






文章标题:
《TransCS: A Transformer-Based Hybrid Architecture for Image Compressed Sensing》
发表于:IEEE TRANSACTIONS ON IMAGE PROCESSING
文章简介:
提出了一种新型的基于变换的混合结构实现高质量的图像压缩感知,记为(TransCS)。它通过训练图像来学习其中的结构信息以此实现更好的图像重建。设计了一种基于迭代收缩阈值算法(ISTA)的变换器主干模型,迭代使用梯度下降和软阈值操作建模图像子块的全局相关性,引入CNN卷积神经网络提取图像局部特征,然后用这个混合结构实现高质量的压缩感知的图像重建。
一、INTRODUCTION
压缩感知能使用低于奈奎斯特抽样频率的采样进行图像信号的采样和恢复来实现图像压缩。压缩感知的设计核心问题是 1)感知矩阵的设计 2)重构策略。
用公式来看一下压缩感知的表示:
![]()
A就是感知矩阵 ,而采样后的信号y就是对x在感知矩阵A下的投影,所以x的重构是一个欠定反问题(underdetermined inverse problem)。而这个问题可以通过优化问题来解决,即使用y对x重构:
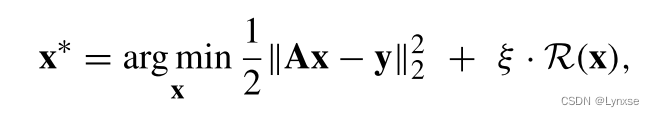
R是正则化项,是正则化参数, 左边包含argmin的项则是一个二范数平方来表示找到合适的x使其能产生最好的重构质量,说白了就是去重构出最好的x。有很多迭代算法能解决这个问题,比如要用到的ISTA,它的过程是这样:
![]()
是迭代步长,Fsoft就是收缩阈值函数,x的上标对应第k/k+1的迭代结果 ,Fsoft具体这样:
![]()
Fsgn是符号函数,z代表输入,T就是收缩阈值,整个函数说白了就是让它一直收缩吧。然而这个算法的问题是真的要迭代数百次。
基于块的压缩感知(BCS)一直被广泛用于图像压缩,将输入图像分块为B*B的像素块,然后逐个块压缩感知。这种方法可以在感知完成之前就先对投影的块进行编码和传输,加快了重建的过程,(我理解就是一边压缩感知,一边把已经投影好的块进行编码和传输)。但问题是只用了每个块的信息重建,导致块效应严重,性能也有限。(分块压缩的老问题了)
将深度学习与压缩感知结合也是自然而然的事情,CNN还能捕捉到图像的局部特征和全局位置信息,但仅用CNN也很难全面学习全局信息。要解决的问题就是如何学习到一个图像压缩感知框架,而且要让它能具有全局相关性的表现能力。
基于这个问题,作者就提出了基于变换器的混合结构压缩感知( TransCS),整个过程大致如下:
 首先对原始图像分块,再将块堆叠后作为输入进入压缩感知的采样,得到采样后的压缩结果后,再对其进行重构,重点就在于重构部分,它包含一个线性的初始重构模块和一个非线性混合重构模块 。其中前者是一个可训练的初始重建矩阵,混合模块则是线利用基于ISTA的变换器,捕获图像子块之间的全局依赖性来执行进一步的处理,并引入CNN捕获局部细节,以此提高性能。
首先对原始图像分块,再将块堆叠后作为输入进入压缩感知的采样,得到采样后的压缩结果后,再对其进行重构,重点就在于重构部分,它包含一个线性的初始重构模块和一个非线性混合重构模块 。其中前者是一个可训练的初始重建矩阵,混合模块则是线利用基于ISTA的变换器,捕获图像子块之间的全局依赖性来执行进一步的处理,并引入CNN捕获局部细节,以此提高性能。
作者的工作:
1)感知矩阵不是固定或手工设计的,而是引入一个数据驱动的采样模型的图像压缩感知。
2)设计了一个定制的基于ISTA的变换骨干网络,迭代的梯度下降+软阈值操作来模拟子块间 的全局空间结构。
3)提出了端到端的压缩感知混合架构,结合自定义的变换骨干网络+CNN辅助,实现高质量 的图像重建。
二、RELATED WORK
1)基于深度神经网络的压缩感知模型
现有的基于神经网络的压缩感知模型绝对多数都关注卷积来捕获图像局部特征,但这也导致建模全局关系时受到限制,而且这些模型的效率比较低,一直在用卷积层的堆叠,这就是作者要重新设计一个神经网络,使其学习图像子块间的全局关系的原因。
2)变换器(Transformer)
Transformer是一种新的结构,在经典编码器-解码器结构上进行了拓展,在自然语言处理(NLP)上有着最优秀的表现。不使用RNN或CNN来建模,而采用位置嵌入(PE)、多头自注意力(MHSA)和多层感知(MLP)的组合。

PE()是位置嵌入函数,Zpos和Zi分别代表输入的元素位置和元素维度,dim是整个Z的维度,q是(0~dim/2)的整数。然后MHSA使用H个单独的头进行投影,离散头分别被引导来Q(查询),K(关键字),V(值)。整个MHSA()的过程如下:

proj的每个h都是第h个头部的线性投影,d是输入维度,attn()表示缩放的点积函数,concat()是用于将头部的离散注意力拼接在一起的函数,拼接后得到输出。
三、PROPOSED METHOD
TransCS是一种端到端架构(这么巧你也端到端啊),先进行采样,采样的过程是可学习的。采样后再用这个基于ISTA的transformer+CNN来进行图像重构。TransCS具体流程如下:

如图,经过红色的线性初始化后,就要送入混合重构框架中进行迭代了。每个Stage中,Transformer被转换为具有两个CNN块的ISTA形式来迭代恢复图像。(就是图里的Preblock和Postblock)
具体的先来看每个模块吧
A. 采样模块
关键在于数据驱动的可训练感知矩阵。先将图像划分为C*B*B块,C是通道数,B*B是块大小。记![]() 为这个可训练感知矩阵,
为这个可训练感知矩阵,![]()
![]() ,所以采样率
,所以采样率![]() 。
。
整个采样过程用公式如下表述:
![]()
其中FB是分块函数,Fvec是平坦化函数,把块投影到矢量上去,再用学习到的矩阵A来进行感知采样。A的具体参数是通过训练图像反向传播后训练出来的,并最终遵循高斯分布。而且它最后会与重构模块联合训练来进一步提升性能。类似于CSNet,A会被约束为{0,1}之间,相比于浮点数,它显著地减少了存储空间。
B. 重构模块
1)初始重构模块:
利用一个学习到的初始重构矩阵来进行初始的重构,
被初始化为采样矩阵A的转置,也用反向传播训练,(A和
的梯度相似)。y就是经过采样后的结果,初始重构过程如下:
![]()
初始重构后的结果仍然存在很强的块效应,而且它还是欠拟合的,不过是能用较低的容量保持了图像的信息。所以还要让它过一个混合重构模块。
2)混合重构模块:
将基于ISTA的transformer和CNN集成开发,通过迭代并更新梯度下降和软阈值函数来引导transformer来解决ISTA的L1范数最小化问题。
具体来说,为了减轻训练负担,设计了一个函数,可以把输入剪裁为具有较小尺寸的不重叠子向量
,就像这样:
![]() 。那么对于它的最小二乘梯度下降就是:
。那么对于它的最小二乘梯度下降就是:
![]()
其中,和
分别是第k次迭代的输入和输出,
是第k次迭代的学习步长,步长是可学习的,第一次迭代时的
会先初始化为
。
然后,引入transformer中的主干中附加的卷积层Preblock来学习图像细节。Preblock可以表示为:
![]()
![]() 是平坦化的逆过程,
是平坦化的逆过程,![]() 代表6个堆叠的卷积核,大小3*3,步长为1,无偏置,通道数根据具体的分为1或32。
代表6个堆叠的卷积核,大小3*3,步长为1,无偏置,通道数根据具体的分为1或32。
原始的transformer是用于在机器翻译中获得嵌入词的自相关性开发的,这里则是将位置嵌入图像子块来作为压缩感知的输入序列。所以主干中的PE用来保留子块的位置相关性(指示位置?)所以它是一个常数矩阵。
这里先用![]() 将输入剪裁成不重叠的子块然后整形成向量。
将输入剪裁成不重叠的子块然后整形成向量。![]()
子块大小就是P*P,用Preblock学习到的结果来经过PE保留位置,并把位置加到执行元素加法:
![]()
得到PE后的结果就要让它过MHSA和FC层了:
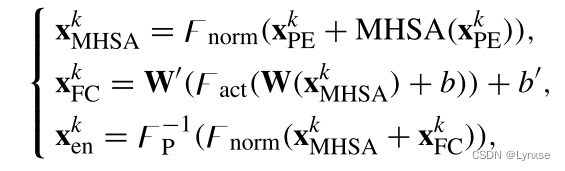
![]()
![]() 是权重矩阵,b是FC层的偏置,Fact是指数线性单位(ELU),Fp的-1就是
是权重矩阵,b是FC层的偏置,Fact是指数线性单位(ELU),Fp的-1就是![]() 的逆,即变换为原来的尺寸。
的逆,即变换为原来的尺寸。
软阈值之后就是编码器,编码器用![]() 代表,其实它就是上面两张图的加起来四个公式的结果,过软阈值是这样的:(软阈值就是开头第二个公式正则化的导数,不是很懂)
代表,其实它就是上面两张图的加起来四个公式的结果,过软阈值是这样的:(软阈值就是开头第二个公式正则化的导数,不是很懂)
![]()
软阈值即它不是固定的,而是在第k次迭代中通过学习来收敛阈值。解码也是类似的操作:
![]()
得到解码后的结果后,再让这个结果过另一个堆叠的卷积层(Postblock),一样公式化:
![]()
最后还是把图像块投影到了和输入的时候一样大小,这样也方便了直接送入下一次的迭代。
本来看到这里人已经彻底破防了,没想到最后作者直接给出了伪代码来直观查看这个迭代过程(好的文章确实不一样):

C. 损失函数
TransCS直接用均方误差来描述原始图像与重建图像之间的元素差异,损失函数可以表示为:
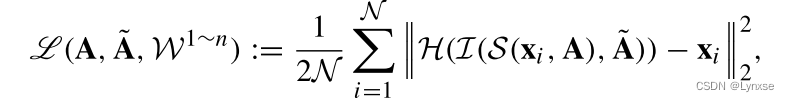
四、EXPERIMENTAL RESULTS
实验设置:
数据集:BSD 500 包含 200张训练集 100张验证集 200张测试集
所有图像随机剪裁成20个96*96的子图,即一共有100,000个训练子图像。
训练好后在Set5、BSD100和Urban100里测试出结果
和
分别设置为96和32大小,子块
大小设置为8,可训练迭代步长初始设置为1,其他设置也不细说了
训练轮数:200 batch是64,一样的后面的轮数学习率设置小一些。优化器Adam
TransCS采用了保护操作来避免过拟合,获得了较好的泛化能力。保存策略在每个训练时期之后通过验证来执行。确定是否保留训练模型的标准是验证数据集的丢失
结果对比:
所对比的结果也是比较先进的压缩感知方法,总的来说效果不错。

作者进行的分析还是很全面的,从鲁棒性、 不同比特率下的表现、模型复杂度多个方面进行了分析,有兴趣的可以仔细看看。以及附录有比较硬核的数学公式。
总结:讲的很到位,但我之前也没学过压缩感知的相关内容,所以也是一知半解硬着头皮看,但不管怎么说,这篇文章对于学习深度学习图像压缩+压缩感知还是很有意义的。















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









