







大家好,我是吾鳴。
现在很多的互联网大厂都开始接入DeepSeek-R1大模型了,每个公司都宣称自己接入的是DeepSeek-R1满血模型,那究竟怎么区分到底是不是满血模型呢?
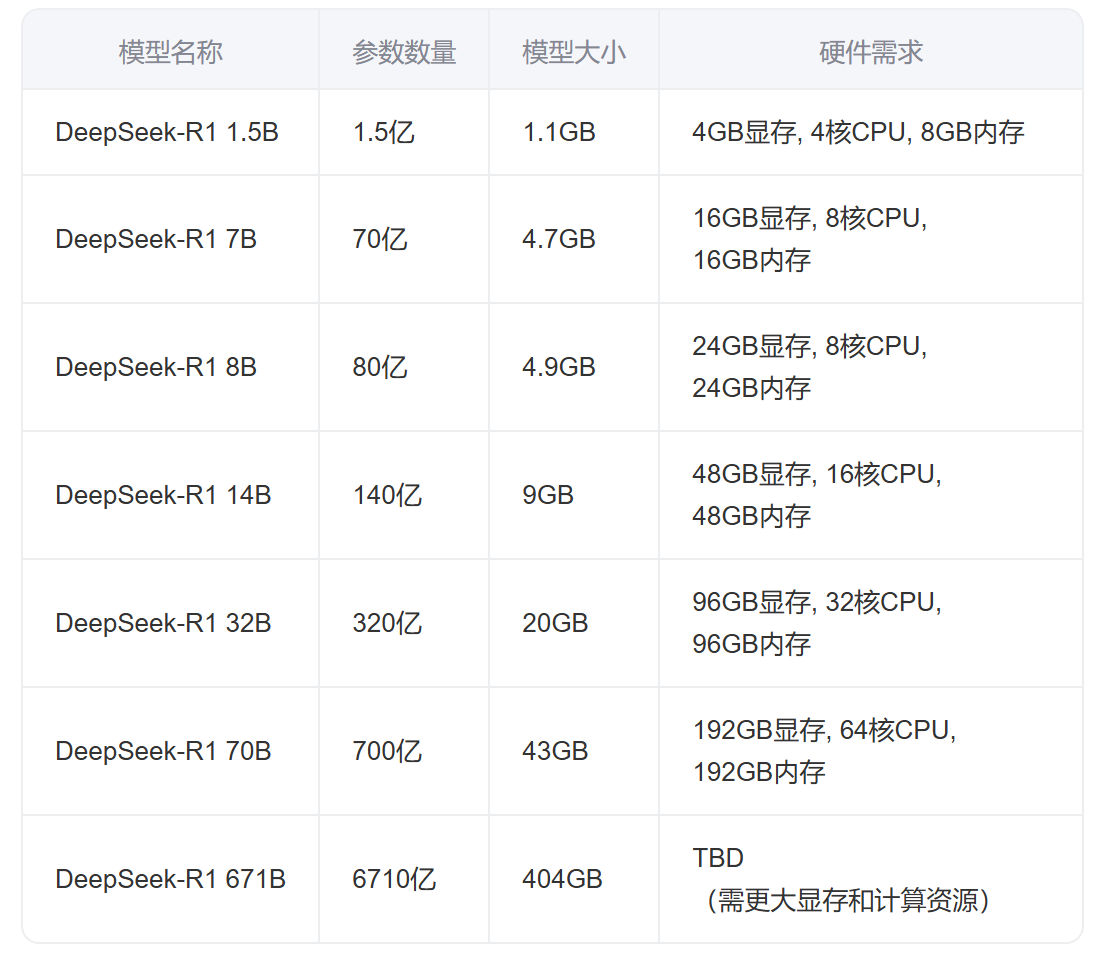
开始下面分享之前,我们先来看看到底什么是满血模型,其实所谓的满血模型,就是DeepSeek-R1 671B这个模型,因为其参数数量最多,模型大小最大,所需要的硬件资源要求最高,给出来的回答最准确,因此被大家称为“满血模型”。
今天上班摸鱼的时候刷到了一篇比较有意思的文章,介绍的就是教大家如何去分辨所使用的模型到底是不是满血模型,只需要问DeepSeek一个问题,便可以知道它到底是不是满血模型。
一个汉字具有左右结构,左边是木,右边是乞。这个是什么?只需要回答这个字即可这个问题的核心思想是通过生僻字来检验大模型的能力,觉得还蛮有意思的,于是乎我也在各大平台接入的DeepSeek-R1模型中测试了下。
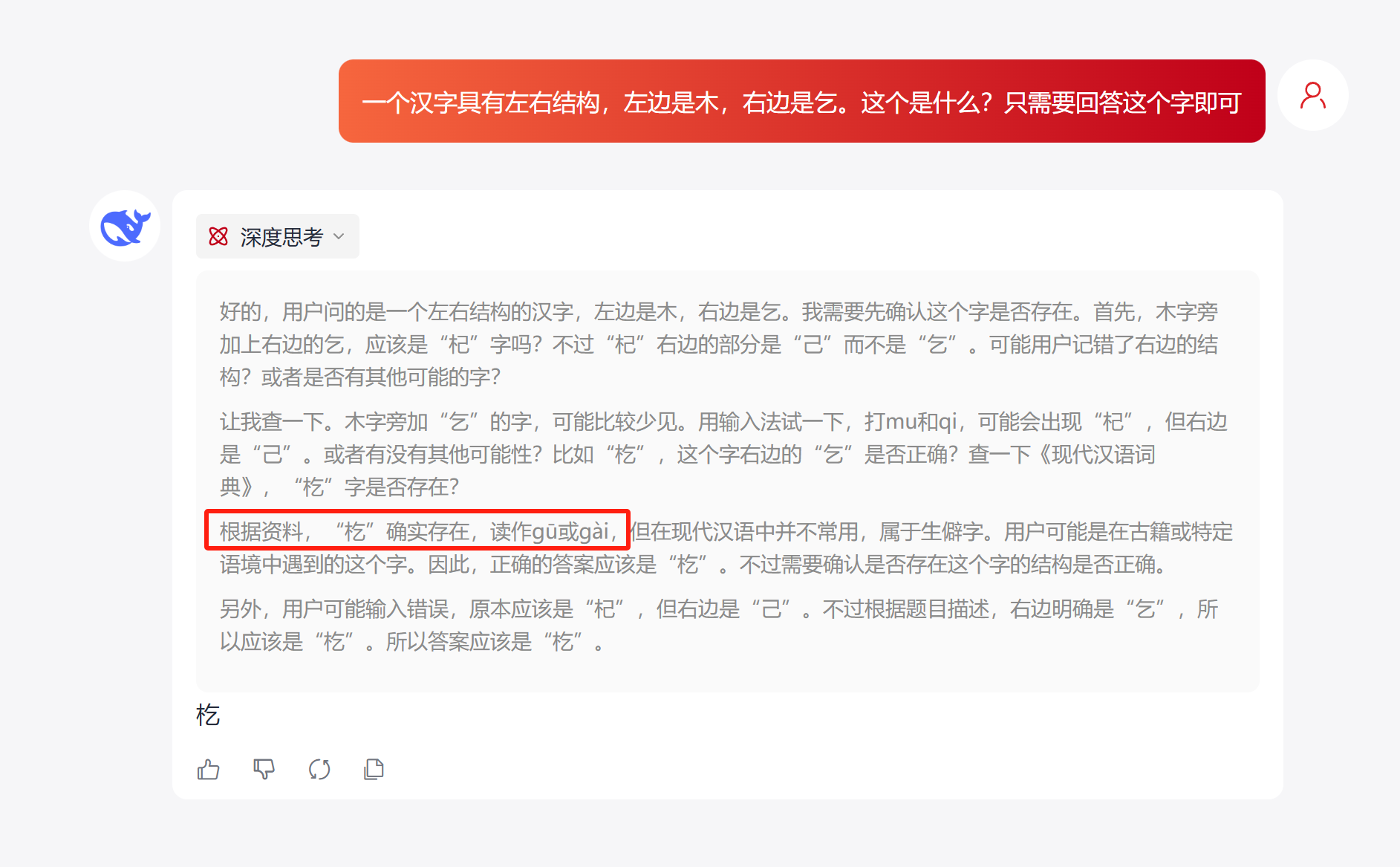
第一个是DeepSeek官网的大模型,我先是勾上了“深度思考(R1)”选项,输入了问题,它的回答结果是正确的,但是把貌似这个拼音不太对,不知道你们觉得它给的这两个读法对吗?可以把正确的读法打在评论区里。
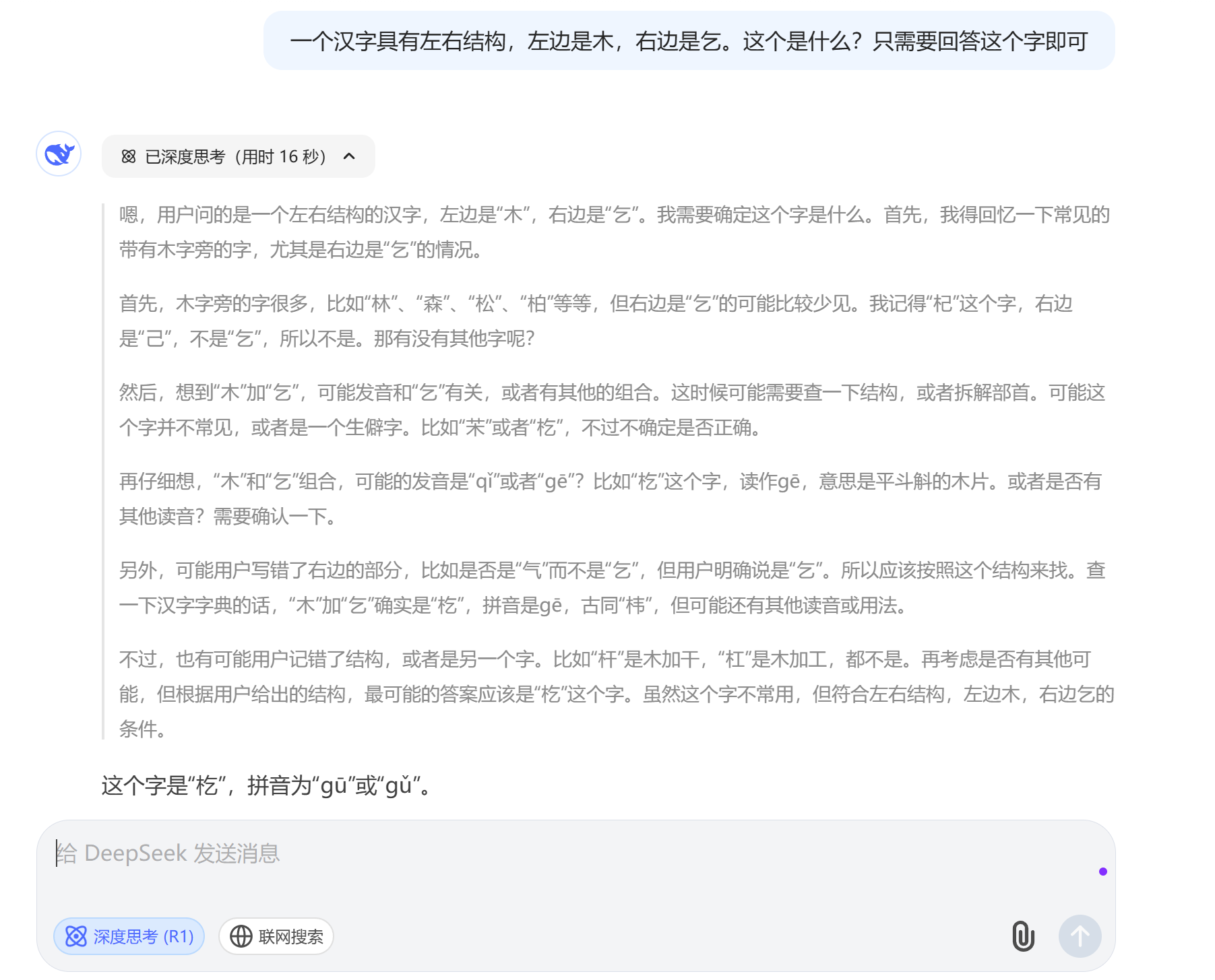
当我把“深度思考(R1)”去掉之后,它给出来的答案就是意料之中的了,因为它就不是一个推理模型,也就谈不上是不是满血了,哈哈哈。
第二个是秘塔搜索,它的回答出乎我的意料,除了回答正确之外,同时它给出的拼音也是正确的。
第三个是纳米AI,它也是一个满血模型,但是它思考过程中提到这个字的读音貌似不太对,天啊,当我在说它们给得拼音不对的时候,我都有点慌,毕竟上学的时候,语文就没怎么及格过。

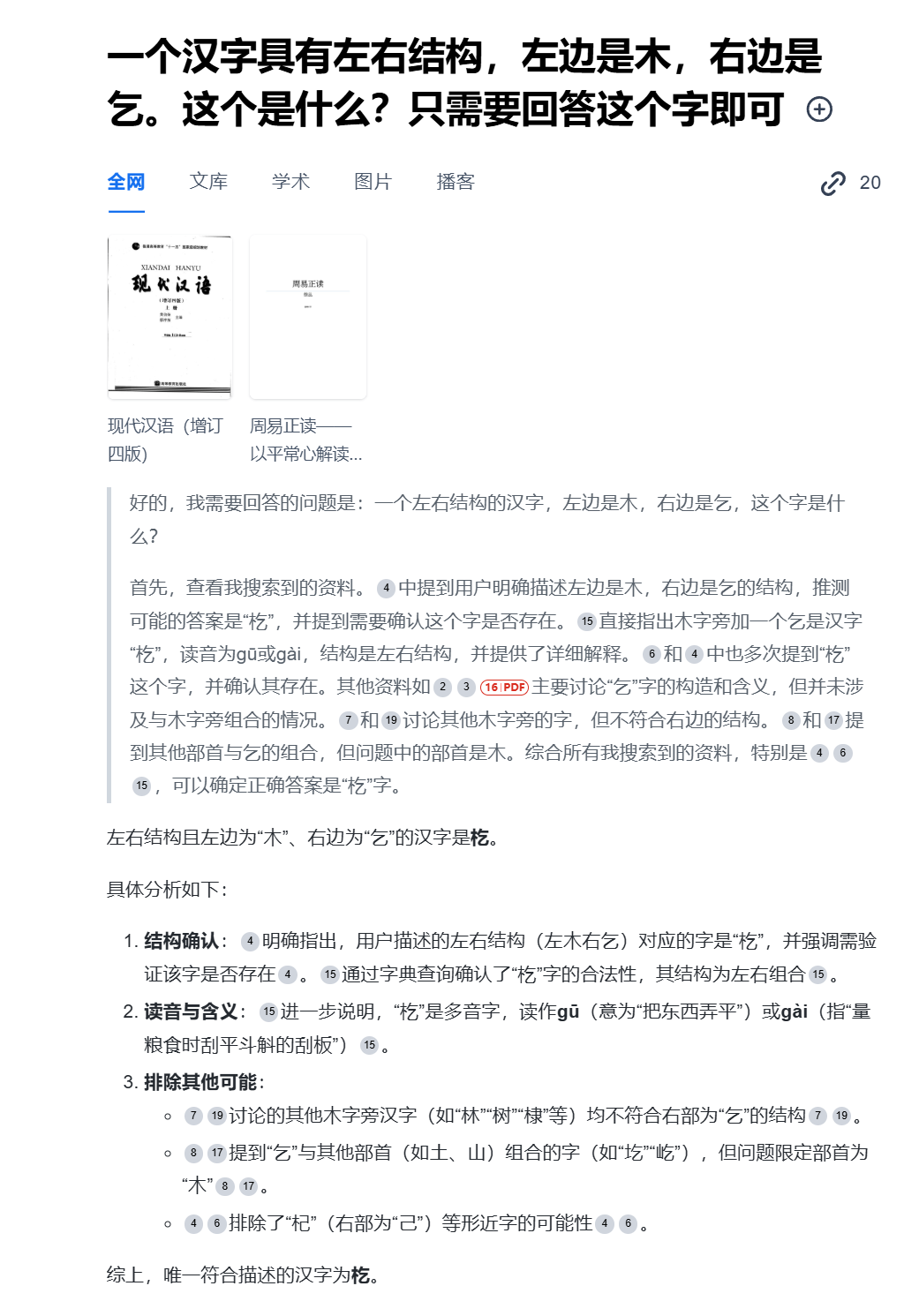
第四个是国家超算中心,我觉得还是很有意思,虽然这些满血模型都给出来了正确的答案,但是它们给出来的拼音却是各有千秋,你们觉得这个拼音该怎么读?我还是不死心,我又去试了下国家超算中心,这个平台思考得有点点慢,但是看它一个一个子的思考过程也是很有意思,不像其他平台,得要一目十行才能跟上它得节奏,这个也是一种风格,我比较喜欢。思考出来得结果也是对的,它的拼音也是对的,非常的厉害,背景技术实力不可小觑。
第五个是问小白,看看它的表现如何;问小白的思考速度非常的快,我的眼睛完全跟不上它的节奏,只能等它思考完再回来看看它的思考过程,它的结果也是正确的,妥妥的满血模型,但是它的读音确实这两个,这又让我对自己产生怀疑了,到底哪个才是正确的读音?于是乎我又去查阅了下百年不动的字典,让我更加坚定的我的推断,问小白给的读音不完全对。

好了今天就分享到这里了,你也可以使用这种方法测测你现在正在使用的DeepSeek大模型,验证下它是不是满血模型。“杚”这个字的正确读音到底是啥?我已经有点犯迷糊了。
福利:最近交了一些学费,收集到了一些关于DeepSeek的学习资料,需要的朋友们可以按照下面的方式自取。

福利下载地址:夸克网盘分享



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











