







RCNN的变体,在此介绍一下RCNN的相关变形及改进
RCNN->SPPNET->Fast-RCNN->Faster-RCNN
1.RCNN
将原来的目标检测的过程与CNN建立连接,将检测转换成为region proposal的分类问题。
RCNN算法的核心思想就是对每个区域通过CNN提取特征,然后接上一个分类器预测这个区域包含一个感兴趣对象的置信度,也就是说,转换成了一个图像分类问题(类似imagenet),后面接的这个分类器可以是独立训练的svm也可以是简单的softmax分类。
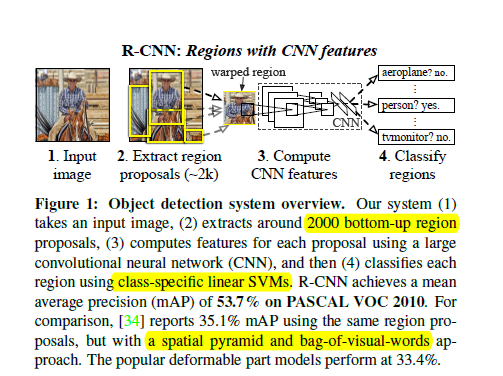
RCNN 主要的过程 :用SS(selective search)去选框(region proposal),CNN提特征,SVM分类。BB(bounding box)盒回归。
存在的缺点:
1 使用的warped region 将图像区域作为固定的尺寸输入到CNN中,或对图像造成扭曲等
2.速度极慢,不适用于现实的应用
2.SPPNET
提出是针对RCNN的缺点进行改进,
去掉对CNN的固定大小的输入,在全连接处对feature map进行采样叠加进而输出固定的大小进入全连接。
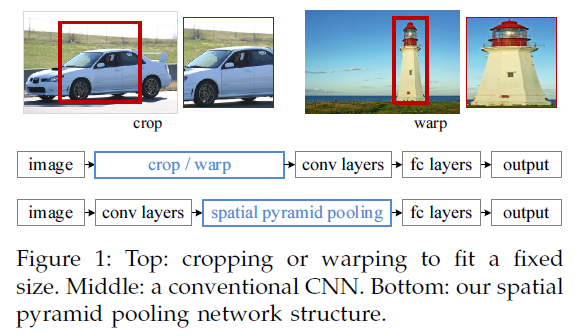
SPP是BOW的扩展,将图像从精细空间划分到粗糙空间,之后将局部特征聚集。在CNN成为主流之前,SPP在检测和分类的应用比较广泛。SPP的优点:1)任意尺寸输入,固定大小输出,2)层多,3)可对任意尺度提取的特征进行池化。
R-CNN提取特征比较耗时,需要对每个warp的区域进行学习,而SPPNet只对图像进行一次卷积,之后使用SPPNet在特征图上提取特征。结合EdgeBoxes提取的proposal,系统处理一幅图像需要0.5s。
SPP层的结构如下,将紧跟最后一个卷积层的池化层使用SPP代替,输出向量大小为kM,k=#filters,M=#bins,作为全连接层的输入。至此,网络不仅可对任意长宽比的图像进行处理,而且可对任意尺度的图像进行处理。尺度在深层网络学习中也很重要。
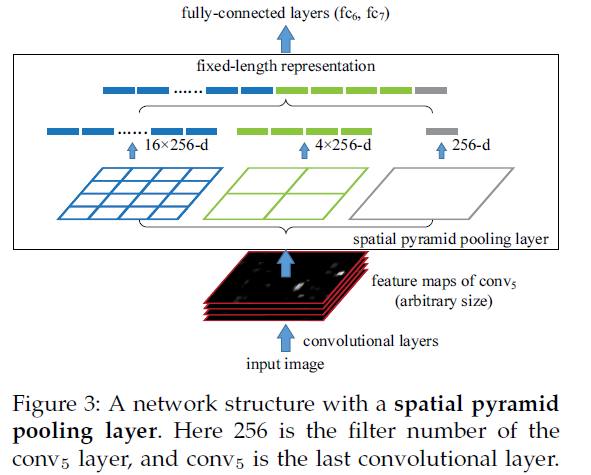
multi-size训练,输入尺寸在[180,224]之间,假设最后一个卷积层的输出大小为 a×a ,若给定金字塔层有 n×n 个bins,进行滑动窗池化,窗口尺寸为 win=⌈a/n⌉ ,步长为 str=⌊a/n⌋ ,使用一个网络完成一个完整epoch的训练,之后切换到另外一个网络。只是在训练的时候用到多尺寸,测试时直接将SPPNet应用于任意尺寸的图像。
SPPNet for Object Detection
R-CNN重复使用深层卷积网络在~2k个窗口上提取特征,特征提取非常耗时。SPPNet比较耗时的卷积计算对整幅图像只进行一次,之后使用spp将窗口特征图池化为一个固定长度的特征表示。
检测算法:使用ss生成~2k个候选框,缩放图像min(w,h)=s之后提取特征,每个候选框使用一个4层的空间金字塔池化特征,网络使用的是ZF-5的SPPNet形式。之后将12800d的特征输入全连接层,SVM的输入为全连接层的输出。SVM如下使用,正样本为groundtruth,负样本与正样本的IoU<0.3
sppnet利用共享计算(空间金字塔池化)解决全连接的尺寸固定,object proposal从feature map中提取金字塔的池化特征,并串联起来
缺点:仍是多阶段的流水操作(1,提取特征(CNN)2,SVM(分类)3,bounding box 画框)
sppnet的金字塔池化层的之前的或之后的参数更新是间断的,甚至是无法更新的,进而对网络的准确度产生影响
3.Fast RCNN
针对RCNN与SPPNET的缺陷
训练的时候,pipeline是隔离的,先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression。FRCN实现了end-to-end的joint training(提proposal阶段除外)。
训练时间和空间开销大。RCNN中ROI-centric的运算开销大,所以FRCN用了image-centric的训练方式来通过卷积的share特性来降低运算开销;RCNN提取特征给SVM训练时候需要中间要大量的磁盘空间存放特征,FRCN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间了。
测试时间开销大。依然是因为ROI-centric的原因,这点SPP-Net已经改进,然后FRCN进一步通过single scale testing和SVD分解全连接来提速。
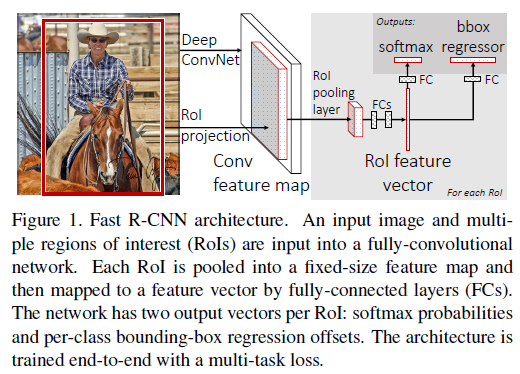
具体的过程:
selective search在一张图片中得到约2k个object proposal(这里称为RoI)缩放图片的scale得到图片金字塔,FP得到conv5的特征金字塔。
对于每个scale的每个ROI,求取映射关系,在conv5中crop出对应的patch。并用一个单层的SPP layer(这里称为Rol pooling layer)来统一到一样的尺度(对于AlexNet是6x6)。
继续经过两个全连接得到特征,这特征有分别share到两个新的全连接,连接上两个优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression,使用了一个smooth的L1-loss.
引入ROI polling
Rol pooling layer的作用主要有两个,一个是将image中的rol定位到feature map中对应patch,另一个是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。
尺度不变性
这里讨论object的scale问题,就是网络对于object的scale应该是要不敏感的。这里还是引用了SPP的方法,有两种。
brute force (single scale),也就是简单认为object不需要预先resize到类似的scale再传入网络,直接将image定死为某种scale,直接输入网络来训练就好了,然后期望网络自己能够学习到scale-invariance的表达。
image pyramids (multi scale),也就是要生成一个金字塔,然后对于object,在金字塔上找到一个大小比较接近227x227的投影版本,然后用这个版本去训练网络。
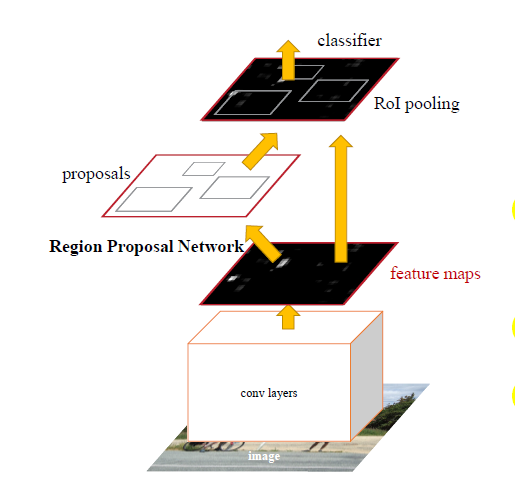
4.FASTER-RCNN
看作是对于fast-rcnn的改进主要是将selective proposal给去掉,集成到网络中,
通过交替优化来学习共享的特征,主要有4步:
- 1. 使用前面的方法训练一个RPN。用 ImageNet 的 model 初始化,然后针对 region proposal task 进行微调。
- 2. 利用第一步得到的 proposals 使用 Fast R-CNN 来训练另一一个单独的 detection network, 到这里两个网络还是分开的,没有 share conv layers 。
- 3. 利用第二部训练好的 detection network 来初始化 RPN , 然后训练,这里训练的时候固定 conv layers ,只微调 RPN 那一部分的网络层。
- 4. 再固定 conv layers ,只微调 Fast R-CNN 的 fc 层。
Faster-RCNN最大一点贡献应该算是其把proposal部分从网络外边嵌入了网络里边,从此一个网络模型即可完成end-to-end的检测任务而不需要我们在前面手动先执行一遍proposal的搜索算法。其实如果回过头来看看几年前比较流行的检测算法,比如HOG+SVM和DPM什么的,同样是需要用分类器逐个对一些矩形框里提取出来的特征进行分类,只不过那时是全图设置好stride、scale等参数然后搜索,不像selective search这些算法会去对图像进行内容分析,然后输出一些可疑的矩形候选框。
某种程度上,RPN也可以算作一个全图搜索的粗检测器,图片在输入网络后,依次经过一些卷积、池化层,然后得到的feature map被手动划分为 n×n n×n 个矩形窗口(论文中n=3),准备后续用来选取proposal,并且此时坐标依然可以映射回原图。需要注意两点问题:1.在到达全连接层之前,卷积层和Pooling层对图片输入大小其实没有size的限制,因此RCNN系列的网络模型其实是不需要实现把图片resize到固定大小的;2.n=3看起来很小,但是要考虑到这是非常高层的feature map,其size本身也没有多大,因此 3*3, 9个矩形中,每个矩形窗框都是可以感知到很大范围的。
在划分为,n×n 个窗口后,我们把每个矩形窗口的中心点当成一个基准点,然后围绕这个基准点选取k(k=9)个不同scale、aspect ratio的anchor(论文中3个scale和3个aspect ratio),对于每个anchor,首先在后面接上一个二分类softmax,有2个score输出用以表示其是一个物体的概率与不是一个物体的概率,然后再接上一个bounding box的regressor,以及4个坐标输出代表这个anchor的坐标位置,因此RPN的总体Loss函数可以定义为:

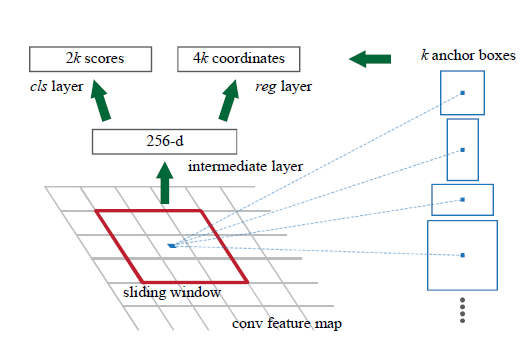
Region Proposal Networks
RPNs 从任意尺寸的图片中得到一系列的带有 objectness score 的 object proposals。具体流程是:使用一个小的网络在最后卷积得到的特征图上进行滑动扫描,这个滑动的网络每次与特征图上n*n 的窗口全连接,然后映射到一个低维向量,例如256D或512D, 最后将这个低维向量送入到两个全连接层,即box回归层(box-regression layer (reg))和box分类层(box-regression layer (reg))。
Translation-Invariant Anchors
这里作者说的平移不变性,其实就是以窗口中心进行多个尺度、宽高比的采样。如上图右边,文中使用了3 scalesand 3 aspect ratios (1:1,1:2,2:1), 就产生了 k = 9 anchors at each sliding position. Anchors 这个词不知道应该怎么翻译,原文写的是:The k proposals are parameterized relative to k reference boxes, calledanchors。
以上是简单的介绍,后续会补充。















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









