







 本文探讨如何运用LDA等主题模型来构建产品间的替代与互补关系网络,通过对产品评论和描述的数据分析,实现更好的推荐系统。通过LDA生成产品主题分布,并以此建立产品间的关联预测模型,实验表明这种方法有助于发现新产品、组合和上下文相关的推荐。
本文探讨如何运用LDA等主题模型来构建产品间的替代与互补关系网络,通过对产品评论和描述的数据分析,实现更好的推荐系统。通过LDA生成产品主题分布,并以此建立产品间的关联预测模型,实验表明这种方法有助于发现新产品、组合和上下文相关的推荐。
要解决的问题
A user is looking for mobile phones, it might make sense to recommend other phones, but once they buy a phone, we might instead want to recommend batteries, cases, or chargers. These two types of recommendations are referred to as substitutes and complements: substitutes are products that can be purchased instead of each other, while complements are products that can be purchased in addition to each other.
拥有的资源
The primary source of data we use is the text of product reviews, though our method also makes use of features such as ratings, specifications, prices, and brands.
以及物物关系,这个关系作为监督学习的ground truth
达到的目的
Navigation between related products, discovery of new and previously unknown products, identification of interesting product combinations, and generation of better and more context-relevant recommendations.

最直接的是我在看鞋,推荐鞋。我买了鞋,推荐袜子。
产出
product graph。所以就是非懒惰学习。
大致思路
1.利用主题模型(LDA)生成物品i的主题分布 θi 。数据支撑为评论和描述
2.在 θi 上做文章。生成静态模型,预测物品i和j之间的关系。其实已经不能算是预测了,就是求。最后就是查。
具体操作
主题模型
Unigram Model
这种方法通过训练语料获得一个单词的概率分布函数,然后根据这个概率分布函数每次生成一个单词,使用这个方法M次生成M个文档。每个文档都是N个词。
Mixture of Unigram
Unigram模型太简单了,不能生成主题。这种方法首先选选定一个主题z,主题z对应一个单词的概率分布p(w|z),每次按这个分布生成一个单词,使用M次这个方法生成M份不同的文档。
LDA(Latend Dirichlet Allocation)
LDA方法使生成的文档可以包含多个主题,该模型使用下面方法生成1个文档:
这种方法首先选定一个主题向量θ,确定每个主题被选择的概率。然后在生成每个单词的时候,从主题分布向量θ中选择一个主题z,按主题z的单词概率分布生成一个单词。其图模型如下图所示:
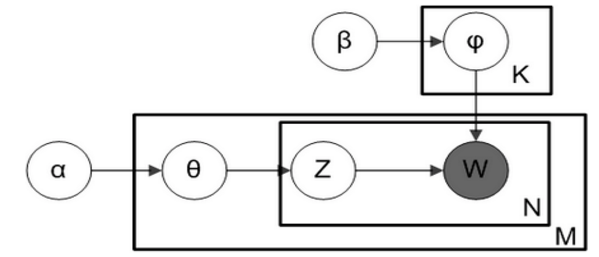
α 和 β 是Dirichlet超参数,使分布平滑。训练过程:

后面数学可不看了。一般人都是直接用。。。。。
看懂LDA的一些数学知识
Maximum Likelihood
模型已定,参数未定。样本独立同分布。现在出现的分布是出现概率最大的分布。
求解参数过程:把每次出现的数据带入模型,得出现概率,再相乘求极大值点的坐标。
e.g.
扔一个硬币,head向上49次,tail向上51次,问head概率是多少。口答:49/100。Why:
p49(1−p)51 为该次实验情况出现概率。之所以能写出来是因为模型已定,如果扔一次换一枚硬币就不行了。求它极大值点为 p=49/100
Gamma function
这个函数就叫Gamma函数。通过分布积分可以得到它的一个性质:
容易证明这就是阶乘在实数集上的扩展:
Beta Distribution
1: X1,X2,...,Xn∼Uniform(0,1)(i.i.d.)
2: 排序之后得,顺序统计量 X(1),X(2),...,X(n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









