






文章标题:LVQAC: Lattice Vector Quantization Coupled with Spatially Adaptive
Companding for Efficient Learned Image Compression
文章地址:
文章简介:
端到端图像压缩的文章为了设计的简化考虑,通常都采用标量量化,但实际上矢量量化器应该才是更优秀的,因此作者设计了一种格型矢量量化方案(Lattice Vector Quantization scheme )并结合空间自适应压扩映射(a spatially Adaptive Companding mapping),整体缩写为LVQAC,在实验后表现出了比标量量化器更好的效果。
一、介绍
端到端优化的图像压缩框架使用标量量化器其实就是出于操作方便,因为把矢量量化用于端到端框架联合优化会有一个问题,矢量量化(VQ)是一个离散决策过程,这就和端到端框架的反向传播不兼容。作者提出的LVQ解决了这个问题,LVQ可以利用特征间的依赖性实现量化,而且计算还很简单。此外作者还提到了即使压缩后的特征是统计独立的,LVQ仍然比标量量化更有效。因为它提供了更有效的高维空间覆盖,就像球填充、格和群理论证明的一样。
同时,为了提高LVQ对信源统计的适应性,将空间自适应压扩映射与LVQ结合。
二、对过去学习图像压缩的回顾
对于端到端图像压缩框架的回顾和问题公式化部分就不再赘述了,老生常谈的问题。直接看量化部分。如果使用标量量化器,那么得到潜在表示后就应该直接四舍五入获得整数:
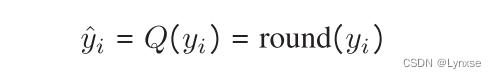
然后又是经典的问题,标量量化导数处处为零,阻断反向传播,所以是添加均匀噪声来替代量化的,而这也是最常用的方法:
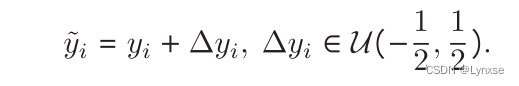
三、LVQAC的设计
3.1 Lattice Vector Quantization
从公式看起吧, 是n个线性无关的向量,它们一起构成了一个生成格
的基,而整个
是由以下形式的所有点组成:
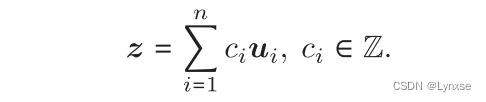
把生成基合起来记为,
,那整个晶格这样定义:
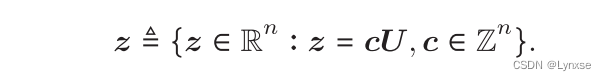
每个维诺胞(Voronoi cell)的格型点都可以定义为:
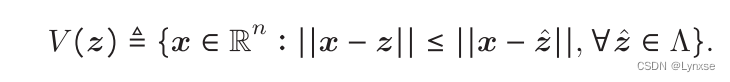
这就是LVAQ的结构了,LVQ码子则是具有相同大小和形状的维诺多面体的质心。图里给出了正方形晶格和六边形晶格的例子以及它们的维诺胞,这是它们的生成矩阵:
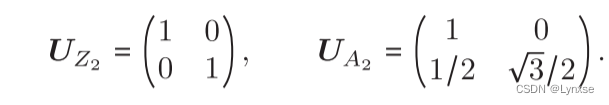
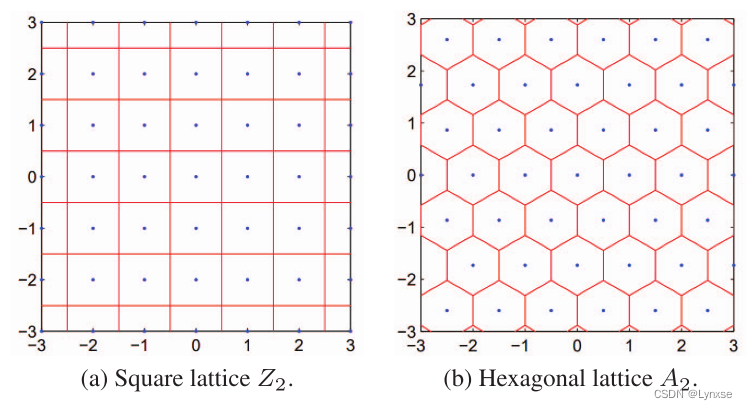
这个正方形的晶格就类似四舍五入的标量量化,六边形这个稍微复杂一些,它应该是二维空间中最好的矢量量化晶格,但对于要量化的特征向量,这里的维度是远高于2的,因此选择金刚石晶格来作为这里的结构。它的生成矩阵是这样的:

而它的二维例子是这样的:
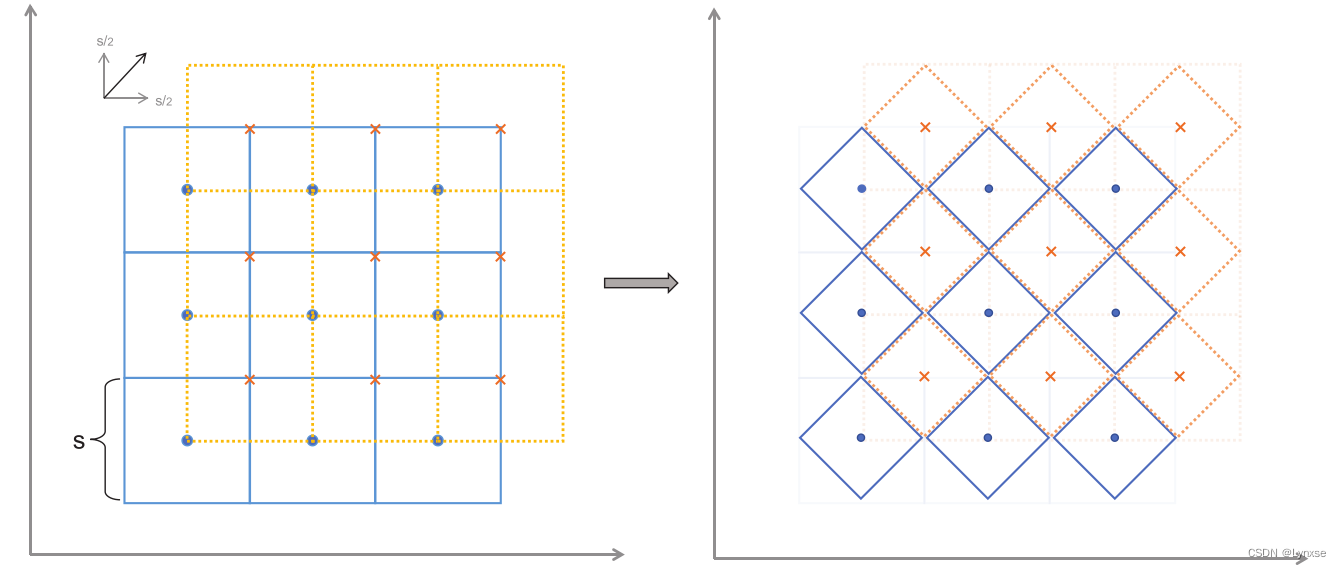
对于二维金刚石晶格,它有两个码本,第二个码本是通过对第一个码本移动1/2量化步长实现的。它的具体操作也和传统的矢量量化不同(传统方法是计算z与所有质心的距离,然后选择最近的那个),在这里它就基于两个码本对z进行两次量化,和
, 然后选择更近的那个作为结果,就是取一个argmin:
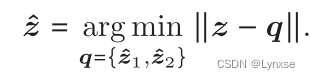
同样的,为了解决argmin与反向传播不兼容的问题,还是得用软松弛:


我没有研究过软松弛是什么东西,有点懵, 这里的就是softmax函数,我的理解是让它们的距离通过softmax来计算出概率值,再用概率值作为权重指导最终的值重建。
作者还提到了关于要传输额外信息的问题,因为除了传输量化表示的索引外,还要传输额外比特来指示所选择的码本,每组固定二维空间位置的码本所有通道共享一组码本,即对于h*w*3大小的图像,它的潜在表示大小是h/16*w/16*c。码本选择信息大小是h/16*w/16,精度是一比特,产生的比特率可以忽略不计。
3.2 空间自适应压扩映射
压扩映射函数是通过学习不同空间位置产生不同的压扩函数,为了降低学习难度的同时保证推理速度,将压扩限制为A律函数:
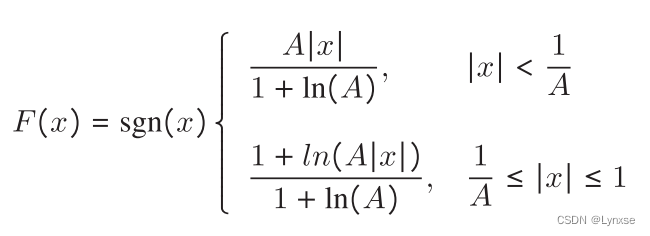
 由于A律函数连续可导,所以可以直接嵌入到端到端优化框架里。
由于A律函数连续可导,所以可以直接嵌入到端到端优化框架里。
所以A怎么来?用神经网络:在这里,在不同的尺度参数A用于不同的空间位置,通过一个卷积网络h,让a = h(y),并把学习到的对y处理,使其缩放到理想的一个动态范围以获得更好的量化性能。解码后则执行逆A律把它压扩到原始值。
(原理看似几句讲完了,但知识储备不足真的看不进去,事已至此,先吃饭哦不,先看结果吧)
四、结果
4.1 一些基本的设置:
数据集:ImageNet中挑选出的8000张图片,然后随机剪裁到512*512,batch设置为16
优化器:Adam,=0.9,
=0.999
学习率:10^-4 ,迭代2000次后再设置为10^-5,再迭代100次
测试数据:kodak 24张和CLIC的41张
平台:Compressai
测试用的模型:Minnen2018和Cheng2020
拉格朗日λ设置:0.0016,0.0032,0.0075,0.015,0.03,0.045
结果展示:
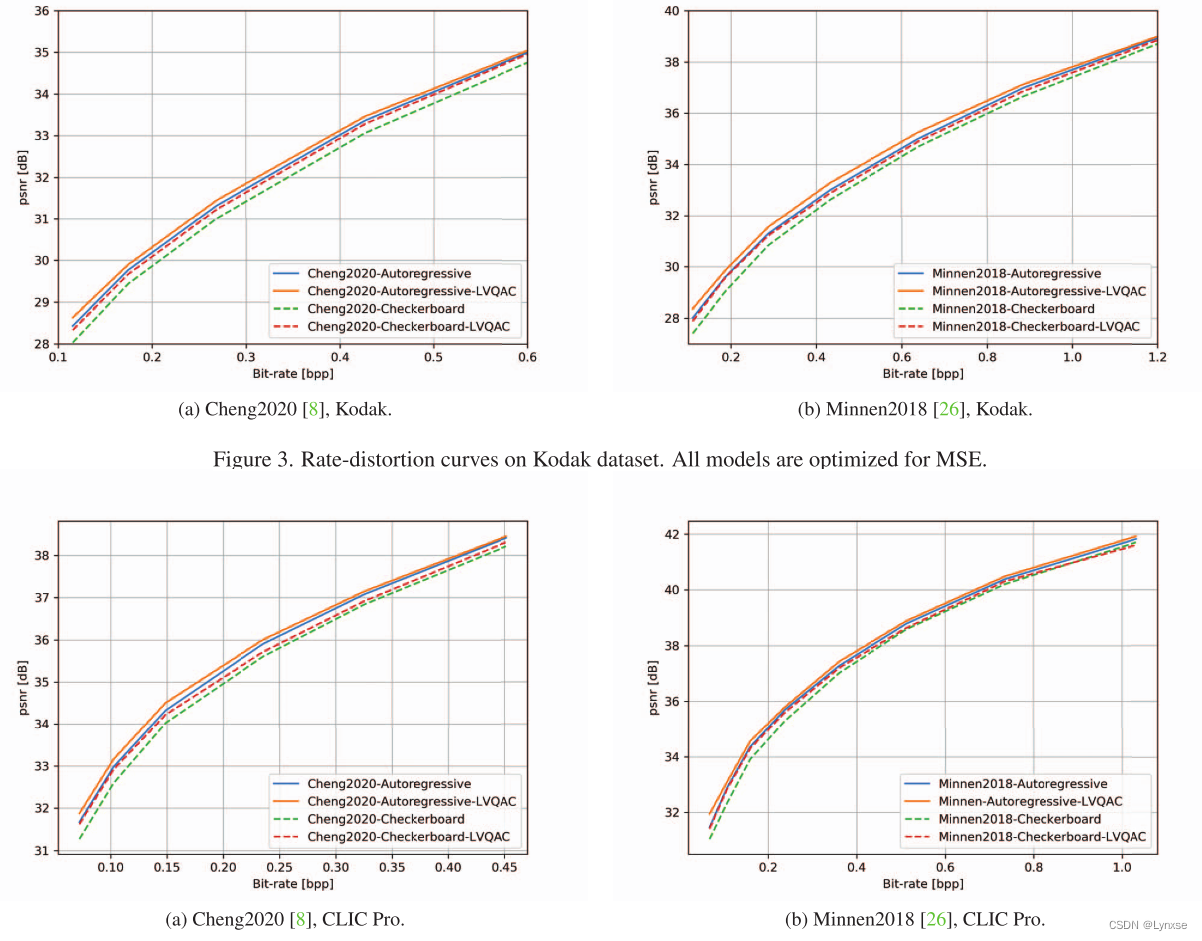
总结:通过把矢量量化结合进端到端框架,并对效果最好的两种模型进行了测试,都取得了完全胜利,很遗憾的是除了我没看懂,别的都挺好的,继续研究一下吧。















 4874
4874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









