






简介:
基于上下文的渐进式深度图像压缩(Progressive deep image compression (DIC)),目的是在可变比特率的情况下联合最大化压缩对于多个上下文或任务的效用。这篇文章提出了一个基于掩膜的残差增强渐进式生成编码(RMPGC),来控制率失真分类感知的表现。实验表面所提出的RMPGC比现有的基准DIC在6个指标上的分类,失真与感知都更优秀。
DIC的优点:能够有效地学习给定任务/上下文最重要的潜在特征,并在有损压缩期间更好的保留它们。这篇文章把DIC方法分为两类,基于编码器的和基于潜在的。基于编码器的方法在每次反馈条件改变的时候都编码不同表示。基于潜在的方法会编码一个结构化的潜在表示,即潜在表示会通过网络一次生成,然后用于对各种反馈条件的快速适应。本文研究的是基于潜在的DIC。
问题陈述:设计目标是设计出一个可以运用于混合上下文的图像压缩框架。这个混合上下文的意思是让图像获取多种上下文信息,而不局限于图像压缩或是分类的方法。而且方案也应该是速率自适应的,不同比特率下不需要重新训练。
本文的贡献:
- 提出了一个RMPGC方案,结合空间掩膜机制,基于残差的分层机制,潜在空间中的上下文重要性估计。这样可以利用可变比特率和不同上下文目标来编码图像。
- 系统性的研究了率失真分类感知的权衡(RDCP),研究了三针方法参数化控制RDCP权衡:损失函数加权,空间掩膜混合,分层速率分割。表明所提出的RMPGC编解码器具有超参数空间,可以有效地操纵RDCP权衡。
II. RELATED WORK
A. 单上下文的DIC
DIC针对像素级的MSE进行优化,把每个像素都视为同样重要。主要是GAN和VAE的方法。
B. 混合上下文的DIC
混合上下文的例子就是同时考虑图像压缩和分类,既要保证通过神经网络后提取的特征能被用于分类,还可以被用于高质量重建。那么这个不同的上下文就需要权衡,是更多的考虑重建还是压缩?
C. 比特率自适应的DIC
比特率自适应的DIC实现起来是有难度的,实现目标是要构建一个紧凑且统一的DNN模型,让它具有显式的比特率控制机制,它进一步可以分为两种:基于表示的方法和基于量化的方法。
基于量化的方法:通过不同的系数对潜在向量进行缩放,使向量落入不同的量化区间。或者操纵拉格朗日系数和量化间隔来获得可变比特率。基于量化的速率自适应技术不能促进对潜在表示的深度优化,并且通常不支持上下文感知自适应。
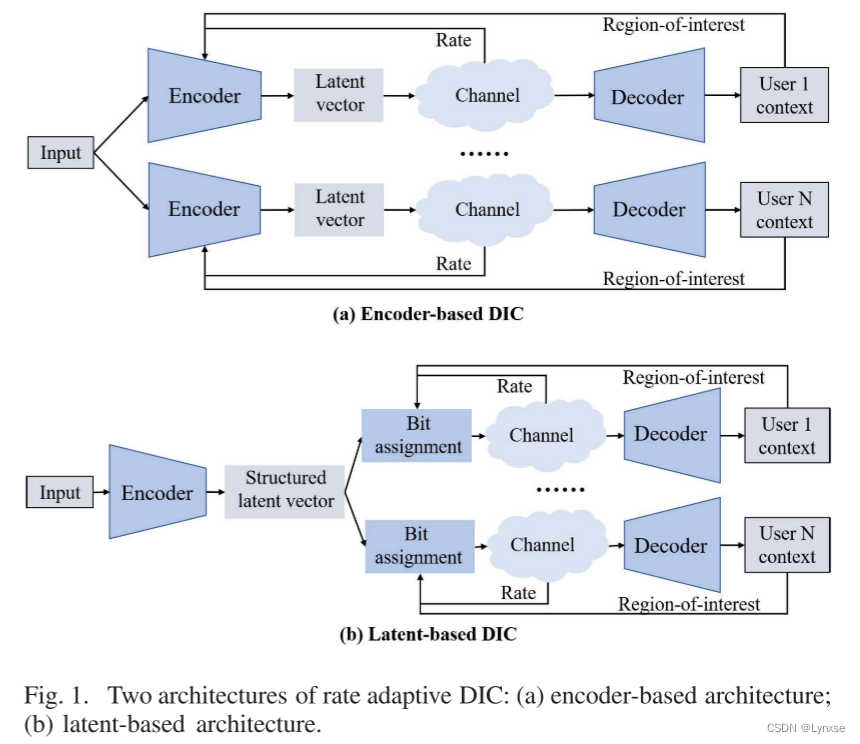
D. 比特率和上下文自适应的DIC
图1展示了两种比特率和上下文自适应的DIC,即基于编码器的框架和基于潜在表示的框架。本文重点研究基于潜在表示的框架,它又可以分为两种:基于层的方法和基于空间掩膜的方法。第一种方法将原始图像转换为具有有序依赖性的分层潜在向量。那么就可以通过传输层的数量来实现比特率变化。第二种方法利用不同空间通道中的潜在表示冗余。在给定目标比特率的情况下,用空间掩膜来调制通道。
III. GOAL AND INTUITION OF PROGRESSIVE DIC DESIGN
A. 通信友好的DIC潜在表示
图2展示了不同的通信友好编码的基本原理。可变比特率这种方法下,编码器所生成的潜在向量被解码器整体接收,主要是通过将量化技术运用于潜在向量,而非潜在表示的结构。
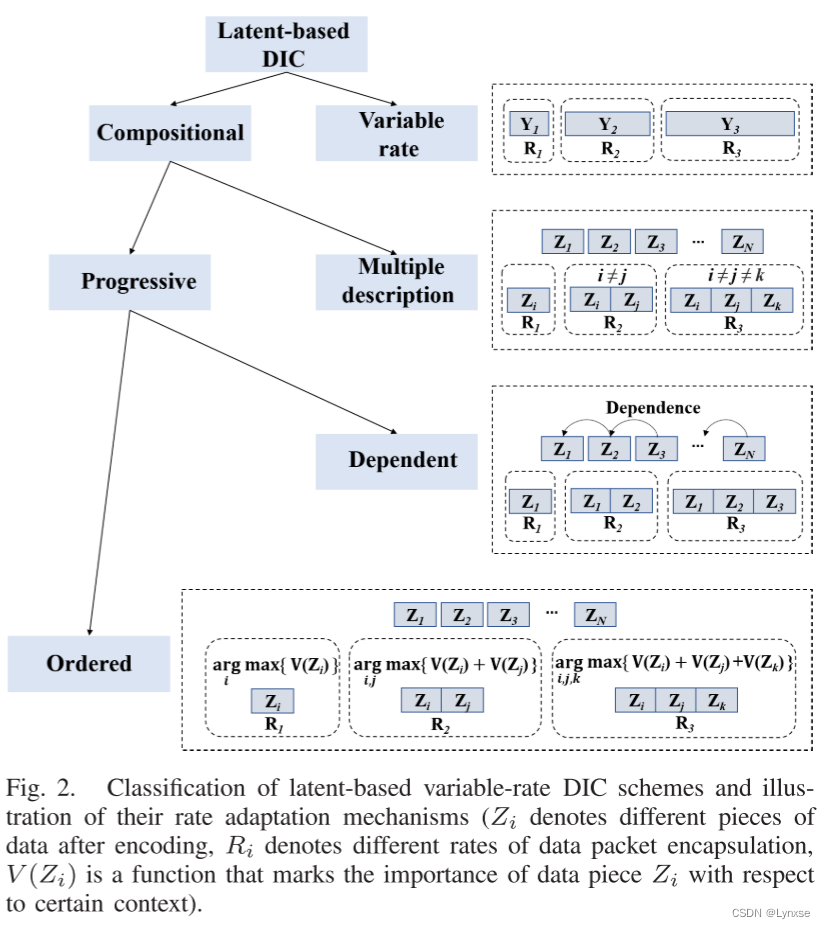
相比之下组合编码方法更侧重设计潜在空间的向量,图像会被表示为相互有关联的小块数据,这个潜在向量有多个层次,每个子块也都包含有其自身的属性,包括数据率、对其他数据片段的依赖性,以及在不同上下文目标中的相对重要性。如果给更多子块,那么重建性能就有提升 。
这篇文章使用的是渐进式的压缩。潜在表示可以被设计为适应不同的上下文目标。其次,从可靠传输的角度来看,通过精心匹配源的重要性与不同层次的信道编码,可以共同优化源编码和信道编码。这意味着在有损信道中,上下文相关的信息能够更好地受到保护。最后,从传输延迟的角度来看,在流式传输或分组调度中,具有较高重要性的数据片段具有较高的优先级。这意味着可以减少感知到的传输延迟。简而言之,在渐进式图像压缩中,具有组合和有序的潜在表示是有利于通信的。
B. RDCP权衡
失真-分类/感知是深度图像压缩中的重要问题,作者在这舍弃了先前文章中建立的严格DCP权衡,因为它不适用于DIC,因为它只对解码器优化,而我们的压缩显然非常需要考虑编码器所实现的压缩效果。同样考虑联合优化,就需要在DCP的基础上加入对比特率的权衡,形成RDCP问题,即同时包含经典的RD优化和DCP优化问题。
C. 假设和高级方法
对于RDCP的权衡问题,就需要去搜索到最佳的编码器-解码器对。但这个比较困难,所以做两个简化假设。首先是基于模型的方法,把优化问题简化为在提出的DIC模型中搜索最优参数。其次,单纯的追求图像的高质量并不会强加任何的比特率要求(即一味地追求高质量,忽略图像的大小问题)。所以考虑比特率分配的时候,关注失真和分类的权衡。总之,探索方法包括三个步骤:
- 选择编码比特率R
- 用超参数生成失真和分类之间不同比特率划分策略的模型
- 训练与DCP相关的加权损失的DNN模型
具体的方法是通过参数化模型来权衡RDCP,语义突出的地方应该赋予更高的优先级和更多的比特数来用于编码。其余区域因为在上下文中不太重要,就会产生高度失真,这就需要通过GAN来产生感知上的真实图像来抵消失真。
D. 框架和设计
首先给出作者提出的混合上下文渐进式DIC方案框架:

这个框架有三个模块:语义分析模块,基于GAN的图像压缩模块,自适应比特分配模块。
基于GAN的图像压缩模块能使得图像重建时具有更好的感知质量,GAN会将重建图像的统计数据和输入图像匹配。语义分析模块会对输入图像进行分类,并使用CAM获得的输入图像语义重要性的热图,热图会对应预测的类别。
然后,把热图拉伸到和潜在向量一样大小,把它定义为语义重要性图(SIM),在GAN输入得到潜在向量后,SIM可以与潜在向量交互实现语义感知的DNN训练。在输入图像经过编码器后,还会计算一个潜在向量复杂度映射(LCM)。LCM会被计算为潜在向量沿着通道维度的方差向量。根据目标比特率+SIM+LCM,会生成一个二进制掩膜,把它应用于量化后的潜在向量。并把掩膜后的结果与掩膜concat后,转化为比特流输出。
关于这里的CAM:特征可视化技术(CAM)_cam可视化-CSDN博客
由于这里作者专注于两个上下文目标:图像分类和重建。在这里引入三种机制来实现渐进性能。接下来分别解释这三种机制。
(一)损失函数的设计+语义特征匹配:
输入图像x,经过编码器映射到潜在特征z,量化得到z_hat,发给解码器(GAN中的生成器)得到重构图像y,训练的时候会把x和y都是输给训练器计算损失。如果压缩K倍,那就是原图得到潜在向量
通常GAN的压缩会使用MSE损失和GAN损失,这里要考虑到语义信息到潜在表示,所以添加语义特征匹配项,该项度量了从原始图像和恢复图像中提取的特征之间的匹配程度。三个损失函数SFM,MSE,GAN分别对应分类、重构、感知的度量。
SFM的度量具体表示:
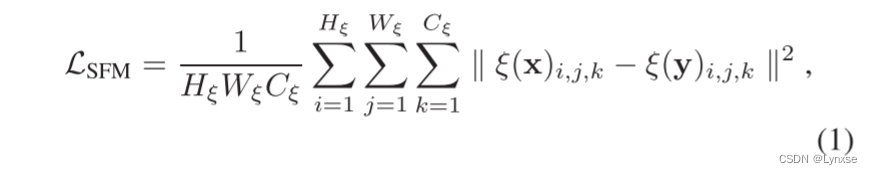
是预训练的特征提取器,它会计算原图特征提取和重构图像的特征提取的结果。(如果损失小说明特征提取没问题,可以用于分类)。
(二)空间掩膜和位分配
把掩膜运用到潜在向量就是一种渐进编码的思路,可以根据上下文目标不同生成不同的掩膜,首先由SIM来指示出每个元素的语义重要性,这是一种针对图像分类的掩膜。LCM则会测量通道区域的熵或复杂度,它对图像的重构也是必不可少的。
图4可以看出同一副图像的SIM和LCM的差别和对重构的影响:

SIM更关注猫猫头,因为猫猫头要用于分类它是什么,而LCM则关注整幅图像的背景和纹理,即它更关注重构细节 。那么把SIM和LCM混合就可以得到一个权衡后的结果。然后可以根据空间掩膜来分配比特数,实现渐进编码。
(三)基于残差的分层表示
如果给一个没有分层结构的潜在表示,空间掩膜更倾向于以低比特率产生隧道视觉图像(即图像被过度集中在某些区域,而其他区域的信息被丢失),为了解决这一问题,采用了基于残差的方法,以生成具有分层结构的多尺度潜在向量。多个层次的潜在向量被逐渐堆叠在一起,每个上层可以被看作是较粗和较细尺度之间的残差解决方案。也就是说,底层用于重构原始图像的近似,而每个上层的添加逐渐对图像进行细化。通过将上层的残差逐渐叠加到底层,图像的逐层细化效果逐渐增加。需要注意的是,虽然采用了基于残差的方法,但是这一方法是在整个图像上应用的,没有引入空间注意力。这意味着对于整个图像,残差逐渐添加,而不是针对图像的局部区域。
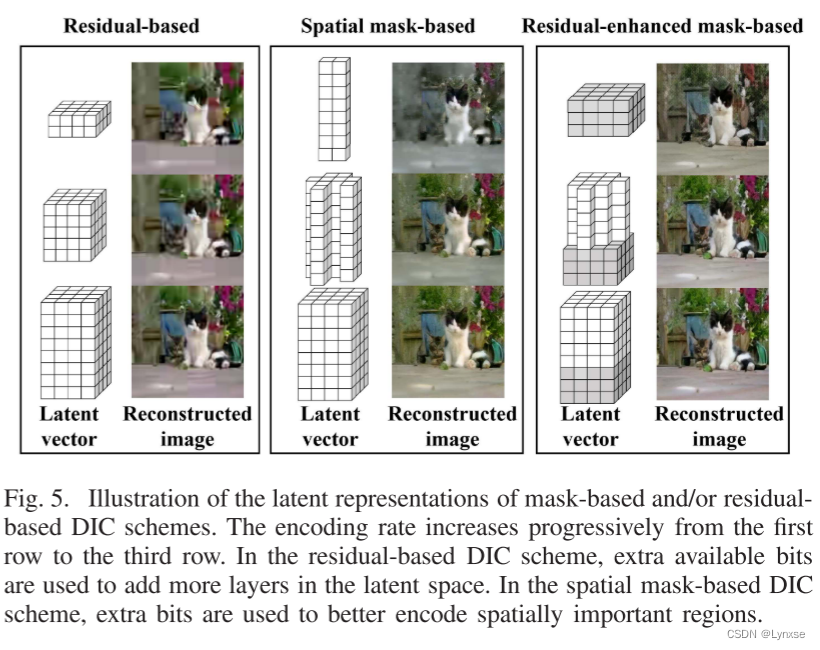
所以作者把分层和空间掩膜结合起来,产生RMPGC,RMPGC分层堆叠进一步划分为基本层和增强层。这个划分由超参数引导,它会指示多少个低层为基本层,然后对增强层使用空间掩膜,而基本层保持不变。这种划分意味着一种两阶段的比特率分配策略:第一阶段是使用超参数为基本层分配最小比特率,接着第二阶段使用空间遮罩进行更细粒度的比特率分配。
上述划分是对多级层次掩膜混合策略的一种简化,该策略为不同的层次分配不同的空间遮罩。理论上,这样的多级策略更加灵活,但存在两个缺点。首先,DIC模型难以训练和收敛。其次,传输多个遮罩作为辅助信息将导致显着的开销。对于多级RMPGC的可能扩展留待未来工作。此外,需要注意的是,RMPGC的三维潜在结构与中展示的结构不同,后者使用了多级量化而不是空间注意力。
(四)比特率的控制
在定义了以上部分后,就需要关注比特率的控制了。首先由一部分的超参数来决定比特率的范围,原始图像的缩放倍率K,潜在向量的通道数C,基本层的分层参数Cb,在训练之前就会确定好它们,来限制码率范围:
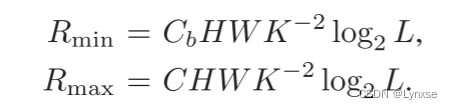
可变比特率还需要空间掩膜技术的比特数分配,它会以![]() 为最小步长来实现可变比特率,L是量化级别。
为最小步长来实现可变比特率,L是量化级别。
论文实际上就是专注于RMPGC的实现。
IV. IMPLEMENTATIONS OF THE PROPOSED PROGRESSIVE DIC
A. 生成性压缩网络
生成性压缩网络的基础在最小二乘GAN的基础上构成,即LSGAN。使用多尺度鉴别器交替的训练多尺度鉴别器和生成器。目标函数如下:
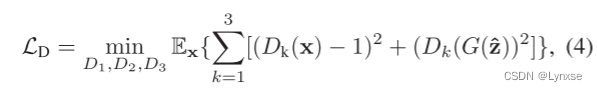
Ex是每个批次的经验平均值。Dk是第k个标量的判别符,鉴别器训练后,对编码器和解码器训练来解决率失真优化问题:
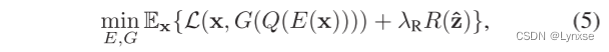
是原始图像的潜在表示的比特率。失真项是MSE损失和GAN损失的加权和,写为:

最终损失会由这些损失加权得出,至于具体加权多少,就根据你需要的上下文目标来给了。
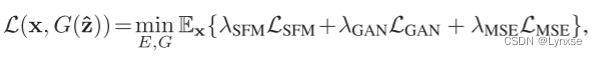
对潜在表示的额外处理:
对于,i是高度索引,j是宽度索引,l是通道索引。在固定i和j的情况下,来去计算它沿着通道维度的经验方差:
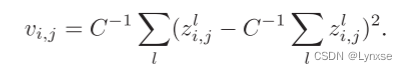
这个方差v会被用来衡量潜在表示向量的复杂性,这个方差将被用于确定的比特率,所以使用方差v的L1范数,也用作正则化。
为了解决量化不可微的问题,采用给定量化值中心,然后最邻近赋值来计算为:
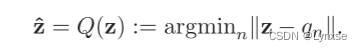
具体训练中,采用软量化来近似:
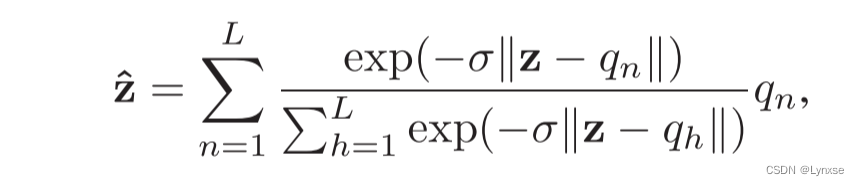
用于控制逼近程度。
B. MPGC的实现
这部分来解释自适应比特分配和网络训练的实现细节。
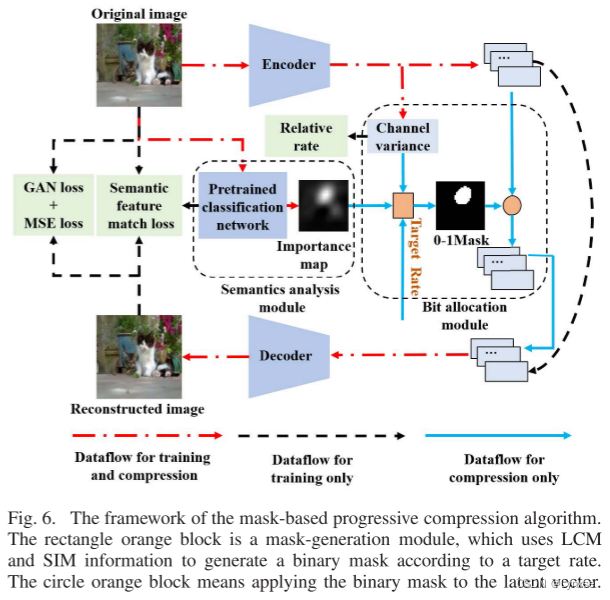
基于掩膜的可变比特率分配:
掩膜是由SIM和LCM混合得到的,上一部分已经计算了方差v,如果方差较大,就说明这部分比较复杂,需要更多的比特数进行编码。融合SIM和LCM来获得掩膜的一种策略是加权和,但加权和不能保持语义重要性的完整性,即语义重要性的顺序会被LCM干扰。
所以提出了一种新的分层混合策略,首先,将潜在向量空间分为两部分:语义显著区域和非显著区域。这种二值化划分是对SIM向量运用OSTU方法得到二进制向量实现的。1代表语义显著,0代表语义不重要。再添加常量1来为区域分配1-2的重要值。
非显著性区域从归一化的LCM中取值,它的范围是0-1之间,那么分别保留了SIM和LCM的原始顺序,它们分别在语义显著性区域和非显著性区域。SIM记为e,LCM产生方差v。上一段中OSTU产生的二值化掩膜记为B。最终的重要性图记为:

根据重要性图和给定比特率,还可以得到二进制掩膜M:

T就是根据目标比特率获得的一个自适应阈值,根据二进制掩膜的特点,可以把潜在向量变换得到:

对于得到的结果,再量化它得到(
![]() )对于这些
)对于这些,第一个通道的值全部保留,提取,而对于其它值,仅提取Mij = 1位置的值,然后把所有提取的值组合成一个向量。从
提取的掩膜和矢量会被进一步送入算术编码器AAC进一步压缩,然后接收器恢复潜在向量并重建图像。P和S分别是掩膜M中的所有元素数目和1的数目,r是BPP的目标码率,就可以得到:
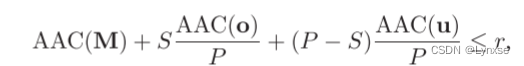
AAC表示使用AAC计算输入向量bpp的计算,o和u是M的所有元素都为1和0时从提取的向量,那么上一式就可以重写:
![]()
其中P,AAC(o),AAC(u) 是固定的。AAC(M)和r以及ACC(u)相比微不足道,所以S可以近似:

所以在给定期望比特率r,上式就给出了重要性图中要选择的元素的数目,也可以算出阈值T,所以就选择了I中S最大的元素。
小结一下:
这一部分有些乱了,稍微整理一下:
这里介绍的是第一种方法
首先原始图像先进来到编码器,生成潜在表示向量,对于潜在表示向量可以计算通道方差v,并用于估计比特率。潜在向量随后送入编码器重构,得到重构结果,再用一个与训练的分类网络让它对比结果,得到SFM损失和重要性图I,并计算MSE和GAN的损失,来指导网络尽可能的生成更高质量的图像。
我的理解是,在这里生成器充当了解码器的角色,它们应该是一个东西。在公式4中,最小化判别原始图像的值+判别生成器生成的重构图像的值,通过最小化这两部分的平方,即让原始图像判断趋于0,而生成图像趋于1,让判别器更好的区分真实原始数据和重构数据。
结束判别器训练后,启动编解码器的训练(LSGAN是交替训练的), 对于编解码器,就是熟悉的率失真优化,比特率的估计后续说明,失真由三部分组成MSE,GAN,以及SFM,SFM是前几节提到过的分类损失,即让原始图像和重构图像都经过预训练网络,看它们是不是能被判别为同一类标签(这里图7写的不清楚,没表达出这个意思,但文中有写。)
关于比特率的计算,是通过对潜在向量的通道计算方差,就是式(9)表现出来的结果,即方差越大,内容越复杂,比特率越大,相比于去计算其概率分布来得简单直接的多。(也许吧)。量化问题是通过软量化解决的,软量化通过使用指数函数来“柔化”最近邻分配,使得近似过程可导。这样,可以在反向传播中计算相对于输入 z 的梯度,以进行端到端的深度神经网络训练。
总结一下我的理解,encoder和decoder这一对网络实际上起到了生成器的作用,然后用公式(5)来指导这个网络,而其损失计算又与判别器判别的结果有关,这里就对生成器和判别器建立起了联系,判别器的训练是重构图像结合原图的判别结果,它使用另一个损失函数来指导。那么整个训练过程就很清晰明朗了,就训练这么多,这种方法不考虑别的。掩膜是在压缩的时候才考虑。
接下来训练完成后,转入压缩模式分析它的过程:
压缩模式仍然一样,让原图送入编码器,压缩为潜在表示向量,同时也要计算通道方差v,这个方差在后面会被用于计算出LCM。然后也一样计算SFM,后面在重要性图里会用到它,原始图像通过语义输出模块输出语义重要性图SIM。而可变比特率分配的掩膜就是由LCM和SIM来共同得到的,但仅仅对它们采用加权显然是不足够的,于是采用了这种方法:
SIM通过OSTU模块,输出一个二值化矩阵B,语义显著性区域为1,非显著性为0,这样就让然后对SIM再加个1,并乘上掩膜,过滤掉非显著性区域,即显著性区域分配1-2的值。再通过LCM,对非显著性区域分配0-1的值。所得到的矩阵记为I。
![]()
现在实际上已经得到了重要性图,但是进一步的掩膜操作还需要决定到底保留谁舍弃谁,即最终仍然需要转化为0-1的二值掩膜M。而M就需要通过一个阈值来确定,让I和目标对比一下,比目标比特率大,保留,否则另做处理。这个自适应阈值T会在后文说明。
然后就来看它是如何实现舍入的,如果掩膜是1,那么完整保留这个潜在向量的所有值,如果为0,就说明它不是那么重要,就可以对这个位置的向量做一个修正,取所有潜在通道的平均值,实现了一定的压缩。那么后续就是把它传入算术编码进一步无损压缩即可。
![]()
接下来就是目标比特率的问题:
目标比特率r(它是bpp的目标)应该要比式子(15)来得大,掩膜M中为1的个数,以及M中的所有元素总数,(说白了,P是M中的0和1加起来的个数,S是1的个数,P-S是0的个数)它们都要输入到AAC去计算它们在实际熵编码中耗费的bpp。
式子(15)的三项分别是掩膜M编码后的结果,对M为1部分的向量编码后的结果,对M为0部分向量编码后的结果。每个结果都代表这一部分的bpp,但是对最后两项做了一个加权处理。
然后M的编码bpp相比之下其实可以忽略,所以可以把这个式子重写为关于S的式子(17),那么在给定比特率的情况下,它就要去权衡S的数量,也就是由此来卡住T,让阈值设置到能选择到S个最大的元素保留原始值而不被通道均值化处理。
至于训练,由于这种方法不考虑掩膜的训练过程,即第一种训练方法MPGC-1,它的生成器损失函数应该如下,就是刚才分析的率失真用于生成器,分析的没问题应该:
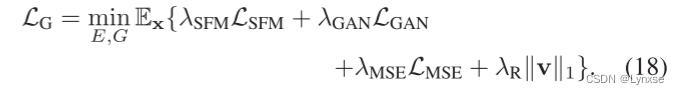
后面的这周有空再更新吧,这篇文章确实要慢慢看,量太大了。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









