







 Fast R-CNN是R-CNN和SPP-net的改进版,解决了训练耗时和空间开销大的问题。通过end-to-end的训练,实现了分类和边界框回归的联合优化。主要改进包括:ROI pooling层、多任务损失函数、小批量采样和SVD加速全连接层训练。在训练时,Fast R-CNN采用image-centric采样减少计算开销,并利用RoI pooling层统一特征尺寸。测试时,通过单尺度测试和SVD加速提高了效率。Fast R-CNN摒弃了SVM,使用softmax和L1-smooth loss,提升了性能。
Fast R-CNN是R-CNN和SPP-net的改进版,解决了训练耗时和空间开销大的问题。通过end-to-end的训练,实现了分类和边界框回归的联合优化。主要改进包括:ROI pooling层、多任务损失函数、小批量采样和SVD加速全连接层训练。在训练时,Fast R-CNN采用image-centric采样减少计算开销,并利用RoI pooling层统一特征尺寸。测试时,通过单尺度测试和SVD加速提高了效率。Fast R-CNN摒弃了SVM,使用softmax和L1-smooth loss,提升了性能。
reference link:
http://zhangliliang.com/2015/05/17/paper-note-fast-rcnn/
http://blog.csdn.net/shenxiaolu1984/article/details/51036677
http://blog.csdn.net/qq_26898461/article/details/50906926
以下介绍具体包括如下4个stage算法:
1.Rol pooling layer(fc)
2.Multi-task loss(one-stage)
3.Scale invariance(trade off->single scale(compare with multi-scale for decreasing 1mAP) )
4.SVD on fc layers(speed up training)
作者提出和我们需要思考的问题:
2.Data augment
3.Are more proposals always better?
R-CNN、SPP-net的缺点:
1) R-CNN:
1. 训练时要经过多个阶段,首先要提取特征微调ConvNet,再用线性SVM处理proposal,计算得到的ConvNet特征,然后进行用bounding box回归2. 训练时间和空间开销大。要从每一张图像上提取大量proposal,还要从每个proposal中提取特征,并存到磁盘中。
3. 测试时间开销大。同样是要从每个测试图像上提取大量proposal,再从每个proposal中提取特征来进行检测过程,可想而知是很慢的。
2) SPPnet:
SPP已有一定的速度提升,它在ConvNet的最后一个卷积层才提取proposal,但是依然有不足之处。和R-CNN一样,它的训练要经过多个阶段,特征也要存在磁盘中,另外,SPP中的微调只更新spp层后面的全连接层,对很深的网络这样肯定是不行的。在微调阶段谈及SPP-net只能更新FC层,这是因为卷积特征是线下计算的,从而无法再微调阶段反向传播误差。而在fast-RCNN中则是通过image-centric
Fast-Rcnn 改进:
1. 比R-CNN更高的检测质量(mAP);2. 把多个任务的损失函数写到一起,实现单级的训练过程;
3. 在训练时可更新所有的层;
4. 不需要在磁盘中存储特征。
解决方式:
1.训练的时候,pipeline是隔离的,先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression。FRCN实现了end-to-end的joint training(提proposal阶段除外)。
2.训练时间和空间开销大。RCNN中ROI-centric的运算开销大,所以FRCN用了image-centric的训练方式来通过卷积的share特性来降低运算开销;
RCNN提取特征给SVM训练时候需要中间要大量的磁盘空间存放特征,FRCN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间了。
3.测试时间开销大。依然是因为ROI-centric的原因(whole image as input->ss region映射),这点SPP-Net已经改进,然后FRCN进一步通过single scale(pooling->spp just for one scale) testing和SVD(降维)分解全连接来提速。
整体框架如Figure 1,如果以AlexNet(5个卷积和3个全连接)为例,大致的训练过程可以理解为:
1.selective search在一张图片中得到约2k个object proposal(这里称为RoI)
2.缩放图片的scale得到图片金字塔,FP得到conv5的特征金字塔。
3.对于每个scale的每个ROI,求取映射关系,在conv5中crop出对应的patch。并用一个单层的SPP layer(这里称为Rol pooling layer)来统一到一样的尺度(对于AlexNet是6x6)。
4.继续经过两个全连接得到特征,这特征有分别share到两个新的全连接,连接上两个优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression,使用了一个smooth的L1-loss.(除了1,上面的2-4是joint training的。测试时候,在4之后做一个NMS即可。)
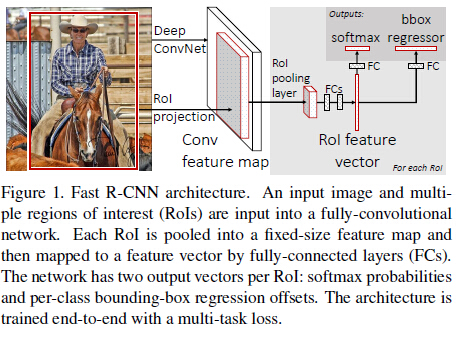
整体框架大致如上述所示,再次几句话总结:
1.用selective search在一张图片中生成约2000个object proposal,即RoI。
2.把它们整体输入到全卷积的网络中,在最后一个卷积层上对每个ROI求映射关系,并用一个RoI pooling layer来统一到相同的大小-> (fc)feature vector 即->提取一个固定维度的特征表示。
3.继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量:第一个是分类,使用softmax,第二个是每一类的bounding box回归。
按照论文所述即:one that produces softmax probability estimates overKobject classes plus a catch-all “background” class and
another layer that outputs four real-valued numbers for each of theKobject classes
对比回来SPP-Net,可以看出FRCN大致就是一个joint training版本的SPP-Net,改进如下:
1.改进了SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层。只能更新fc层的原因,按照论文所描述:
the root cause is that back-propagation through the SPPlayer is highly inefficient when each training sample (i.e.RoI) comes from a different image, which is exactly howR-CNN and SPPnet networks are trained.
The inefficiency stems from the fact that each RoI may have a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image).
2.SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor。
RoI pooling layer
这是SPP pooling层的一个简化版,只有一级“金字塔”,输入是N个特征映射和一组R个RoI,R>>N。N个特征映射来自于最后一个卷积层,每个特征映射都是H x W x C的大小。每个RoI是一个元组(n, r, c, h, w),n是特征映射的索引,n∈{0, ... ,N-1},(r, c)是RoI左上角的坐标,(h, w)是高与宽。输出是max-pool过的特征映射,H' x W' x C的大小,H'≤H,W'≤W。对于RoI,bin-size ~ h/H' x w/W',这样就有H'W'个输出bin,bin的大小是自适应的,取决于RoI的大小。
Rol pooling layer的作用主要有两个:
1.是将image中的rol定位到feature map中对应patch
2.是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。即RoI pooling layer来统一到相同的大小-> (fc)feature vector 即->提取一个固定维度的特征表示。
这里有几个细节:
1.对于某个rol,怎么求取对应的feature map patch?
这个论文没有提及,笔者也觉得应该与spp-net的映射关系一致
2.为何只是一层的SPP layer?
多层的SPP layer不会更好吗?对于这个问题,笔者认为是因为需要读取pretrain model来finetuning的原因,比如VGG就release了一个19层的model,如果是使用多层的SPP layer就不能够直接使用这个model的parameters,而需要重新训练了。
Roi Pooling Test Forward:
Roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
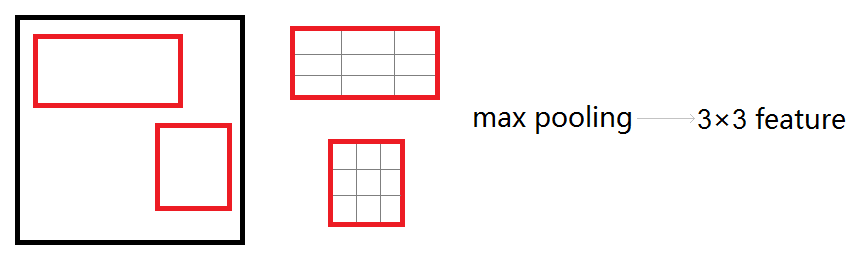
Roi Pooling Training Backward:
首先考虑普通max pooling层。设 xi 为输入层的节点, yj 为输出层的节点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









