到模型backbone的输出除了送入neck和head外还送入了AGM辅助训练模块,这个模块会在训练到一定轮次后退出训练,目的是帮助检测头学习
模型代码
nanodet-plus使用了pytorch-lighting,这个库我也是第一次接触,在读完pytorch lightning最简上手这篇文章后大概有了一定的了解,于是自己总结了一下nanodet代码的大概结构,如有不对,欢迎指正:
模型主体结构如下:
- 在__init__中定义好模型的层,如nanodet\model\arch_init_.py中定义好整个nanodetplus的整体架构一样,模型的每个部分都有__init__.py
- 在forward函数中完成模型前向的过程,主要调用__init__中定义好的各个层
- 从引入的包看,nanodetplus -> onestagedetector + aux_head -> backbone+fpn+head,由此定义了整个模型的大体结构
- 在nanodetplus中,包含两个部分,一个是模型整体结构onestagedetector,一个是辅助训练头aux_head,并判断在第几轮辅助训练头退出训练
- 在onestagedetector中定义了模型整体的前向过程,输入数据经过backbone提取特征,输入fpn进行特征融合,最后送到head进行预测
- 至此,模型整体的结构就搭建完成,改进可能就是搭建自己的部分,然后在__init__.py中定义好后再调用
模型辅助部分:
- 在trainer\task部分定义了在一个训练流程中需要做的事:主要是将数据送入模型,然后得到输出
- 此外还定义了一些其他的关于训练测试时的事,如训练\验证\测试步:定义每一步中需要做的事,
- 在训练步中包括读取数据,获得预测和损失值,并打印出log的信息,在验证步中获取后处理的结果
- 训练\验证\测试步结束后,在训练步中保存checkpoint,在验证中整理后处理结果并保存权重
- 训练\验证\测试轮结束后,更新权重
- 在data中定义了关于数据集相关的方法:
- 在dataset中定义了不同数据集格式的处理方法,在transform中定义了数据增强的不同方式
- 剩余的两个函数,定义了数据处理的方法
开始训练:
在tools\train.py中,定义参数,获取参数,创建数据集,获取训练时所需要执行的任务task,
在task中实例化模型build_model,接着实例化训练器trainer,然后trainer.fit开始训练
一开始看pl库的时候晕乎乎没看懂,因为以前接触的都是pytorch的架子,模型怎么走debug就能看出大概,现在感觉好方便,只要搞完模型结构剩下的交给pl就好 =v=
参考文章:
超简单辅助模块加速训练收敛,精度大幅提升!移动端实时的NanoDet升级版NanoDet-Plus来了!
pytorch lightning最简上手















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









