







目录
论文介绍
题目:
Mix Structure Block contains multi-scale parallel large convolution kernel module and enhanced parallel attention module
论文地址:
链接: https://arxiv.org/abs/2305.17654
创新点
这篇文章介绍了一个名为MixDehazeNet的图像去雾网络,其主要创新点包括:
-
多尺度并行大卷积核模块(MSPLCK):该模块结合了多尺度特性和大的感受野,能够同时捕获大雾区域和恢复纹理细节。与单一大核相比,多尺度并行大核能更好地考虑去雾过程中的局部纹理。
-
增强并行注意力模块(EPA):该模块开发了一种新的并行连接的注意力机制,能更有效地处理不均匀的雾分布。它包括三种注意力机制(简单像素注意力、通道注意力和像素注意力),通过多层感知器融合,能够并行提取原始特征的全局共享信息和位置依赖的局部信息。
-
Mix结构块:MixDehazeNet利用U-Net作为主干网络,并包含Mix结构块,结合了多尺度并行大卷积核模块和增强并行注意力模块。这种结构块是一种Transformer风格的块,用多尺度并行大卷积核模块替换了Transformer中的多头自注意力,用增强并行注意力模块替换了前馈网络。
-
对比损失的集成:与AECR-Net不同,MixDehazeNet使用ResNet-152作为对比学习的骨干网络,因为发现它比VGG19更有效。
-
性能提升:在多个图像去雾数据集上,MixDehazeNet实现了最先进的结果。例如,在SOTS室内数据集上,与之前的最佳方法相比,MixDehazeNet实现了显著的性能提升(42.62dB的PSNR)。
-
模型变体:提供了三种不同规模的MixDehazeNet模型(-S, -B, -L),以适应不同的计算资源和实时性要求。
这些创新点共同使得MixDehazeNet在图像去雾任务中取得了显著的性能提升,特别是在处理不均匀雾分布和恢复图像细节方面。
方法
模型总体架构
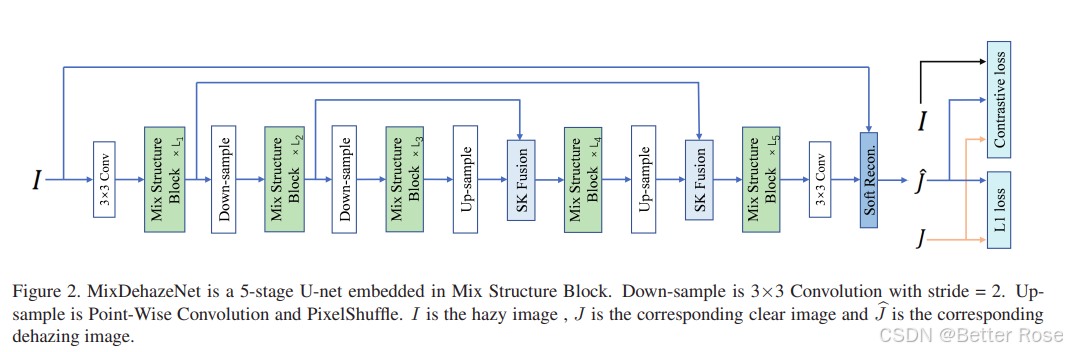
MixDehazeNet的总体架构基于一个5阶段的U-Net结构,其中每个阶段都嵌入了一个Mix结构块。这个Mix结构块是模型的核心,它由两部分组成:
-
多尺度并行大卷积核模块(MSPLCK):这个模块使用不同大小的卷积核来捕获图像的多尺度特征。它包括大卷积核来捕捉全局特征和大雾区域,以及小卷积核来关注细节特征和恢复纹理细节。这些不同尺度的特征通过通道维度的拼接被整合在一起。
-
增强并行注意力模块(EPA):这个模块结合了简单像素注意力、通道注意力和像素注意力,它们并行工作以提取全局共享信息和位置依赖的局部信息。这种并行注意力机制更适合于处理不均匀的雾分布。
此外,MixDehazeNet还采用了SK Fusion来融合跳跃连接和主分支,并在网络的末端使用软重建代替全局残差,因为软重建提供了比全局残差更强的去雾约束。
模型训练时,使用了L1损失和对比损失,以优化模型性能。MixDehazeNet提供了三种不同规模的变体(-S, -B, -L),以适应不同的应用场景和计算资源需求。整体上,MixDehazeNet通过其创新的Mix结构块和多尺度处理能力,在多个图像去雾数据集上实现了领先的性能。
核心模块描述
MixDehazeNet的核心模块是Mix结构块,它由以下两个主要部分组成:
1. 多尺度并行大卷积核模块(MSPLCK):
- 这个模块的目的是通过使用不同尺寸的卷积核来捕获图像的多尺度特征。它包含大尺寸卷积核来捕捉图像中的全局特征,这些大尺寸卷积核能够覆盖更大的区域,从而有效地识别和处理大范围的雾气。
- 同时,小尺寸卷积核专注于图像的细节特征,帮助恢复因雾气而模糊的纹理和细节。
- 这些不同尺寸卷积核的输出特征会在通道维度上进行拼接,整合在一起,以获得更全面的图像特征。
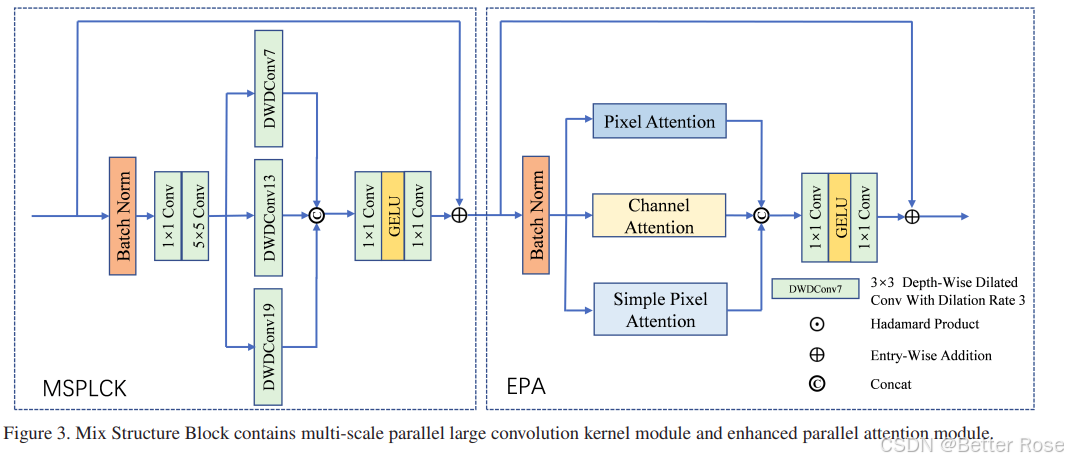
2. 增强并行注意力模块(EPA):
- 这个模块设计了三种不同的注意力机制:简单像素注意力、通道注意力和像素注意力,它们并行工作而不是顺序连接。
- 简单像素注意力专注于提取位置依赖的信息,而通道注意力则提取全局信息。像素注意力则结合这两种注意力机制的优势。
- 这些注意力机制能够并行地提取和融合图像特征,使得模型能够更有效地处理不均匀的雾气分布,并提取对去雾有用的特征。
- 最后,这些并行的注意力机制的输出会被合并,并通过一个多层感知器(MLP)来调整特征维度,使其与输入特征相匹配。
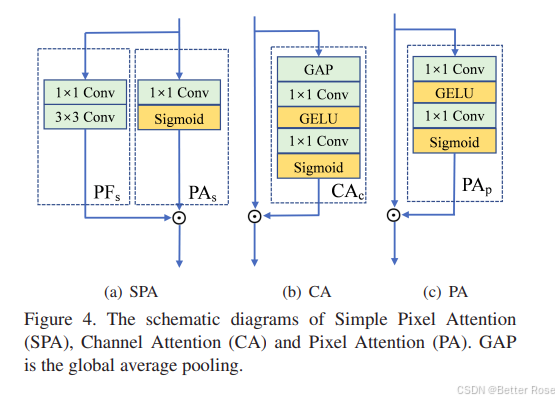
即插即用模块作用
MSB 作为一个即插即用模块:
- 特征提取能力的增强:MSB通过结合不同类型的卷积操作(深度可分离卷积与标准卷积),能够更有效地提取多尺度的图像特征,尤其是在细节恢复方面表现优越。这样可以帮助网络更好地处理雾霾遮挡的图像细节。
- 提高去雾效果:在图像去雾任务中,MSB能够通过多层卷积操作增强对图像中各个层次特征的捕捉,进而提高去雾效果,恢复更清晰、更自然的图像。
- 降低计算复杂度:通过采用深度可分离卷积,MSB减少了计算量和参数量,使得模型更加高效,适合部署在计算资源有限的设备上。
消融实验结果
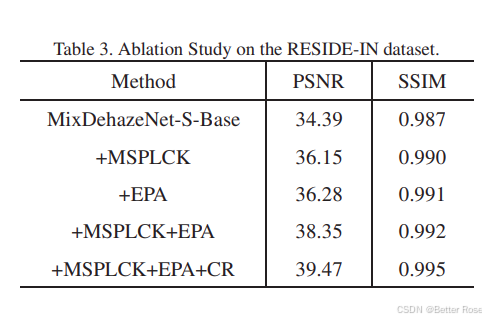
- 消融实验的结果表明,MixDehazeNet中每个提出的模块都对模型的去雾性能有显著的提升作用。当加入多尺度并行大卷积核模块(MSPLCK)时,相比于基础模型,PSNR提升了1.76dB。增强并行注意力模块(EPA)的加入进一步提升了PSNR,增加了1.89dB。而当MSPLCK和EPA结合使用时,相比于基础模型,PSNR提升了3.96dB。
- 此外,将对比损失(CR)加入到模型中,进一步将PSNR提升到了39.47dB,显示出对比损失在提升去雾效果方面的有效性。这些结果验证了MSPLCK和EPA模块在提升去雾性能方面的重要作用,以及它们与对比损失结合使用时的协同效应。
核心代码
import torch
import torch.nn as nn
#论文地址:https://arxiv.org/abs/2305.17654
#论文:Mix Structure Block contains multi-scale parallel large convolution kernel module and enhanced parallel attention module
class MixStructureBlock(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.norm2 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, dim, kernel_size=1)
self.conv2 = nn.Conv2d(dim, dim, kernel_size=5, padding=2, padding_mode='reflect')
self.conv3_19 = nn.Conv2d(dim, dim, kernel_size=7, padding=9, groups=dim, dilation=3, padding_mode='reflect')
self.conv3_13 = nn.Conv2d(dim, dim, kernel_size=5, padding=6, groups=dim, dilation=3, padding_mode='reflect')
self.conv3_7 = nn.Conv2d(dim, dim, kernel_size=3, padding=3, groups=dim, dilation=3, padding_mode='reflect')
# Simple Pixel Attention
self.Wv = nn.Sequential(
nn.Conv2d(dim, dim, 1),
nn.Conv2d(dim, dim, kernel_size=3, padding=3 // 2, groups=dim, padding_mode='reflect')
)
self.Wg = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(dim, dim, 1),
nn.Sigmoid()
)
# Channel Attention
self.ca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(dim, dim, 1, padding=0, bias=True),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim, dim, 1, padding=0, bias=True),
nn.Sigmoid()
)
# Pixel Attention
self.pa = nn.Sequential(
nn.Conv2d(dim, dim // 8, 1, padding=0, bias=True),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim // 8, 1, 1, padding=0, bias=True),
nn.Sigmoid()
)
self.mlp = nn.Sequential(
nn.Conv2d(dim * 3, dim * 4, 1),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim * 4, dim, 1)
)
self.mlp2 = nn.Sequential(
nn.Conv2d(dim * 3, dim * 4, 1),
nn.GELU(),
# nn.ReLU(True),
nn.Conv2d(dim * 4, dim, 1)
)
def forward(self, x):
identity = x
x = self.norm1(x)
x = self.conv1(x)
x = self.conv2(x)
x = torch.cat([self.conv3_19(x), self.conv3_13(x), self.conv3_7(x)], dim=1)
x = self.mlp(x)
x = identity + x
identity = x
x = self.norm2(x)
x = torch.cat([self.Wv(x) * self.Wg(x), self.ca(x) * x, self.pa(x) * x], dim=1)
x = self.mlp2(x)
x = identity + x
return x
if __name__ == '__main__':
block = MixStructureBlock(dim=64)
input = torch.rand(1, 64, 128, 128) # B C H W
output = block(input)
print(input.size())
print(output.size())


















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









