







遭遇问题
在机器学习—-线性模型里我们说到了Logistic Regression,解决二分类问题:
Logistic(x)=11+e−x
图像为:
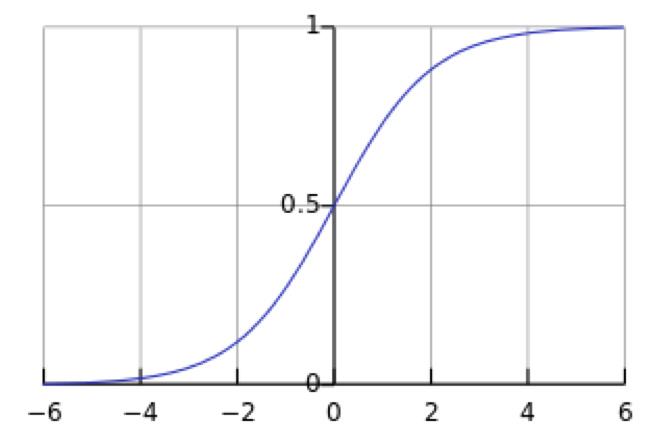
它把输出为范围为R的变量,压缩到(0,1),从而完成分类问题:输出大于0.5为正例,小于0.5为反例,等于0.5均可。得到的值可以为“正例置信率”,也可以作为正例的概率。我们的学习目的是找到 θ ,使logistic( θTx )在label为正的时候值接近1;同理,在label为负的时候,logistic( θTx )接近0。上述等价为:label为正, θTx≫0;label为负,θTx≪0 。我们用图来形象的表达:
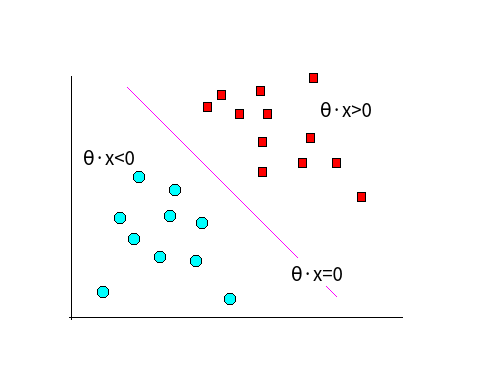
我们的任务就是找到一条直线使得所有点都尽量远离该直线。怎么定义所有点都尽量远离呢?我们着眼与离线最近的点,它们尽量远离即可,而不是全局最优。关于这点我们后面讨论,这有点结构风险最小化的意思。
数学分析
先来数学上形式化表示远离程度。
一般有两种思路,但是本质是一样的:
函数间隔
之前也说了,我们要label为正时,
θTx≫0;label为负时,θTx≪0
,即
yi⋅θTxi≫0
。记:
γ^i=yiθTxi
综合我们之前说的要离线最近的尽可能远,即置信率低的尽可能高,所以我们考察的函数间隔为:
γ^=mini=1,2,...,mγ^i
我们省去了0次项的书写,因为x为扩展形式, x=[x 1]
几何间隔
直观来看,就是点到直线距离尽可能大,如图:
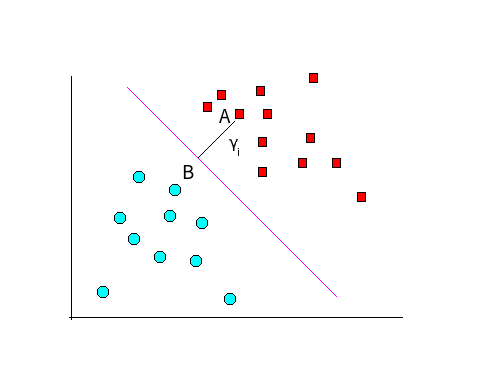
我们通过向量运算解得B点坐标,再带入
θTx=0
即可。直线方向向量为
θT
,单位法向量为
θ/||θ||
,所以B点坐标为
xi−θ||θ||γi
带入公式,为:
θT⋅(xi−θ||θ||γi)=0
解得:
γi=θTxi||θ||
同理定义几何间隔:
γ=mini=1,2,...,mγi
可见函数间隔和几何间隔其实是一个东西,只是几何间隔是函数间隔的归一化。
γ=γ^||θ||
变成规划问题
现在用数学形式化的表达整个问题—–在满足分类条件的情况下使得间隔最大:
max γ^||θ||s.t. yi⋅θTxi≥γ ,i=1,2,...,m
但是 γ 不是凸函数,所以改写成:
min 12||θ||2s.t. yi⋅θTxi≥1 ,i=1,2,...,m
上式转换,解释为:目标函数为凸了,令 γ^=1 。之所以能这么令,是因为 γ^ 和 θ 同步变化都满足解。问题已经明了了,接下来就是怎么解了。















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









