






我们在训练神经网络的时候,batch_size的大小会对最终的模型效果产生很大的影响。一定条件下,batch_size设置的越大,模型就会越稳定。batch_size的值通常设置在 8-32 之间,但是当我们做一些计算量需求大的任务(例如语义分割、GAN等)或者输入图片尺寸太大的时候,我们的batch size往往只能设置为2或者4,否则就会出现 “CUDA OUT OF MEMORY” 的不可抗力报错。
在神经网络的训练中,经常会出现图像尺寸很大又想增大batch size,无奈显存不足,但是大显存的 A6000 又挺贵的💰,那怎么办呢?如何在有限的计算资源的条件下,训练时采用更大的batch size呢?这就是梯度累加(Gradient Accumulation)技术了。
常规训练过程
for i, (inputs, labels) in enumerate(trainloader): optimizer.zero_grad() # 梯度清零 outputs = net(inputs) # 正向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新参数 if (i+1) % evaluation_steps == 0: evaluate_model()使用梯度累加的训练过程
for i, (inputs, labels) in enumerate(trainloader): outputs = net(inputs) # 正向传播 loss = criterion(outputs, labels) # 计算损失函数 loss = loss / accumulation_steps # 损失标准化 loss.backward() # 反向传播,计算梯度 if (i+1) % accumulation_steps == 0: optimizer.step() # 更新参数 optimizer.zero_grad() # 梯度清零 if (i+1) % evaluation_steps == 0: evaluate_model()就是加了个if
注意这里的loss每次要除以accumulation_step,所以当累加到一定步数optimizer更新的值其实是这些累加值的均值。其实就相当于扩大了batch_size,让更新的loss更加平稳。一个batch的数据最后算的loss也是这个batch的数据个数的均值。
总结来讲,梯度累加就是每计算一个batch的梯度,不进行清零,而是做梯度的累加(平均),当累加到一定的次数之后,再更新网络参数,然后将梯度清零。
通过这种参数延迟更新的手段,可以实现与采用大batch_size相近的效果。知乎上有人说
"在平时的实验过程中,我一般会采用梯度累加技术,大多数情况下,采用梯度累加训练的模型效果,要比采用小batch_size训练的模型效果要好很多"。
Pytorch实验
efficientnet在MNIST数据集上
V100 GPU
半精度
正常efficientnet
import os import timm import torch import random import wandb from torch.cuda.amp import GradScaler from torch.cuda.amp import autocast import torchvision.transforms as transforms import torchvision.datasets as dataset import seaborn as sns import numpy as np from tqdm import tqdm def seed_torch(seed=99): random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) # if you are using multi-GPU. torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True torch.backends.cudnn.enabled = False if __name__ == '__main__': wandb.init( project = "test", # config = args, name = 'efficientnet_b0', # id = args.wandb_id, #resume = True, ) seed_torch() # 准备 MNIST 数据 trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))]) train_set = dataset.MNIST(root='./', train=True, transform=trans, download=True) test_set = dataset.MNIST(root='./', train=False, transform=trans) # Dataloader train_loader = torch.utils.data.DataLoader( dataset=train_set, batch_size=32768, num_workers=8, shuffle=True) model = timm.create_model('efficientnet_b0', in_chans=1, num_classes=10).cuda() optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3) loss_fn = torch.nn.CrossEntropyLoss() losses = [] scaler = GradScaler() for epoch in range(10): loss_epoch = 0 for i, (input, target) in enumerate(train_loader): with autocast(): output = model(input.cuda()) loss = loss_fn(output, target.cuda()) scaler.scale(loss).backward() loss_epoch += loss.item() * len(input) scaler.step(optimizer) scaler.update() optimizer.zero_grad() print('Loss: ', loss_epoch/len(train_set)) wandb.log({'train/loss': loss_epoch/len(train_set)}) losses.append(loss_epoch/len(train_set)) wandb.finish()efficientnet + 梯度累加
import os import timm import torch import random import wandb from torch.cuda.amp import GradScaler from torch.cuda.amp import autocast import torchvision.transforms as transforms import torchvision.datasets as dataset import seaborn as sns import numpy as np from tqdm import tqdm def seed_torch(seed=99): random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) # if you are using multi-GPU. torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = True torch.backends.cudnn.enabled = False if __name__ == '__main__': wandb.init( project = "test", # config = args, name = 'efficientnet_b0', # id = args.wandb_id, #resume = True, ) seed_torch() # 准备 MNIST 数据 trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))]) train_set = dataset.MNIST(root='./', train=True, transform=trans, download=True) test_set = dataset.MNIST(root='./', train=False, transform=trans) # Dataloader train_loader = torch.utils.data.DataLoader( dataset=train_set, batch_size=8192, num_workers=8, shuffle=True) model = timm.create_model('efficientnet_b0', in_chans=1, num_classes=10).cuda() losses = [] # 将模型的 BatchNorm2d 更换成 GroupNorm def convert_bn_to_gn(model): for child_name, child in model.named_children(): if isinstance(child, torch.nn.BatchNorm2d): num_features = child.num_features setattr(model, child_name, torch.nn.GroupNorm(num_groups=1, num_channels=num_features)) else: convert_bn_to_gn(child) convert_bn_to_gn(model) model = model.cuda() optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4) loss_fn = torch.nn.CrossEntropyLoss() scaler = GradScaler() iters_to_accumulate = 4 for epoch in range(10): loss_epoch = 0 for i, (input, target) in enumerate(train_loader): with autocast(): output = model(input.cuda()) loss = loss_fn(output, target.cuda()) loss_epoch += loss.item() * len(input) loss = loss / iters_to_accumulate scaler.scale(loss).backward() if (i + 1) % iters_to_accumulate == 0: scaler.step(optimizer) scaler.update() optimizer.zero_grad() print('Loss: ', loss_epoch/len(train_set)) wandb.log({'train/loss': loss_epoch/len(train_set)}) losses.append(loss_epoch/len(train_set)) wandb.finish()
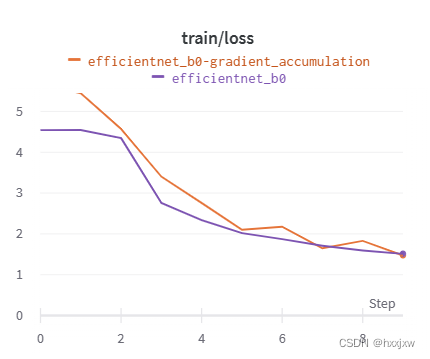
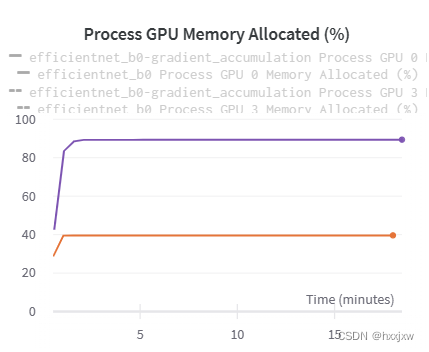
可以看到梯度累加的效果

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









