







Chapter 8
神经网络的基础优化算法:
Algorithm 8.1

在训练停止的条件还未满足的时候,每次取出m个训练样本。对这m个样本采用最速下降法(先对cost function(一般是log-likelihood)求梯度,后根据梯度更新参数),直到训练停止的条件满足。
Algorithm 8.2

momentum算法的出现是为了加速SGD。它的思想类似于物理里面的冲量。物体在一段时间内运动的距离的长短不仅取决于这段时间内它所受到的作用力的大小,同时还受到了上一时间段结束时物体运动的速度的大小。同理,参数在一个阶段更新幅度的大小不仅取决于这个阶段cost function梯度的大小,也取决于上一阶段结束时参数更新的幅度。连续的向一个方向的梯度可以看做是对于一个运动的物体连续作用在一个特定方向的力,在这种情况下参数更新的幅度是最大的。但一般人为会为这个特定长度阶段参数更新的幅度设置一个上限: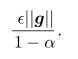
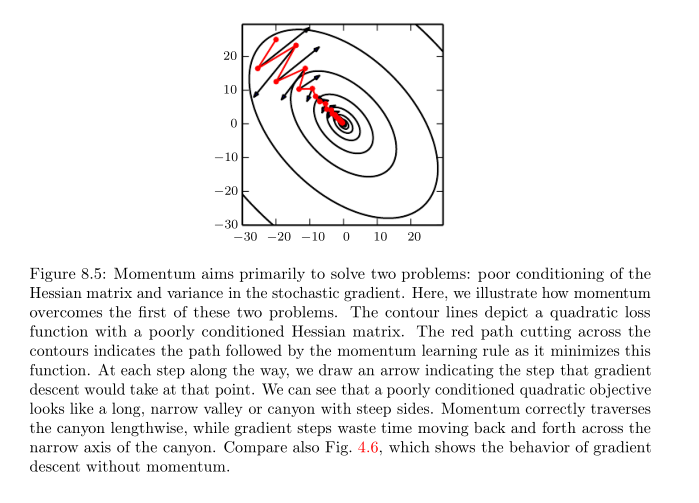
Momentum可以在高区率,幅度小但是持续的或者比较混杂的梯度空间内有良好的收敛速度。这个算法相对于gradient steps的优越性可以通过下图表达:
Algorithm 8.3

8.2可以认为是standard momentum,而8.3是8.2基础上的变体版。它们唯一的区别就是current velocity是否考虑到梯度的计算部分里面去。8.3添加了
θv
这一个修正因子。从收敛速度来说,Nesterov Momentum优于convex batch gradient,但是和stochastic gradient基本半斤八两。(黑人问号脸:那你跑出来干嘛?)
神经网络的变学习率优化算法:
Algorithm 8.4

AdaGrad算法是在SGD的基础上对学习率进行了改进。使得学习率和历史梯度值的平方的和成反比。这样一来梯度值大的阶段对应的学习率衰退得就多一些,但是对梯度值小的阶段对应的学习率衰退得就少一些。
个人观点,从总体上来看,AdaGrad的学习率一直都是下降的,只是偏导大的阶段衰退得幅度更大。书中描述AdaGrad算法对且仅对部分的深度学习模型有效。目前只知道是这么工作的,但具体原理需要后期参考作者论文。
Algorithm 8.5

AdaGrad一般仅适用于凸优化问题,对于非凸优化的工作效果并不好,经常会收敛在一个局部最优解上。并且由于AdaGrad一直记录了梯度值的平方的和,并用这个来decay学习率,这往往导致AdaGrad在并没有收敛到最优解之前学习率就已经非常低了,因此工作效果不佳。
RMSProp是在AdaGrad上面的改进。它通过调整系数
ρ
使得算法能够在不断收敛到最优解的道路上合适地丢掉历史对它的影响。
ρ
越接近零,历史对它的影响就越小。
(书上说它能够在找到函数的convex部分后快速收敛,性能和AdaGrad一样好。这里不能理解。)
Algorithm 8.6

Nesterov momentum的RMSProp改进体。
Algorithm 8.7

其实对这个算法个人觉得就是上面RMSProp的变体。不过一般在RMSProp更新的时候,它的学习率是通过直接结合decay rate
ρ
以及梯度的平方的和来得到。并且在更新参数的时候,通过对accumulate gradient r进行开方来保持系数的意义一致性。(这里个人觉得就是更新参数的时候要保证步长的单位某种意义上不能包含梯度这个单位,所以它在更新v的公式里面相当于分子是梯度的一次,分母是梯度的平方再开方)。
因此在Adam中并没有简单地采用平方再开方的方法,而是直接引入了一个first moment和second moment。First moment基本可以看做是the mean,而second moment可以看做是the uncentered variance。它们直接做一个比值,把单位归为一,值作为参数的更新值。然后…这个算法据说…工作得很好…
不要问我为什么,因为我也不知道,扫了一眼Adam的论文感觉论文里面也没有讲原理什么的,而且作者一些语言也比较模糊,比如下面的:
“Note that the efficiency of algorithm 1(Adam) can, at the expense of clarity, be improved upon by changing
the order of computation”。
以后有时间可以细读这篇论文:https://arxiv.org/pdf/1412.6980v8.pdf
神经网络的二次近似优化算法:
Algorithm 8.8

Newton方法简单来说,就是把原来一个非常非常复杂的cost function用泰勒做展开。但是展开多了也不好算,用泰勒展开节省计算的意义也就不明显了。因此Newton方法往往就展开到二阶打住。我们需要计算的只有cost function在
θ0
处的偏导数和对应的Hessian matrix。为了保证Newton方法可迭代,需要保证Hessian matrix正定。(这里涉及到数学推导,不赘述)
因此最后更新
θ
只需要对这个泰勒二阶展开式对需要更新的参数求导,便可以得到导数的更新值。也就是:
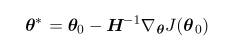
Algorithm 8.9

先理解一下这里提到的conjugate:
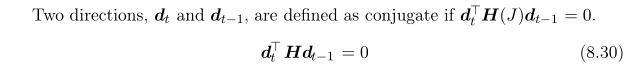
共轭梯度算法的出现主要解决的是Newton方法中Hessian matrix的逆矩阵求取困难的问题。它的目标是找到t时刻的参数更新方向dt,使dt的方向和dt-1的方向共轭。这样后一次的更新便不会抵消前一次的更新。(这里我就弱弱地问一句,那后两次的和这次的呢?…)这个时候dt的方向可以由下式决定:
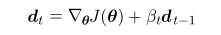
对于参数
βt
的计算可以直接采用以下计算公式:
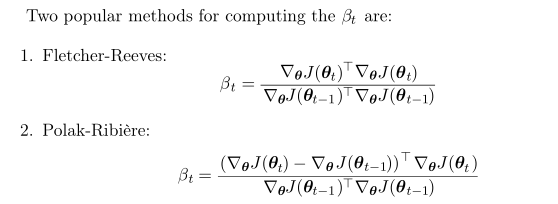
因此整个conjugate gradient method做的事情就是找到和上次参数更新共轭的方向,再求出参数能够使得cost function最小的时候的幅值。最后根据方向和幅值更新参数。不断循环直到stopping的条件满足。
写在最后:
其实看到后面看Adam和conjugate gradient method的时候整个人是一脸懵逼的。可能这块要深究还是需要一定时间的。今天争取再把CNN的轮廓和变体大致描一遍。
一身的橙子味…















 3056
3056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









