







目录
摘要
本文提出了一种以编码-解码器transformer为关键组件的跟踪体系结构。编码器对目标对象和搜索区域之间的全局时空特征依赖关系进行建模,而解码器学习嵌入的查询以预测目标对象的空间位置。我们的方法将目标跟踪作为一个直接的边界框预测问题,而不使用任何建议或预定义的锚点。通过编解码器变换,目标的预测只需使用一个简单的全卷积网络,直接估计目标的角点。整个方法是端到端的,不需要余弦窗、包围盒平滑等后处理步骤,大大简化了现有的跟踪流水线。建议的跟踪器在五个具有挑战性的短期和长期基准上实现了最先进的性能,同时以实时速度运行,比Siamese RCNN快6倍[47]。代码和模型在这里是开源的。
1.引言
视觉目标跟踪是计算机视觉中一个基础而又富有挑战性的研究课题。在过去的几年里,基于卷积神经网络的目标跟踪取得了显著的进展[25,9,47]。然而,卷积核不擅长对图像内容和特征的长期相关性进行建模,因为它们只处理局部邻域,无论是在空间上还是在时间上。目前流行的跟踪器,包括离线Siamese追踪器和在线学习模型,几乎都是建立在卷积运算的基础上[2,37,3,47]。因此,这些方法只能很好地对图像内容的局部关系进行建模,但仅限于捕获远程的全局交互。这样的缺陷可能会降低模型处理全局上下文信息对于定位目标对象很重要的场景的能力,例如经历大规模变化或频繁进出视图的对象。
通过使用transformer在序列建模中解决了远程交互的问题[46]。Transform在自然语言建模[11,39]和语音识别[34]等任务中取得了巨大的成功。近年来,transformer被用于判别计算机视觉模型,引起了人们的极大关注[12,5,35]。受最近的DEtection TRansformer(DETR)[5]的启发,我们提出了一种新的端到端跟踪结构,采用编码器-解码器transformer来提高传统卷积模型的性能。
空间信息和时间信息对于目标跟踪都是重要的。前者包含用于目标定位的对象外观信息,而后者包含对象跨帧的状态变化。以前的Siamese追踪器[25,51,14,6]只利用空间信息进行追踪,而在线方法[54,57,9,3]使用历史预测进行模型更新。虽然这些方法很成功,但它们并没有明确地对空间和时间之间的关系进行建模。在这项工作中,考虑到全局依赖模型的优越能力,我们采用transformer来整合时空信息进行跟踪,生成可区分的时空特征用于目标定位。
更具体地说,我们基于编码-解码器transformer提出了一种新的空间-时间结构用于视觉跟踪。新架构包含三个关键组件:编码器、解码器和预测头。编码器接受初始目标对象、当前图像和动态更新模板的输入。编码器中的自我注意模块通过输入的特征依赖关系来学习输入之间的关系。由于模板图像在整个视频序列中被更新,因此编码器可以捕获目标的空间和时间信息。解码器学习嵌入的查询以预测目标对象的空间位置。使用基于角点的预测头来估计当前帧中目标对象的边界框。同时,学习记分头来控制动态模板图像的更新。
广泛的实验表明,我们的方法在短期[18,36]和长期跟踪基准[13,22]上都建立了新的最先进的性能。例如,我们的时空变换跟踪器在GOT-10K[18]和LaSOT[13]上分别比Siam R-CNN[47]高3.9%(AO得分)和2.3%(成功率)。同样值得注意的是,与以前的长期跟踪器[8,47,53]相比,我们的方法的框架要简单得多。具体地说,以前的方法通常由多个组件组成,例如基本跟踪器[9,50]、目标验证模块[21]和全局检测器[40,19]。相比之下,我们的方法只有一个以端到端方式学习的网络。此外,我们的跟踪器可以实时运行,在特斯拉V100图形处理器上比Siam R-CNN(30 V.S 5fps)快6倍,如图1所示。
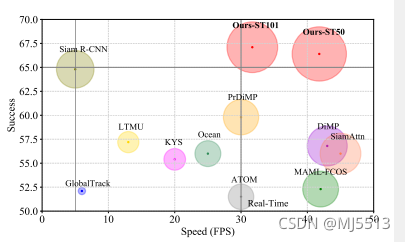
图1:与LaSOT最新技术的比较[13]。我们将成功性能与Frame-PerSecond(fps)跟踪速度进行了可视化比较。OURS-ST101和OURS-ST50分别表示以ResNet-101和ResNet-50为主干的建议跟踪器。彩色效果更佳
总而言之,这项工作有三个贡献。
- 我们提出了一种新的致力于视觉跟踪的transformer架构。它能够捕获视频序列中空间和时间信息的全局特征依赖关系。
- 整个方法是端到端的,不需要余弦窗口、包围盒平滑等后处理步骤,大大简化了现有的跟踪流水线。
- 建议的跟踪器在五个具有挑战性的短期和长期基准上实现最先进的性能,同时以实时速度运行。
2.相关工作
语言与视觉中的transformer。transformer最早是由Vaswani等人提出的[46]面向机器翻译任务,已成为语言建模的主流架构。transformer接受序列作为输入,扫描序列中的每个元素并了解它们的依赖关系。这一特性使得transformer本质上擅长捕获顺序数据中的全局信息。近年来,transformer在图像分类[12]、目标检测[5]、语义分割[49]、多目标跟踪[44,35]等视觉任务中显示出巨大的潜力。我们的工作灵感来自于最近的工作DETR[5](DEtection TRansformer),但有以下根本区别。(1)学习任务不同。DETR是为目标检测而设计的,而这项工作是为目标跟踪而设计的。(2)网络输入不同。DETR将整个图像作为输入,而我们的输入是由一个搜索区域和两个模板组成的三元组。它们来自主干的特征首先被展平和拼接,然后被发送到编码器。(3)查询设计和训练策略不同。DETR使用100个对象查询,并在训练期间使用匈牙利算法将预测与地面事实相匹配。相比之下,我们的方法只使用一个查询,并且始终将其与地面事实相匹配,而不使用匈牙利算法。(4)包围盒头部不同。DETR使用三层感知器来预测盒子。我们的网络采用基于角点的盒头,以实现更高质量的本地化。
此外,TransTrack[44]和TrackFormer[35]是transformer跟踪领域最新的两部代表作。Trans-track[44]具有以下特点。(1)编码器将当前帧和前一帧的图像特征作为输入。(2)有两个解码器,分别以学习到的对象查询和上一帧的查询作为输入。对于不同的查询,编码器的输出序列被分别转换为检测盒和跟踪盒。(3)使用匈牙利算法基于IoUs匹配预测的两组盒子[24]。而Trackformer[35]则具有以下特点。(1)只将当前帧特征作为编码器输入。(2)只有一个解码器,学习的对象查询和来自最后一帧的跟踪查询相互交互。(3)它仅通过注意力操作来关联随时间推移的轨迹,而不依赖于任何额外的匹配,例如运动或外观建模。相比之下,我们的工作与这两种方法有以下根本区别。(1)网络输入不同。我们的输入是一个三元组,由当前搜索区域、初始模板和动态模板组成。(2)我们的方法通过更新动态模板来捕捉跟踪目标的外观变化,而不是像[44,35]那样更新对象查询。
时空信息利用。时空信息的利用是目标跟踪领域的核心问题。现有的跟踪器可以分为两类:纯空间跟踪器和时空跟踪器。大多数离线Siamese跟踪器[2,26,25,60,29]属于纯空间跟踪器,它们将目标跟踪视为初始模板和当前搜索区域之间的模板匹配。为了提取模板和搜索区域在空间维度上的关系,大多数跟踪器采用相关性的变体,包括朴素相关性[2,26],深度相关[25,60]和点相关[29,52]。虽然
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2005
2005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









