






 本文介绍了一种新的数据压缩方法COMBINER,利用BayesianImplicitNeuralRepresentations(INR)和变分自编码器,通过学习对角高斯先验和后验,实现对数据的有效压缩,同时考虑了速率-失真权衡。文章还提出了迭代学习先验参数的算法以优化编码效率。
本文介绍了一种新的数据压缩方法COMBINER,利用BayesianImplicitNeuralRepresentations(INR)和变分自编码器,通过学习对角高斯先验和后验,实现对数据的有效压缩,同时考虑了速率-失真权衡。文章还提出了迭代学习先验参数的算法以优化编码效率。
文章标题:Compression with Bayesian Implicit Neural Representations
文章链接:https://arxiv.org/pdf/2305.19185.pdf
一、简介
本文通过将单个数据视为坐标映射到值的连续信号,训练一个隐式神经网络表示(INR)网络来进行编码其权重实现压缩。为了使其达到更好的效果,参考基于VAE的端到端压缩模型方法,把INR拓展到变分贝叶斯中,将权重的变分后验分布q过拟合到数据而非点估计。称之为贝叶斯隐式神经表示压缩(COMBINER)

图1:所提出的COMBINER框架
二、相关工作
1. INR网络(Implict neural representations)
将数据视为点集,其中每一个点都可以对应坐标信号值对
,并且过拟合小神经网络
,神经网络通常是由权重
参数化的多层感知机MLP来表示,这就称之为INR。最近研究中的压缩思路多为通过压缩INR的权重
,来起到压缩数据集
。但其存在的问题是假设
是均匀编码分布的,导致比特率的恒定,且只使用失真来作为损失函数,因此控制压缩率只能改变权重的数量,这显然不够合理,所以本文通过变分贝叶斯神经网络来解决这个问题。
2. 变分贝叶斯神经网络
引入先验,变分后验
,由此,信息内容可以由KL散度来度量:
,
如果失真度为,而要求比特率不超过
,则优化目标可以写为:
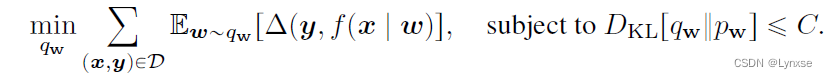
对于这样一个优化问题,可以引入松弛变量,优化它的拉格朗日对偶:
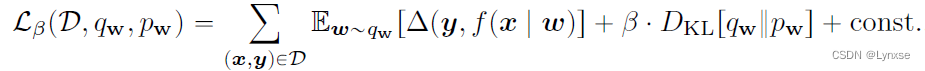
即通过优化最终的等式,就相当于实现了速率-失真的权衡优化。
3. A*相对熵编码
对单个权重样本,采用相对熵编码而非量化点估计来进行熵编码,在本文中,采用了深度有限的全局约束A*编码。
三、贝叶斯隐式神经表示压缩
在本文中,只考虑对角的高斯先验和后验
3.1 在训练集上学习模型先验
为了保证COMBINER的性能,必须在网络权重中找到一个好的先验,因为它作为A*编码的建议分布,直接影响编码效率。本文提出了一种迭代算法来学习先验参数
,这些参数将在训练集
上最小化率失真目标:

提出了一种坐标下降算法来优化等式中的目标,随机初始化模型先验和后验,并交替以下两个步骤来优化和
1. 优化变分后验:固定先验参数,使用梯度下降的局部重参数化技巧来优化后验,优化上述等式的问题可以分为M个独立的问题并行执行:

2. 更新先验:固定后验参数 ,计算
![]() 来更新模型先验:
来更新模型先验:
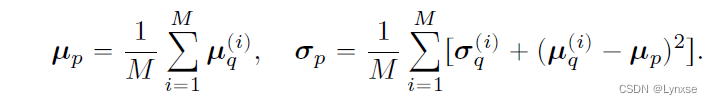
该算法的伪代码:
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









