






文章标题:
《Learned Image Compression Using Cross-Component Attention Mechanism》
简介:现有压缩算法都是针对RGB图像的,在YUV420图像上表现不佳,所以作者的出发点就是设计一种适合YUV420压缩的算法。
主要内容:
设计了基于信息引导模块IGU(information guided unit)和注意力机制的双分支高级信息保存模块AIPM(advanced information preserving module)。
双分支结构:防止原始数据分布变化,避免不同分量见的干扰。
信息引导模块:利用Y和UV间的相关性,用Y引导保留UV信息。
自适应跨通道增强模块(ACEM):利用不同分量的关系重建细节。
具体一点来说,APIM用双分支保护原始数据的分布不被破坏,并且对不同的部分分配不同的注意力得分。利用IGU模块来建模Y和UV之间的关系,因为Y本身包含的信息其实更多,所以IGU根据注意力机制来使用Y的信息作为UV分量特征提取的先验和指导,更好的保护了UV的信息。
同时加入自适应交叉通道增强模块ACEM来提高重建图像质量,重建的Y分量和IGU提取的注意力图同时用于UV的质量增强。
为了避免上下文模型的浮点运算出现跨平台解码错误,提出了一个固定点量化方案。
背景和研究现状不再赘述,直接看第三章作者的模型:
A. 问题的公式化:

这里应该就是对超先验的问题公式化, 率失真问题也是一样建模:
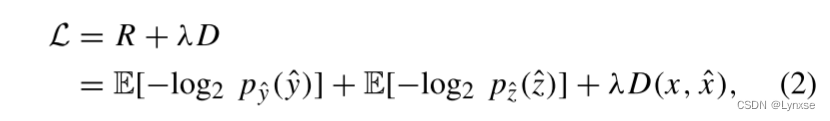
关于为什么YUV420的压缩框架会出现信息丢失的问题总结:
- 编码过程是特征提取过程。在此过程中,去除图像的信息冗余,保留重要信息,可以有效地提高率失真性能。在编码过程中,为了提高压缩效率,需要将更多的比特分配给复杂的区域。如果编码过程不能有效地去除图像中的信息冗余或将注意力分配到复杂区域,就会出现信息丢失问题,导致率失真损失。因此,我们需要去除信息冗余,并有效地分配比特,以实现信息保存,避免信息丢失问题。
- YUV是根据人眼的视觉特性设计的,Y会保留人眼感知最明显的亮度信息,它也保留最多纹理和结构信息,直接套用RGB压缩的框架就会忽略Y分量和UV分量之间的关系导致信息的丢失。如果充分利用跨通道信息,才能实现更好的效果
AIPM和ACEM的目标:用亮度Y指导色度UV
B. 信息保存框架:
双分支:防止数据分布变化。
FAB:注意力机制,分配更高的关注度给复杂区域。
IGU:通过跨分量的注意力机制实现Y到UV的信息流,体用Y的信息指导UV的特征提取。
ACEM:重建图像的质量增强
C.AIPM:

直接根据图来看,双分支结构会在一开始就将Y和UV分量分开执行输入和卷积操作,并且在Y分量完成卷积后送入信息引导模块IGU,把信息加入到UV特征中,得到信息保留的色度特征。两者都需要通过特征注意力模块,然后送入融合模块,把Y和UV的特征融合送到编码器。
其中,编码器由1*1卷积和PReLU激活函数组成,解码器部分设计分割模块来对应反融合模块的操作将特征分开。熵模型用GMM(Cheng2020那篇)。
1)信息指导模块:
如图b,信息指导模块同时接受四个输入,Y分量原图切割为四张一半分辨率的,UV分量原图不用切割,只需分开送入(UV分量本身分辨率就是Y的一半),还有Y和UV分量经过网络卷积后的结果也要分别送入IGU模块,随后将Y原图和UV原图分别点乘,相加,再softmax(这个过程就是经过ATT模块),得到的结果再与Y卷积后的结果切割的特征图进行哈德码积,积完后通道相加后,再把它加入UV卷积后的结果中,具体公式表示如下:
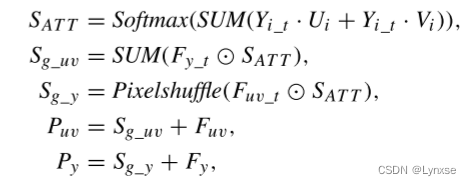
这个过程应该可以理解为通过融合保留数据的信息。并且作者还把IGU和BGU进行了对比,BGU更为复杂一些,它不仅让UV获得Y的信息来引导,还同时让Y获得了UV的信息。
2)特征注意力块(FAB):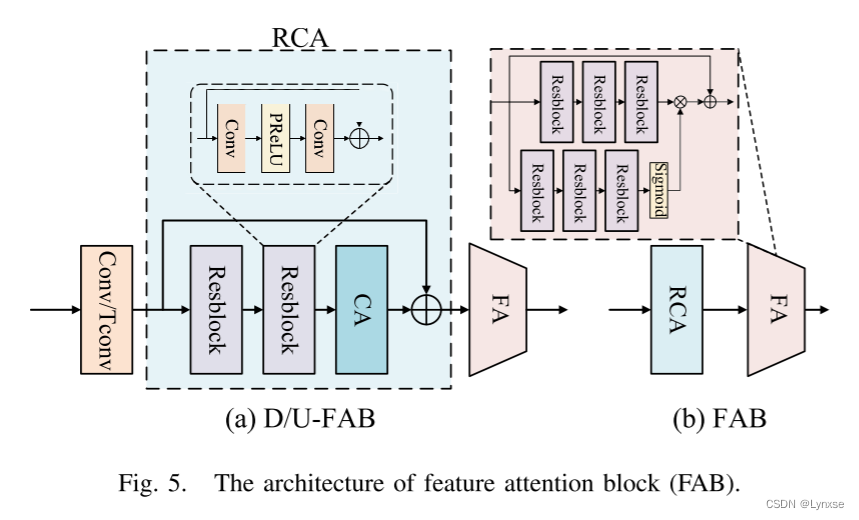
这个模块的设计目的是为了更好的保存亮度和色度分量的信息,不过由于Y分量之前没有采样过,所以为了与色度分量统一需要在压缩和解压缩时分别进行下采样(D-FAB)和上采样(U-FAB),整个模块由三部分组成,步长为2的卷积/转置卷积、残差通道注意力模块(RCA)和精细注意力模块(FA)。
RCA:两个残差块和一个通道注意力块(CA)以及全局残差连接组成。
FA :简化的注意力模块,通过残差学习进一步增加模型感受野,保留更多有效信息。
注,色度部分的FAB不需要第一步的卷积,直接进行高效的特征提取
D.自适应跨通道增强模块:ACEM

ACEM的作用根据之前的总体框架也可以看出,它利用IGU输出信息来指导最后图像的重构,首先是把Y过增强模块,然后分成四块,然后与IGU生成的ATT结果做哈德码乘法,生成一个引导图然后把Y分量和UV分量都和引导图叠加,送入增强模块,得到最终增强后的UV结果,在这里作者加了一个指示器指示是否激活ACEM,这个指示占两个比特,分别控制是否增强Y和增强UV。
E.上下文模型的量化方案
提出了一种后训练量化方法,利用卷积层代替掩膜卷积层,掩膜卷积层的权重被分给卷积层中的对应值,其次在上下文模型中每个模块插入观测器,来收集数据范围和量化参数,然后用训练数据集的一个子集校准来减少量化损失。最后,根据收集的量化参数来把上下文模型转化为量化版本。这个方法就是把上下文模型定点量化了,避免了如果跨平台导致的上下文模型量化一旦出错,因为上下文关系错误就会累计。
实验设置:
训练集:Vimeo-90K, 使用ffmpeg把它们转为YUV420格式
学习率:5×10^-5 衰减到3×10^-6
轮数:300万次,先对压缩框架迭代300万次,再进行100万次其他框架的迭代
损失函数:
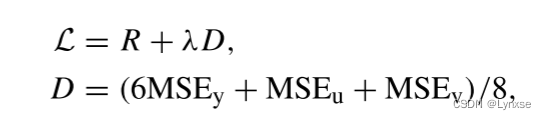
不同压缩率通过调整λ实现, 分别给0.06,0.045,0.03,0.015
上下文模型的量化通过pytorch的量化库实现8位量化(不懂),用训练集的一个子集迭代100次来校准,包含200幅256*256的图像。
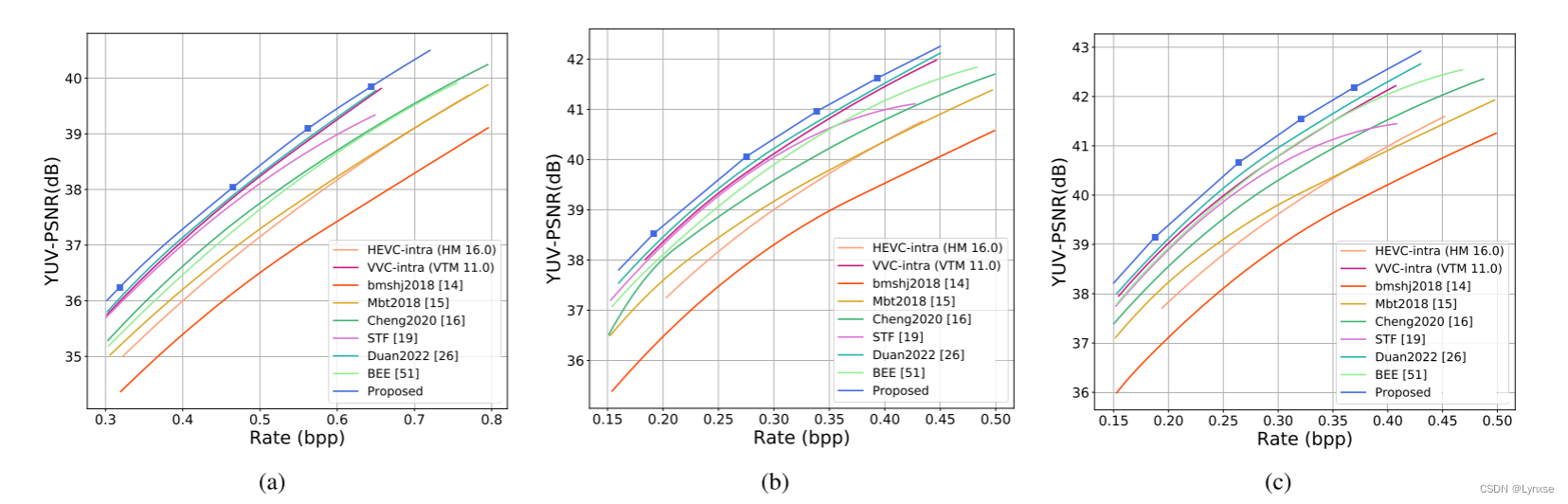
这个方案确实在YUV图像上取得了最好的效果。
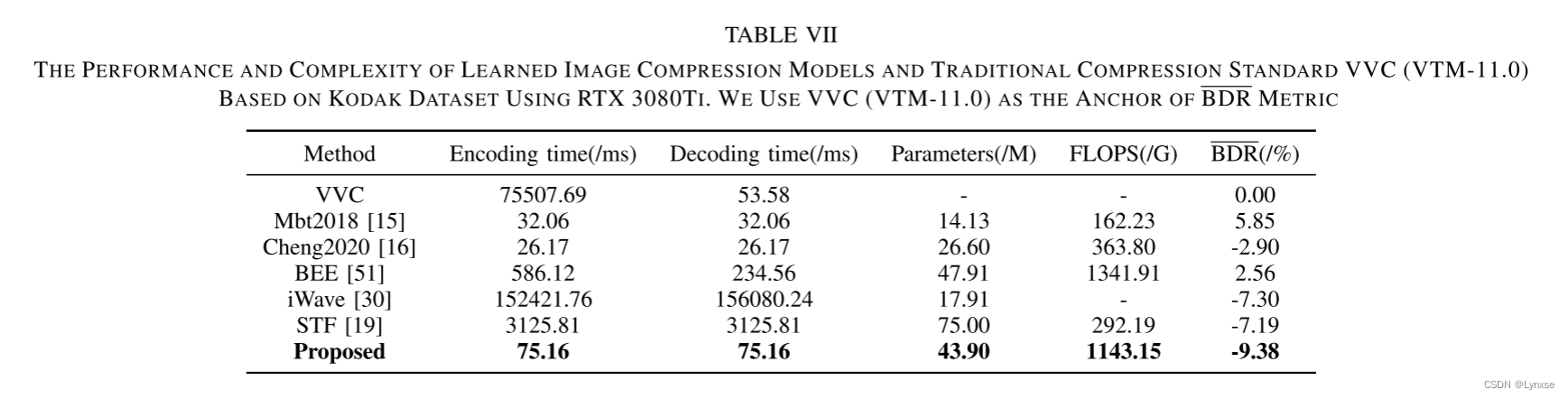

总结:从YUV角度考虑分量的相关性还是挺神奇但合理的,感觉利用提取某个分量的信息融合另一个信息的方法和ROI颇有相似之处,但还是老问题,一遇到量化就不懂了,总之是好文章,与大家一起分享学习。















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









