







最近在看rcnn,rcnn主要是用来进行目标检测,语义分割的
是一个将cnn使用到目标检测的突破,进而诞生了rcnn,sppnet,fast-rcnn,faster-rcnn
在此,使用这个博文介绍一下以上的rcnn及其扩展中使用到的东西的简单介绍吧
1,OverFeat
OverFeat is a Convolutional Network-based image classifier and feature extractor.
参考《OverFeat:Integrated Recognition, Localizationand Detection using Convolutional Networks》
有两点,其中第二点是亮点:
(1)特征共享:首先在分类问题上训练出来模型,然后Fix住卷积层,来对定位模型进行fine tuning,最后对应1k个类别做了1k个定位的模型。
(2)“快速”滑动窗口:为何要用滑动窗口?对于分类,通过多视角和多尺度来提高分类的置信度;对于定位,解决了多物体以及多尺度的问题。如何提高滑动窗口的效率?不在原始图片上做滑动窗口,而是在最后一个pooling层上面做滑动窗口。
快速滑动窗口
也就是在最后一个pool层上做滑动窗口。
本质上,在pool做小步长的滑动窗口和在原始图片上做大步长的滑动窗口,从识别效果上来说几乎是等价的,但是在效率上存在极大的差别——所以这里的“快速”本质上是利用了CNN卷积层和下采样层的空间对应关系来减少计算。
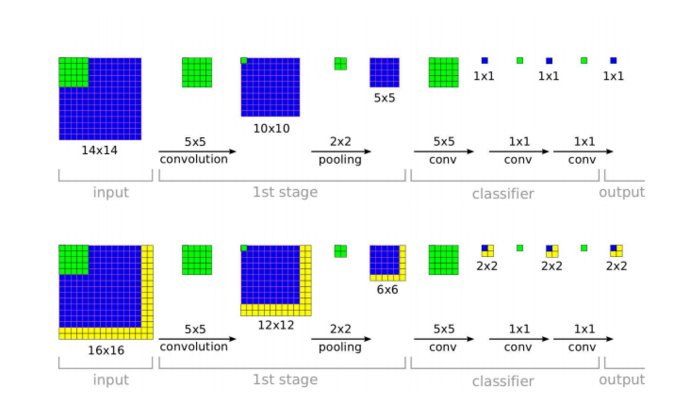
- 对于分类模型,训练只使用单个尺度(221*221)进行训练,测试时候不改变网络架构,却是使用多个尺度进行输入的——于是导致了网络的输出由1维变成了2维(其实就是滑动窗口)
- 训练分类模型只是使用了单尺度,但后面训练定位模型时候用到了多尺度,个人认为是为了增加样本——因为训练1k个定位模型的话,每类的样本太少了。
- 本文提出的“测试时实现多视角多尺度”方法,其本质上就是滑动窗口——多视角≈滑动到不同的位置,多视角≈大小不一的窗口。只是利用CNN的固有属性以及一些技巧,减少了测试时候的运算量。
2.Fully COnvolutional Networks
可以参考《Fully Convolutional Networks for SemanticSegmentation》

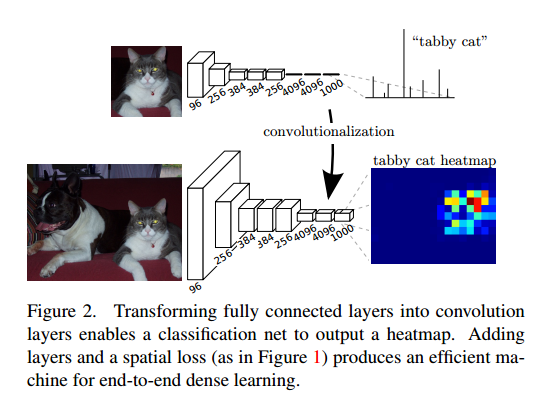
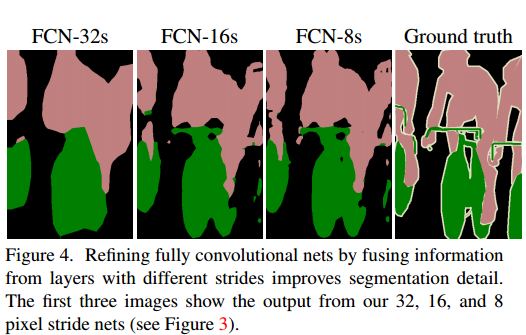
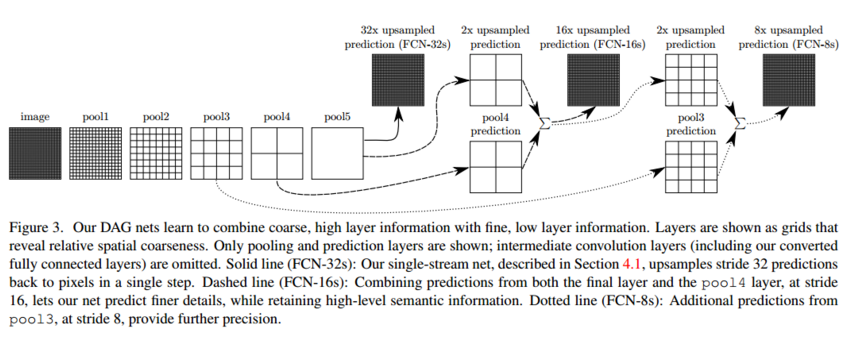
下面是知乎上的解释:
RCNN 解决的是,“为什么不用CNN做classification呢?”
(但是这个方法相当于过一遍network出bounding box,再过另一个出label,原文写的很不“elegant”
Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
(但是这个时候用selective search generate regional proposal的时间实在太长了
Faster-RCNN 解决的是,“为什么还要用selective search呢?”
(但是这个方法相当于过一遍network出bounding box,再过另一个出label,原文写的很不“elegant”
Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
(但是这个时候用selective search generate regional proposal的时间实在太长了
Faster-RCNN 解决的是,“为什么还要用selective search呢?”















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









