







1. OCR概述
OCR(Optical Character Recognition,光学字符识别)技术是一种将图像中的文字内容提取为可编辑的数字文本的技术。它能够识别图片中的印刷字体、手写字体,甚至复杂的表格和图形内容,实现从“图像”到“数据”的转换。也就是说将图象中的文字进行识别,并返回文本形式的内容。例如,你有一份纸质的旧报纸,上面有很多有价值的新闻内容。通过 OCR 技术,就可以把报纸上的文字提取出来,转化为电子文本,这样你就可以方便地在电子设备上对这些新闻进行整理、分析,甚至分享。
OCR在分类上可以分为手写体识别和印刷体识别两个大主题,当然印刷体识别较手写体识别要简单得多,我们也能从直观上理解,印刷体大多都是规则的字体,因为这些字体都是计算机自己生成再通过打印技术印刷到纸上。

OCR技术的起源可以追溯到20世纪20年代,当时德国科学家Tausheck首次提出了OCR的概念,设想利用机器来读取字符和数字。随着计算机技术的发展、扫描设备的逐渐提升以及计算机视觉的不断成熟,开始出现基于图像处理(边缘检测、腐蚀膨胀、投影分析等)和统计机器学习的OCR技术,识别准确度进一步提升。其标准的处理流程包括:图像预处理、文本行检测、单字符分割、单字符识别、后处理。

但是,OCR场景逐渐复杂以及识别精度的要求不断提升,传统OCR逐渐不能满足已有需求,基于深度学习的技术让OCR识别效果更近一步。
2. 实现流程
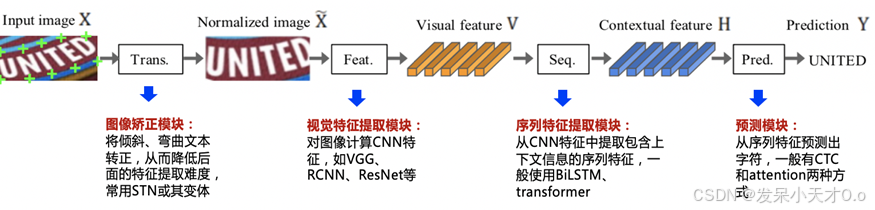
笔者在前面博客中,已经基于传统方法和深度学习方法实现了拍照文档边缘校正。版面分析是文档图像处理中的一个关键步骤,用于识别和分类文档中的内容,如文本、图片、表格等,并为后续的处理(如OCR或结构化输出)奠定基础。
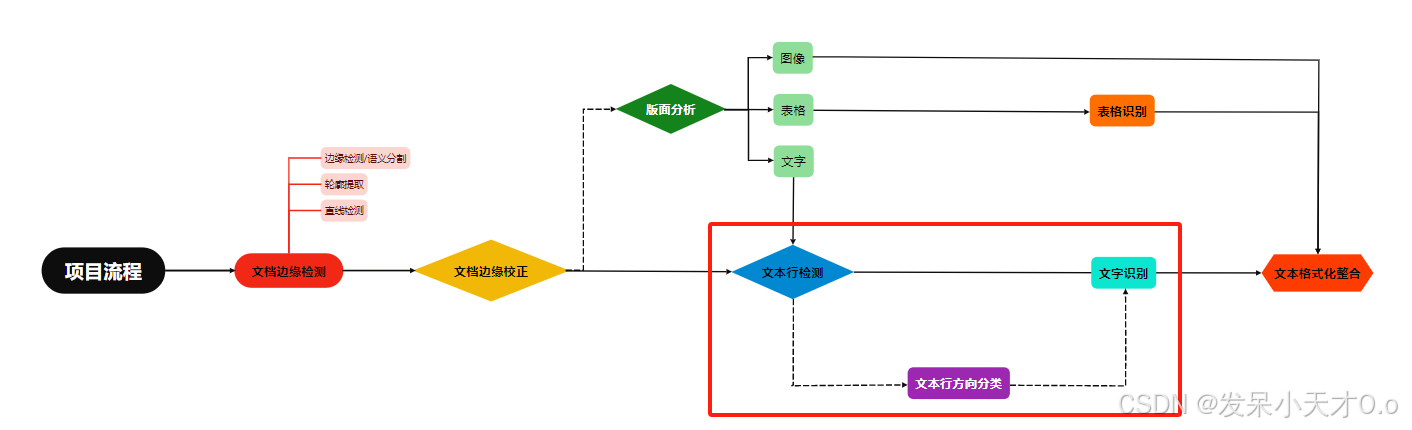
在本节中重点总结文本行检测、文本行方向分类、文字识别。简单来说图片经过文字检测之后将图片中可能为文字的部分用矩形框标出,此时的文字可能是倒转或斜的,然后由方向分类器处理矩形框,将角度不正确的文字处理成正常方向的。经过方向分类器处理后的文字矩形框再通过文字识别,提取其中的文字。
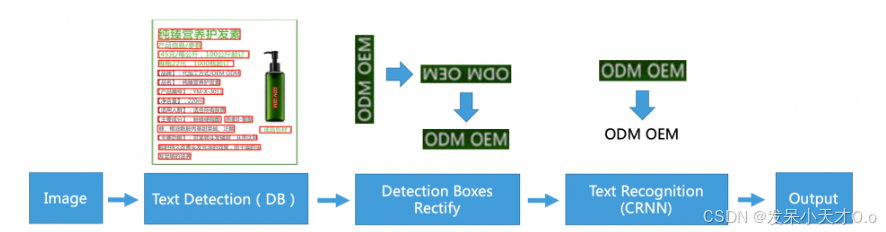
3. 算法概述
3.1 文本检测
3.1.1 原理
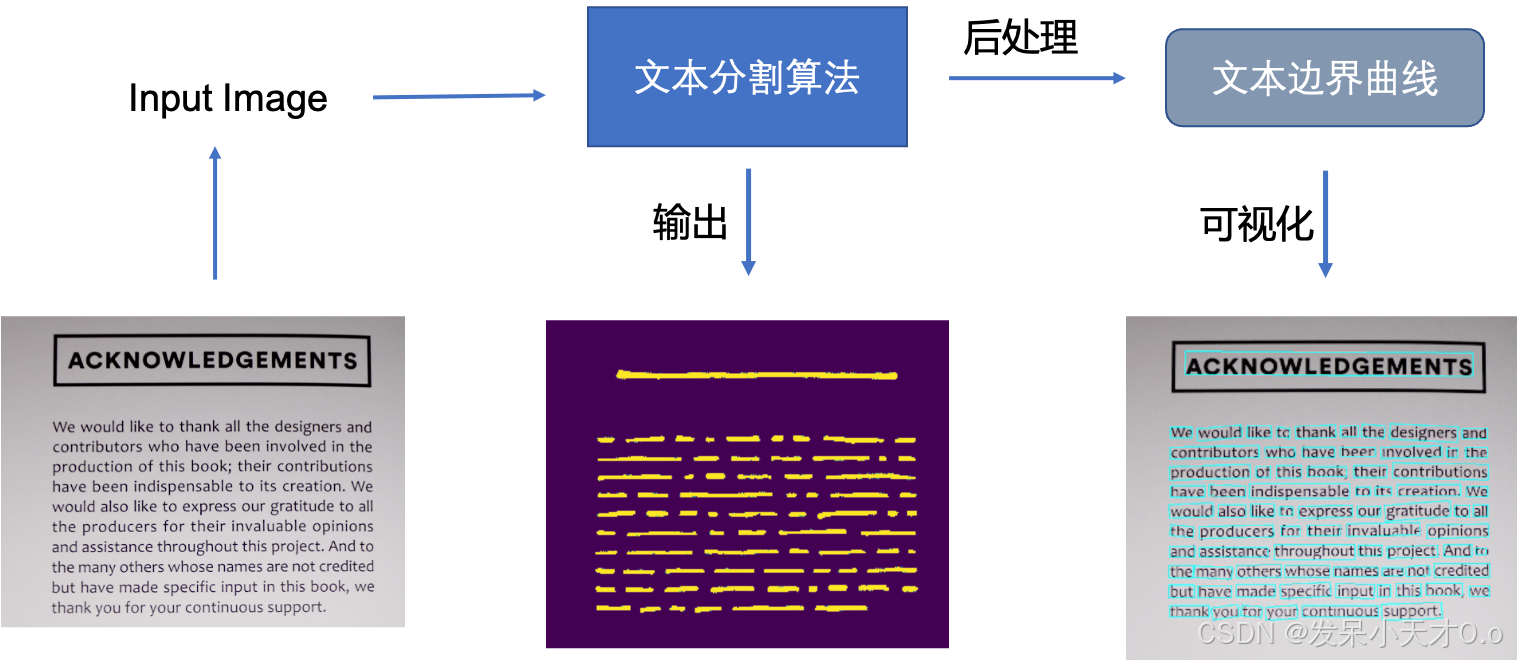
文本检测目的是将图片中的文字区域位置检测出来,以便于进行后面的方向检测或文字识别。只有找到了文本所在区域,才能对其内容进行识别。

注意:只是检测文本行,而不意味着一行(或一列)只有一个矩形框。如果想要实现,可以对文字框进行x轴(或y轴)上的合并,得到的效果如下:

3.1.2 检测方法
常用的文本检测算法包括基于传统图像处理、基于深度学习和基于OCR引擎的检测的方法。
(1)基于传统图像处理的方法
适用于规则性较强的文档图像或简单场景。首先将图像转为灰度图像,并使用Otsu或自适应二值化方法增强文本内容的对比度;随后通过形态学操作对图像进行膨胀以连接文本区域,并通过腐蚀去除非文本噪声。接着,利用OpenCV的findContours进行连通域分析,检测文本区域,并根据面积、宽高比等特征(OpenCV的boundingRect获得矩形框信息)过滤非文本区域。最后,对每个检测到的文本块生成外接矩形框,完成文本区域的定位。
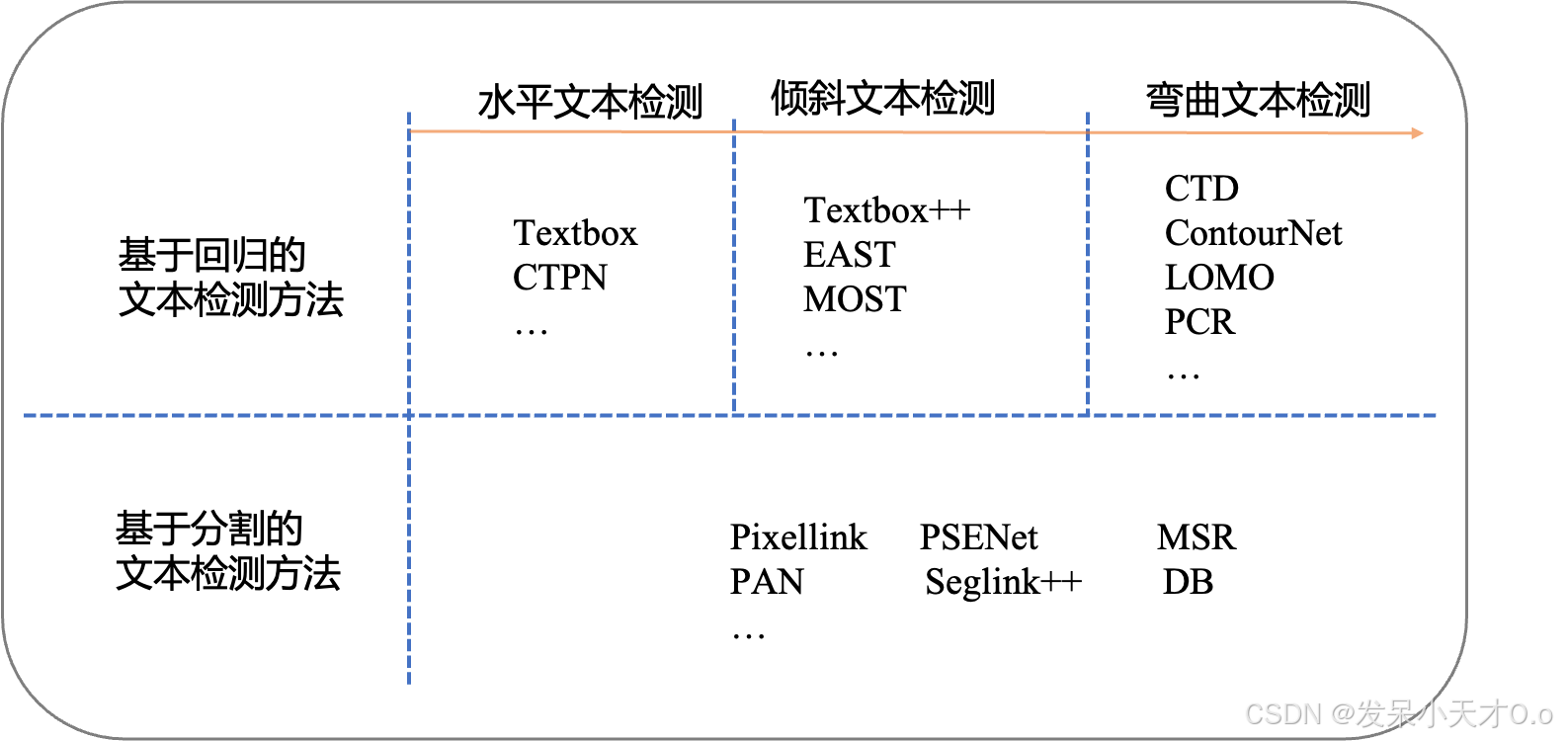
(2)基于深度学习的文本检测算法
适用于复杂文档场景或自然场景文本。可分为基于回归框的检测方法和基于像素级分割的检测方法。
-
基于回归的方法:借鉴目标检测算法,采用预测边界框的方法实现对文本的定位,典型的模型有 CTPN 和 EAST等。
- CTPN(Connectionist Text Proposal Network):是一种经典的文本检测算法,通过结合卷积神经网络(CNN)和长短期记忆网络(LSTM)的优势,有效地检测出自然场景和文档图像中的横向分布的文字。CTPN通过滑动窗口机制生成候选文本框,使用RNN连接这些小块,最终输出完整的文本行。
- EAST(Efficient and Accurate Scene Text Detector):是一种端到端的文本检测模型,能够同时检测水平和倾斜的文本。它通过全卷积网络(FCN)直接输出文本行或单词的检测结果,简化了传统的候选框提取、过滤和合并等步骤,常用作OCR识别的前置检测模块。
- CRAFT(Character Region Awareness for Text Detection): 是一种针对自然场景文本检测的算法,能够精确地检测文本实例并支持任意方向的文本。CRAFT通过检测字符级区域和其相邻关系,生成完整的文本实例边界,在多语言文本检测任务中表现优异。
- TextBoxes:是一个端到端可训练的快速文本检测器,能够在单次网络前向传播中高效且准确地检测场景文本。在不同层次的特征图后都设置了输出层,这些输出层被称为text-box layers,用于预测文本的存在和边界框。
-
基于分割的方法:基于回归的方法虽然在文本检测上取得了很好的效果,但是对解决弯曲文本往往难以得到平滑的文本包围曲线,并且模型较为复杂不具备性能优势。而基于图像分割的文本分割方法,先从像素层面做分类,判别每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线,典型的网络有 PSENet 和 DBNet等。
- PixelLink:首先将文本实例通过将同一实例中的像素链接在一起进行分割,然后直接从分割结果中提取文本边界框,无需进行位置回归。
- PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network):是一种针对复杂场景文本检测的深度学习算法,能够检测任意形状的文本,包括水平、倾斜和弯曲文本。利用不同尺度的文本核(kernels)来逐步逼近真实的文本边界。算法首先生成多个具有不同尺度的文本分割图,然后通过渐进式扩展的方式,从小尺度的文本核开始,逐步扩展到最终的文本边界。特别适用于密集文本和不规则文本的场景。
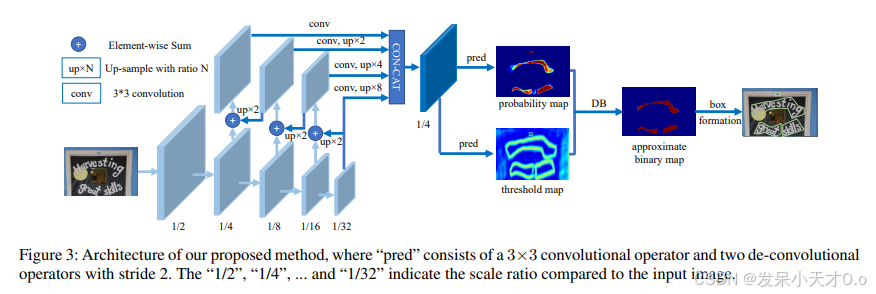
- DBNet(Differentiable Binarization Network):是一种高效的端到端文本检测算法,专注于解决复杂场景中的文本检测问题。因其高准确率和鲁棒性而备受青睐。DBNet通过骨干网络提取特征,使用DBFPN结构融合特征,最终生成概率图和阈值图,从而定位文本区域。通过引入可微分二值化(Differentiable Binarization)技术,能够自适应地学习到一个合适的二值化阈值,从而提高文本检测的精度和速度。模型参数量较少,推理速度快,适合嵌入式设备,适合实时场景。
(3)基于OCR引擎的检测的方法,如 PaddleOCR、Tesseract、EasyOCR 自带文本检测功能。
3.1.3 模型选择(DBNet)
为了平衡检测精度和实时需求,笔者最终选择DBNet进行文本行的检测。下面简单介绍一下DBNet算法。
论文题目:Real-time Scene Text Detection with Differentiable Binarization
论文地址:https://arxiv.org/abs/1911.08947
DBNet 的网络结构主要由三部分组成:
- 特征提取网络:它使用特征金字塔骨干网络(Feature-pyramid Backbone)提取多尺度特征图,然后通过特征融合(Feature Fusion)生成融合特征图。
- 检测网络:这部分网络用于预测文本区域的概率图(probability map)和阈值图(threshold map)。概率图表示每个像素属于文本区域的概率,阈值图则用于自适应地对概率图进行二值化。
- 可微分二值化(Differentiable Binarization)模块:这是 DBNet 的核心模块。通过可微分二值化(DB)模块计算出近似的二值图。传统的二值化操作是不可微分的,而 DBNet 提出了一种可微分的二值化函数。
3.2 方向分类
3.2.1 原理
方向分类器指的是针对图片中某些经文本检测得到的bounding box中的文字方向为非水平排列的情况,对bounding box的方向进行检测。如果发现bounding box中的文字方向为非水平排列,则对该bounding box的方向进行纠正,使其旋转为文字水平排列的方向,方便下一步的文本识别。由于文本的方向是影响识别准确率的关键因素之一,因此方向分类器在OCR系统中至关重要。
什么情况下不需要方向分类???什么情况下需要方向分类???
对于简单场景下(文本方向固定的场景),即图像中所有文本都是已知的水平或单一方向,如大多数标准化扫描件或印刷文档,方向分类这一步骤是可以省略的。
对于自然场景或复杂场景下(文本方向不固定的场景),即文档中包含多方向文本(例如水平、垂直、旋转角度或上下翻转等),如自然场景文本检测(街景标牌、广告牌等)、复杂场景文本检测(表格内的垂直列标题或票据中的旋转文字)。这种场景下的图片如果不经过预处理的话,识别效果会很差,比如:识别结果顺序不对、漏识率很高。因此,判断方向并矫正是很有必要的。
例如,在PaddleOCR系统中,方向分类器通常支持0度和180度的分类,以确保文本能够被正确识别。

3.2.2 分类方法
(1)基于几何特征的方法
适合规则文本方向。通过分析文本的边界框、连通域形状、像素分布等几何特征来判断方向。首先检测文本的最小外接矩形。接着计算矩形的长宽比和倾斜角度。然后根据长宽比或倾斜角判断文本的方向。
(2)基于深度学习的分类方法
使用卷积神经网络 (CNN) 等深度学习模型,直接对文本区域进行方向分类。将文本行检测框裁剪并调整为固定大小,输入分类网络,输出方向类别(如0°、90°、180°、270°)。
由于只需要对文本行矩形框进行分类,所以不需要太复杂的模型,笔者选择轻量级的分类模型。
下面介绍几种基于深度学习的轻量级分类算法:
MobileNet 系列
- MobileNetV1: 基于深度可分离卷积(Depthwise Separable Convolution)构建,这种卷积将标准卷积分解为深度卷积(对每个输入通道进行独立的卷积操作)和逐点卷积(1x1卷积,用于融合深度卷积的输出)两个部分,从而减少计算量和参数数量。
- MobileNetV2:引入了线性瓶颈(linear bottleneck)和倒残差结构(inverted residual)。线性瓶颈确保了在低维空间中进行特征转换,倒残差结构先扩展通道数,再进行深度卷积和逐点卷积,最后再压缩通道数,这种结构有助于提升模型的性能和效率。
- MobileNetV3:基于NAS实现的MnasNet,并结合了MobileNetV1的深度可分离卷积、MobileNetV2的具有线性瓶颈的倒残差结构以及基于squeeze and excitation结构的轻量级注意力模型(SE)。
ShuffleNet 系列
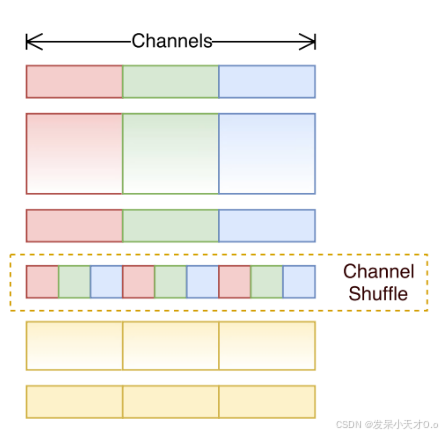
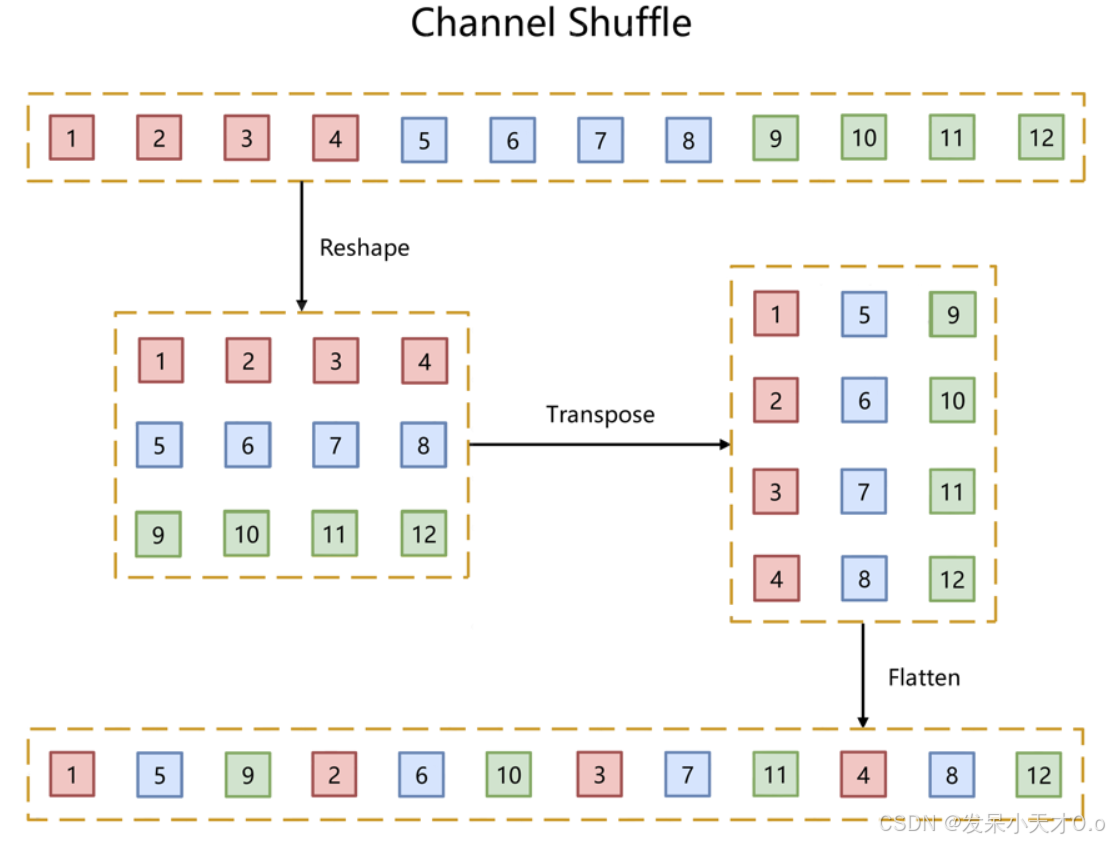
- ShuffleNetV1:提出了通道混洗(channel shuffle)操作。在分组卷积(group convolution)的基础上,通过通道混洗来实现不同组之间的信息交流,防止分组卷积带来的信息阻塞。同时,它也采用了类似深度可分离卷积的结构来减少计算量。
- ShuffleNetV2:从实际运行速度的角度出发,提出了 4 条网络设计准则,包括输入输出通道数相等、分组数适中、网络碎片化程度低和元素级操作少等。它优化了网络结构,使得在实际硬件上运行速度更快。
EfficientNet 系列
- EfficientNet-B0:提出了一种复合缩放(compound scaling)方法,通过综合考虑网络的深度、宽度和分辨率这三个维度,按照一定规则同步进行缩放,以找到最优的模型配置。它基于 MobileNet 和 NASNet 等网络的思想,利用深度可分离卷积等高效的卷积操作来构建模型,在提升准确率的同时保持相对轻量级的结构。
- EfficientNet 家族其他变体(如 EfficientNet-B1、B2 等):基于 EfficientNet-B0 的基础架构,按照复合缩放原则进一步调整深度、宽度和分辨率等参数,在不同的计算资源和性能需求下提供多种选择。随着后缀数字增大,模型通常会变得更强大但计算量也相应增加一些,不过整体相对传统大型网络仍较为轻量级。
SqueezeNet
主要采用了 Fire 模块。Fire 模块由一个挤压层(squeeze layer)和一个扩展层(expand layer)组成。挤压层是 1x1 卷积,用于减少输入通道数,扩展层包含 1x1 和 3x3 卷积,用于增加通道数并提取特征。这种结构使得模型参数大大减少。
GhostNet
提出了 Ghost 模块,核心思想是利用廉价操作生成更多的特征图。即先用常规卷积生成一部分特征图,然后通过简单的线性变换来生成其余的特征图,以此来模拟常规卷积的效果但大幅减少计算量。这种方式使得模型在保持较高分类准确率的同时能显著降低参数量和计算复杂度。
3.2.3 模型选择(ShuffleNetV2)
通过分析各种轻量级的分类网络,笔者最终选择 ShuffleNetV2 对文本行进行分类。因为该算法在设计时兼顾了内存访问代价,其参数规模和模型文件大小相对较小,内存消耗表现较好,在移动端等内存资源有限的设备上具有优势,适合对实时性要求较高的应用。
论文题目: ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
论文地址:https://arxiv.org/abs/1807.11164
为了综合考虑模型是否足够轻量化,作者将除了考虑 FLOPs 之外,还考虑了其他因素,例如内存访问时间成本 MAC (memory access cost),并行等级(degree of parallelism)。相同的 FLOPs 在不同的平台上计算时间也是不同的。为此作者提出了四条设计高效网络的准则,包括:
- G1: Equal channel width minimizes memory access cost (MAC).【等通道宽度最小化了内存访问成本(MAC)】
- G2: Excessive group convolution increases MAC.【过度的分组卷积增加了MAC】
- G3: Network fragmentation reduces degree of parallelism.【网络碎片化降低了并行度】
- G4: Element-wise operations are non-negligible.【逐元素操作不可忽视】
(1)Equal channel width minimizes memory access cost (MAC)
当卷积层输入特征矩阵与输出特征矩阵 channel 相等时,MAC 最小(保持 FLOPs 不变时)。这里主要是针对
1
×
1
1×1
1×1 的卷积层,
h
w
c
1
hwc_1
hwc1 是输入特征矩阵的内存消耗,
h
w
c
2
hwc_2
hwc2 是输出特征矩阵的内存消耗,
1
×
1
×
c
1
c
2
1×1×c_1c_2
1×1×c1c2是卷积核参数的内存消耗。由于我们的条件是 FLOPs 即 B 保持不变,使用均值不等式可以算出如下式子,取等条件是
c
1
c_1
c1 =
c
2
c_2
c2 。

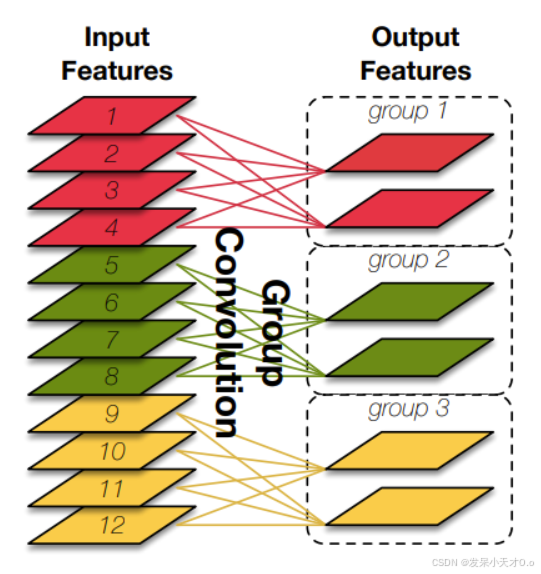
(2)Excessive group convolution increases MAC
分组卷积是先将输入特征图的通道数进行分组。然后,为每组通道分别配备独立的卷积核进行卷积运算,不同组之间的卷积操作是相互独立、互不干扰的。最后,再把各个组卷积得到的结果按照顺序拼接起来,组合成最终的输出特征图。
在分组卷积的基础上,通过通道混洗来实现不同组之间的信息交流,防止分组卷积带来的信息阻塞。
当 Group Conv 的 groups 增大时,MAC 也会增大(保持 FLOPs 不变时)。对于 Group Conv,这里主要是针对 1 × 1 1×1 1×1 的卷积层, h w c 1 hwc_1 hwc1 是输入特征矩阵的内存消耗, h w c 2 hwc_2 hwc2 是输出特征矩阵的内存消耗, 1 × 1 × ( c 1 / g ) × ( c 2 / g ) × g 1×1×(c_1/g)×(c_2/g)×g 1×1×(c1/g)×(c2/g)×g 是卷积核参数的内存消耗。当固定 FLOPs 即 B 保持不变时,可见 g 增大会造成 MAC 增大。

(3)Network fragmentation reduces degree of parallelism
当网络设计的碎片化程度越高时,推理速度越慢。很多论文中设计的网络,分支特别多,例如 Inception,SPP block 等。这里碎片化的程度可以理解为分支的程度。这个分支可以是串联也可以是并联。虽然碎片化的结构可以提升准确率,但是会降低模型的效率。
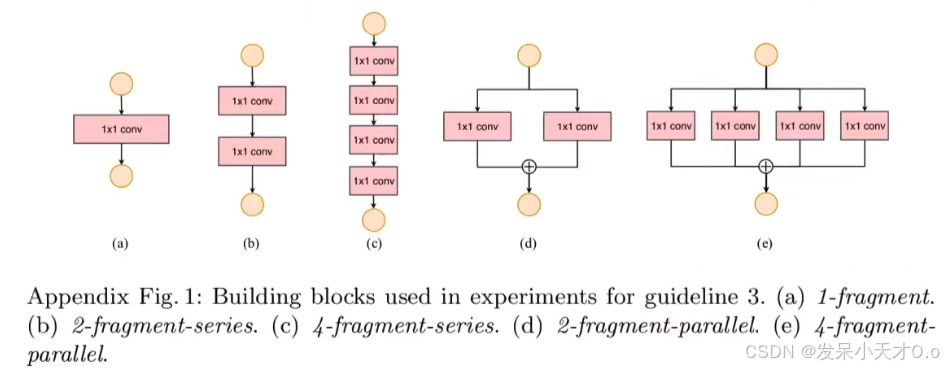
(4)Element-wise operations are non-negligible
Element-wise 操作包括激活函数,元素加法 (残差结构),卷积中的 bias。Element-wise 操作的共性是 FLOPs 很小,但是 MAC 很大。此外,DW conv 其实也可以看作是 Element-wise 操作。一系列的实验表明,不采用 short-cut 连接会更快,不采用 ReLU 会比采用 ReLU 快。有人会说,不用肯定会快呀,这里作者想要突出的是,Element-wise 操作比想象中更耗时。作者提到,如果将 short-cut 和 ReLU 都移除会有 20% 的加速。如果只看 FLOPs 的话会认为这些操作并不怎么占用时间。
3.3 文字识别
3.3.1 原理与方法
文字识别是将文本检测得到的bounding box中的具体的文字内容识别出来。
目前存在几种基于深度学习的文本识别方法。卷积神经网络(CNN) : CNN 常用于基于图像的文本识别。输入图像由卷积层提供动力,卷积层提取特征并学习文本表示。然后 CNN 的输出被传送到一个递归神经网络(RNN)进行进一步的处理和文本识别。递归神经网络: 递归神经网络广泛应用于基于序列的文本识别,如手写和语音识别。RNN 使用反馈回路来处理序列数据,允许它们捕获长期依赖和上下文信息。编码器-解码器网络: 编码器-解码器网络用于端到端的文本识别。首先将输入图像编码成特征向量,然后将其解码成一系列字符或单词。这些网络可以进行端到端的训练,提高效率和准确性。
(1)传统文字识别算法:
主要基于图像处理技术(如投影、膨胀、旋转等),结合opencv库实现或采用统计机器学习方法实现特征提取。使用边缘检测、HOG、SIFT等方法提取字符的轮廓和形状特征。然后利用SVM、KNN等方法对字符分类。
(2)深度学习文字识别算法:
主要包括基于CTC、基于Attention、基于Transformer、基于分割及端到端识别等几种方法。
-
基于CTC识别算法主要为CRNN,CTC损失可以解决序列对齐问题,推理速度快,识别精度高。
-
基于Attention识别算法主要有ASTER、RAEN等,结合注意力机制基本思想让系统学会注意力关注重点信息,同时忽略无关信息,有效提升精度。
-
端到端识别主要有STN-OCR、FOTS、ABCnet、MORAN等方法,无需检测后在识别,可以实现端到端识别。

3.3.2 模型选择(CRNN)
论文题目: An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文地址:http://arxiv.org/abs/1507.05717
卷积回归神经网络(Convolutional Recurrent Neural Network,CRNN)是2015年被提出的,到目前为止还是被广泛应用。CRNN的主要结构包括基于CNN的图像特征提取模块以及基于多层双向LSTM的文字序列特征提取模块。
主要思想是卷积神经网络(CNN)在处理图像数据方面是很好的,而对于像文本这样的序列数据,回归神经网络(RNN)是首选的。而文本识别其实需要对序列进行预测,所以采用了预测序列常用的RNN网络。算法通过CNN提取图片特征,然后采用RNN对序列进行预测,最终使用CTC方法得到最终结果。
CRNN的网络架构由三部分组成,从底向上包括卷积层,循环层和转录层。
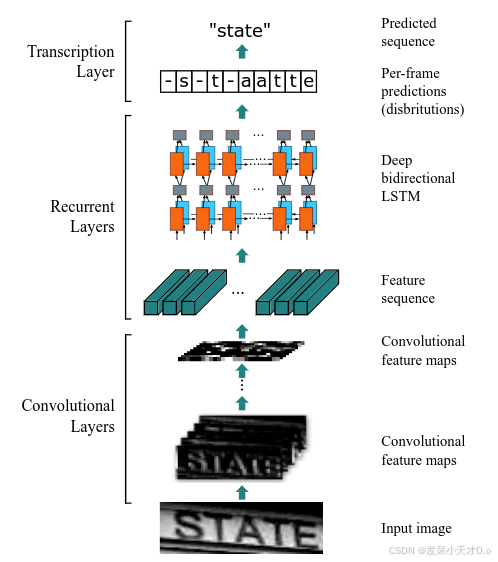

(1)第一模块: 使用CNN网络,对输入图像进行特征提取,从而得到特征图。
(2)第二模块: Im2Seq,将CNN获取的特征图变换为RNN需要的特征向量序列的形状;
输入图像首先通过若干卷积层以提取特征图。这些特征图随后被分割成一系列特征向量,如墨绿色部分所示。这些特征向量是通过将特征图按单像素宽度划分为列获得的。具体是在处理特征图时,将特征图按照列的方式分割开来,每一列的宽度是 1 个像素。每一列的像素值(沿着高度方向的一组值)被看作一个特征向量。这些特征向量实际上是将特征图从二维(高度和宽度)形式转换为一组一维向量的过程。
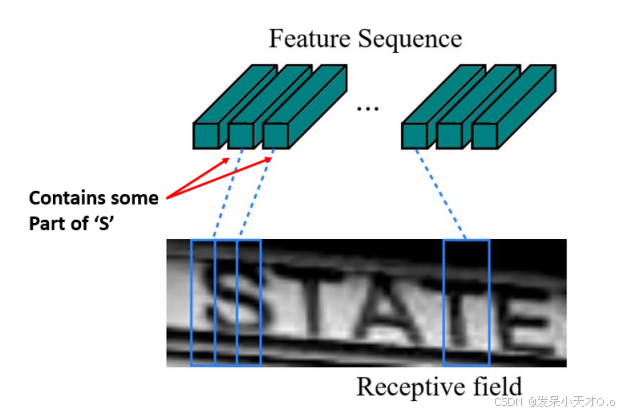
为什么要按列对特征图进行划分?这个问题的答案与感受野(Receptive Field)的概念有关。感受野被定义为特定卷积神经网络(CNN)的特征图所关注的输入图像中的区域。例如,对于上方输入图像,每个特征向量的感受野对应于输入图像中的一个矩形区域(每列对应于特定的感受野),如下图所示。
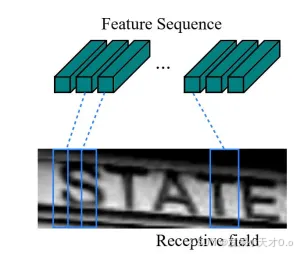
并且每个矩形区域按照从左到右的顺序排列。因此,每个特征向量可以看作该矩形区域的图像描述符。这些特征向量随后被输入到一个双向LSTM中。
但是,正如你在上图中可能注意到的,这些特征向量有时可能无法包含完整的字符。例如,请看下图,其中用红色标记的两个特征向量仅包含了字符“S”的一部分。
因此,在 LSTM 的输出中,我们可能会得到重复的字符,如下图红色框所示。我们将这些称为每帧或每时间步的预测。
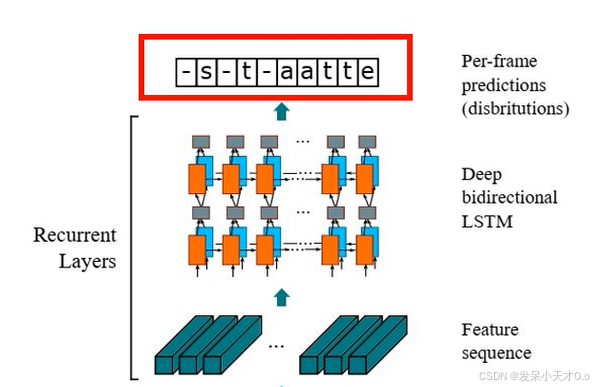
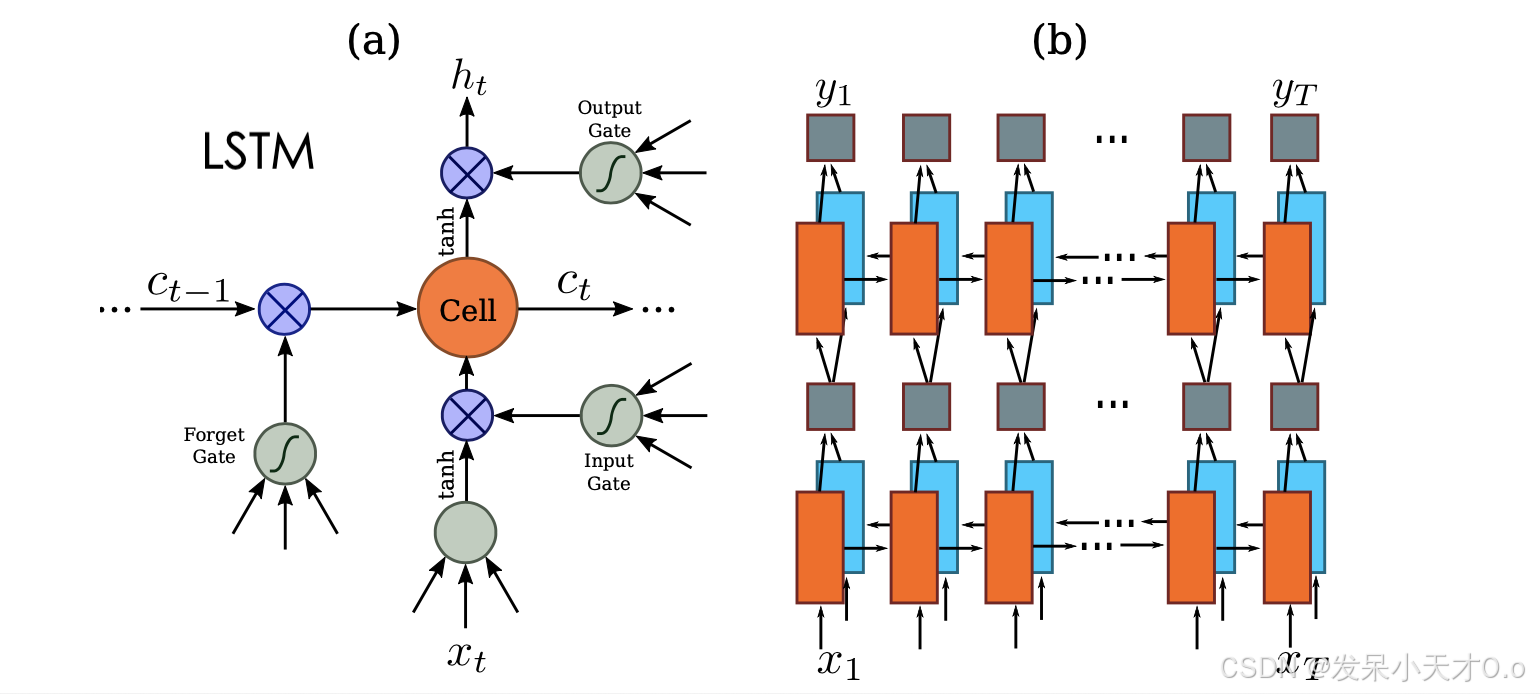
(3)第三模块: 使用双向LSTM(Bidirectional LSTM,BiLSTM)捕获特征序列中的上下文关系,提取序列相关的特征。
双向LSTM是一种扩展的 LSTM(长短期记忆网络)模型,能够同时考虑序列数据中从前到后和从后到前的上下文信息。每个时间步输出一个特征向量。
单向LSTM与双向LSTM的区别???
单向LSTM:只能从过去的时间步推断未来,即模型依次从序列的开头处理到末尾。每个时间步的输出仅依赖于当前和之前的时间步。
双向LSTM:同时从两个方向处理序列:正向处理:从序列的开头到末尾。反向处理:从序列的末尾到开头。每个时间步的输出由正向和反向两个 LSTM 的结果共同决定(通常是连接或相加),因此可以捕获更全面的上下文信息。
(4)第四模块: 使用全连接层将双向LSTM输出的特征向量的维度转换为与分类类别数量相同的大小,随后再通过 Softmax 完成分类。
双向LSTM的输出是为输入序列的每个时间步生成一个特征向量,这些特征向量会通过一个全连接层映射到字符集(分类的类别)的维度。需要注意的是,分类的类别包括所有要预测的字符加上一个空白符(blank ε)。通常我们在 One-hot 编码时会将空白符 ε 放在索引为 index=0 的位置。然后对每个时间步的特征向量使用 Softmax 函数生成一个概率分布,表示当前时间步可能对应的所有字符的概率。然而,在评估输出时,需要结合所有时间步的信息计算 CTC Loss。
(5)第五模块: CTC转录层,将每个时间步的预测结果结合起来,通过 CTC Loss 计算整个序列的输出与目标字符序列的匹配程度,得到最终输出。
RNN只能在已经分配好的序列上进行训练。这意味着,如果你只有目标序列标签还不足够,还需要知道这些标签应该如何分配到输入序列中。例如:假设你要识别一张图片中的单词 “cat”,并希望使用 RNN 来完成任务,而 RNN 的输入长度为 6(即有 6个时间步)。为了训练 RNN,你需要提供每个时间步的真实标签(Ground Truth)。这意味着你需要将 “cat” 这 3 个字符分配到这 6个时间步中。这种标注过程既费时又不现实,因此我们希望能够直接利用没有明确分配的序列标签进行训练。

CTC 的作用:
CTC(连接时序分类,Connectionist Temporal Classification)设计了一种机制,使得我们可以直接训练模型,而无需明确对齐输入和输出。可理解为它是一种用于序列学习任务的特殊输出层。它通过以下方法实现:
- 引入空白符(blank ε):在原本需要预测的字符集中,增加一个特殊的空白符 blank ε,用来表示时间步没有输出具体字符。
- 映射机制 B:CTC 定义了一种映射机制 B,将输出序列转换为最终的预测序列。
- 合并相邻的相同字符。例如,C-C-A-A-T-T 会被映射为 C-A-T。
- 移除空白符(blank ε)。例如,C-ε-A-ε-T 会被映射为 C-A-T。
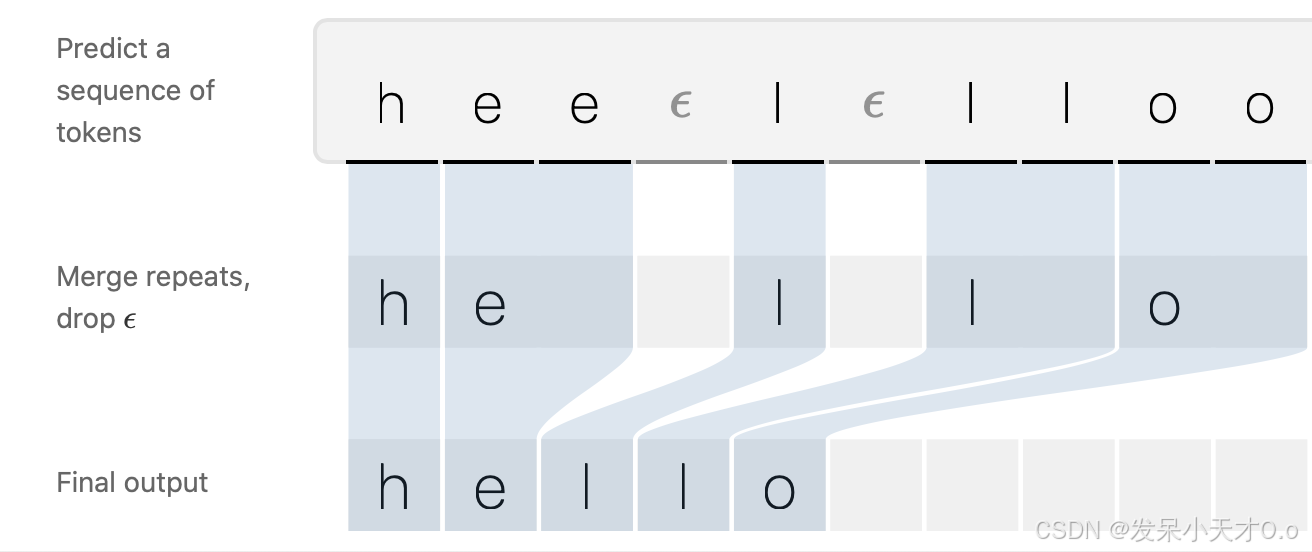
有了这个映射机制 B,我们就可以在不需要事先分配序列标签的情况下训练网络。但需要注意的是:能够映射到同一组序列标签的组合有很多种可能性。
例如:输入序列 “hee-l-lloo” 和 “hheel-lloo” 都会通过映射机制 B 转化为目标序列 “hello”。
因此,为了正确处理这种情况,需要特别设计一个损失函数(Loss),让它能够综合考虑所有可能的映射路径。
CTC Loss:
在映射函数 B 的作用下,目标序列标签可能由多种输入序列组合生成。举例来说,目标序列 “cat” 可以由这些输入序列组合生成:C-ε-A-ε-T、C-C-A-T-T、C-ε-A-A-T,这些组合都被认为是有效路径。
CTC Loss 会同时考虑所有可能的路径。它通过计算所有路径生成目标序列的总概率,来衡量模型输出与目标序列之间的匹配程度。换句话说,CTC Loss 的优化目标是提升所有路径生成目标序列的概率之和。为了高效计算所有路径的总概率,CTC 使用了前向-后向算法(类似于 HMM 中的动态规划)。通过前向和后向递推,可以在多项式时间内完成路径总概率的计算,而不需要枚举所有可能的路径。
4. 模型训练
4.1 DBNet
参考代码地址:https://github.com/WenmuZhou/DBNet.pytorch
环境部署
conda create -n dbnet python=3.6
conda activate dbnet
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
pip install -r requirement.txt
下载代码
git clone https://github.com/WenmuZhou/DBNet.pytorch.git
cd DBNet.pytorch/
数据准备
训练数据:准备以下格式的文本 train. txt,使用 ‘\t’ 作为分隔符
./datasets/train/img/001.jpg ./datasets/train/gt/001.txt
验证数据:准备以下格式的文本 val.txt,使用 ‘\t’ 作为分隔符
./datasets/val/img/001.jpg ./datasets/val/gt/001.txt
txt 文件格式如下:
x1, y1, x2, y2, x3, y3, x4, y4, annotation
模型训练
在 config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml 中配置训练和验证数据集的 .txt 文件路径。

使用单一 GPU 训练:
bash singlel_gpu_train.sh
使用多 GPU 训练:
bash multi_gpu_train.sh
4.2 ShuffleNetV2
参考代码地址:https://github.com/Lornatang/ShuffleNetV2-PyTorch
环境部署
conda create -n shufflenetv2 python=3.8
conda activate shufflenetv2
pip install -r requirements.txt
下载代码
git clone https://github.com/Lornatang/ShuffleNetV2-PyTorch.git
数据准备
划分为训练集和验证集,类别有四类,包括0、90、180、270。数据集目录结构如下所示:
- dataset
- train
- 0
- 0_0.JPEG
- 0_1.JPEG
- 90
- 180_0.JPEG
- ...
- val
- 0
- 0_0.JPEG
- ...
模型训练
训练和测试都只需要修改该config.py文件即可。比如训练数据路径、类别数、epoch、模型保存路径等参数。
python train.py
4.3 CRNN
参考代码地址:https://github.com/AstarLight/Lets_OCR/tree/master/recognizer/crnn
环境部署
CTC安装:
git clone https://github.com/SeanNaren/warp-ctc.git
cd warp-ctc
git checkout ac045b6072b9bc3454fb9f9f17674f0d59373789
mkdir build; cd build
cmake ..
make
cd ../pytorch_binding/
python setup.py install
cd ../build
cp libwarpctc.so ../../usr/lib
下载代码
git clone https://github.com/meijieru/crnn.pytorch.git
数据准备
数据集图片示例:

划分为训练集和验证集:

标签文件.txt,内容形式如下:

之后获取标签的字符集,并将得到的字符集写入alphabet.py,代码如下:
def generate_alphabet_from_labels(file_path):
"""
从标签文件中生成 alphabet(字符表)。
Args:
file_path (str): 标签文件的路径。
Returns:
str: 包含所有字符的去重排序后的字符表。
"""
all_characters = set()
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 解析每行,假设格式为: "图片名 标签"
parts = line.strip().split(' ', 1) # 按第一个空格分割
if len(parts) > 1:
label = parts[1] # 提取标签部分
all_characters.update(label) # 添加标签中的所有字符到集合中
# 将字符集合转为排序后的字符串
alphabet = ''.join(sorted(all_characters))
return alphabet
# 示例:文件路径
file_path = "train.txt"
alphabet = generate_alphabet_from_labels(file_path)
print("Generated Alphabet:", alphabet)

之后为了高效管理和快速读取大规模训练数据,创建适用于 CRNN 训练的 LMDB 数据集。首先读入图像和对应的文本标签,先使用字典将该组合存储起来(cache),再利用lmdb包的put函数把字典(cache)存储的k,v写成lmdb格式存储好(cache当有了1000个元素就put一次)。实现代码如下:
import lmdb
import cv2
import numpy as np
import os
def checkImageIsValid(imageBin):
if imageBin is None:
return False
try:
imageBuf = np.frombuffer(imageBin, dtype=np.uint8)
img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)
imgH, imgW = img.shape[0], img.shape[1]
except:
return False
else:
if imgH * imgW == 0:
return False
return True
def writeCache(env, cache):
with env.begin(write=True) as txn:
for k, v in cache.items():
# 对键和值进行编码
txn.put(k.encode('utf-8'), v if isinstance(v, bytes) else v.encode('utf-8'))
def createDataset(outputPath, imagePathList, labelList, lexiconList=None, checkValid=True):
"""
Create LMDB dataset for CRNN training.
ARGS:
outputPath : LMDB output path
imagePathList : list of image path
labelList : list of corresponding groundtruth texts
lexiconList : (optional) list of lexicon lists
checkValid : if true, check the validity of every image
"""
assert (len(imagePathList) == len(labelList))
nSamples = len(imagePathList)
env = lmdb.open(outputPath, map_size=1024 * 1024 * 1024)
cache = {}
cnt = 1
for i in range(nSamples):
imagePath = ''.join(imagePathList[i]).split()[0].replace('\n', '').replace('\r\n', '')
# print(imagePath)
label = ''.join(labelList[i])
print(label)
# if not os.path.exists(imagePath):
# print('%s does not exist' % imagePath)
# continue
with open(imagePath, 'rb') as f: # 使用 'rb' 模式读取二进制数据
imageBin = f.read()
if checkValid:
if not checkImageIsValid(imageBin):
print('%s is not a valid image' % imagePath)
continue
imageKey = 'image-%09d' % cnt
labelKey = 'label-%09d' % cnt
cache[imageKey] = imageBin
cache[labelKey] = label
if lexiconList:
lexiconKey = 'lexicon-%09d' % cnt
cache[lexiconKey] = ' '.join(lexiconList[i])
if cnt % 1000 == 0:
writeCache(env, cache)
cache = {}
print('Written %d / %d' % (cnt, nSamples))
cnt += 1
print(cnt)
nSamples = cnt - 1
cache['num-samples'] = str(nSamples)
writeCache(env, cache)
print('Created dataset with %d samples' % nSamples)
OUT_PATH = './crnn_train_lmdb'
IN_PATH = './train.txt'
if __name__ == '__main__':
outputPath = OUT_PATH
if not os.path.exists(OUT_PATH):
os.mkdir(OUT_PATH)
with open(IN_PATH, 'r', encoding='utf-8') as imgdata:
imagePathList = list(imgdata)
labelList = []
for line in imagePathList:
word = line.split()[1]
labelList.append(word)
createDataset(outputPath, imagePathList, labelList)
注意:在调用 lmdb.open 创建 LMDB 数据库时,如果map_size设置太大的话,会发生了磁盘空间不足的错误。
lmdb.Error: ./crnn_train_lmdb: ���̿ռ䲻�㡣
如果不确定需要多大的空间,可以设置一个较小的初始值(例如 1GB),在运行中当 LMDB 空间不足时,动态调整 map_size:
env = lmdb.open(outputPath, map_size=1024 * 1024 * 1024) # 初始 1GB
最后数据集目录结构如下所示:
- dataset
- crnn_train_lmdb
- data.mdb
- lock.mdb
- crnn_val_lmdb
- data.mdb
- lock.mdb
- train.txt
- val.txt
- 1.jpg
- 2.jpg
- ...
在生成的 LMDB 数据集中,data.mdb 文件是存储实际数据的核心文件,用于训练模型。
- data.mdb:包含所有的图像、标签和其他数据,是训练时加载的主要文件。
- lock.mdb:是 LMDB 的锁文件,用于管理对数据库的并发访问。训练时不会直接使用它。
另外,还需要将文字标签进行数字化表示,即用数字表示每一个文字(汉字,英文字母,标点符号)。比如“我”字对应的id是1,“l”对应的id是1000,“?”对应的id是90,如此类推,这种编解码工作使用字典数据结构存储即可,训练时先把标签编码(encode),预测时就将网络输出结果解码(decode)成文字输出。代码如下:
class strLabelConverter(object):
"""Convert between str and label.
NOTE:
Insert `blank` to the alphabet for CTC.
Args:
alphabet (str): set of the possible characters.
ignore_case (bool, default=True): whether or not to ignore all of the case.
"""
def __init__(self, alphabet, ignore_case=False):
self._ignore_case = ignore_case
if self._ignore_case:
alphabet = alphabet.lower()
self.alphabet = alphabet + '-' # for `-1` index
self.dict = {}
for i, char in enumerate(alphabet):
# NOTE: 0 is reserved for 'blank' required by wrap_ctc
self.dict[char] = i + 1
def encode(self, text):
"""Support batch or single str.
Args:
text (str or list of str): texts to convert.
Returns:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
"""
length = []
result = []
for item in text:
item = item.decode('utf-8', 'strict')
length.append(len(item))
for char in item:
index = self.dict[char]
result.append(index)
text = result
# print(text,length)
return (torch.IntTensor(text), torch.IntTensor(length))
def decode(self, t, length, raw=False):
"""Decode encoded texts back into strs.
Args:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
Raises:
AssertionError: when the texts and its length does not match.
Returns:
text (str or list of str): texts to convert.
"""
if length.numel() == 1:
length = length[0]
assert t.numel() == length, "text with length: {} does not match declared length: {}".format(t.numel(),
length)
if raw:
return ''.join([self.alphabet[i - 1] for i in t])
else:
char_list = []
for i in range(length):
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i] - 1])
return ''.join(char_list)
else:
# batch mode
assert t.numel() == length.sum(), "texts with length: {} does not match declared length: {}".format(
t.numel(), length.sum())
texts = []
index = 0
for i in range(length.numel()):
l = length[i]
texts.append(
self.decode(
t[index:index + l], torch.IntTensor([l]), raw=raw))
index += l
return texts
模型训练
可以在文件config.py里修改训练时用到的参数,比如训练数据路径、epoch、模型保存路径等参数。
python train.py
5. 模型转换
首先把训练好的 .pt 模型转换为 .onnx模型。
dbnet转换:
import torch
import numpy as np
import onnx
from models.model import Model
# 加载模型权重
model_path = "dbnet.pt"
model_weights = torch.load(model_path, map_location=torch.device('cpu'))
# 定义模型配置
model_config = {
'backbone': {'type': 'resnet18', 'pretrained': True, "in_channels": 3},
'neck': {'type': 'FPN', 'inner_channels': 256},
'head': {'type': 'DBHead', 'out_channels': 2, 'k': 50},
}
# 实例化模型
model = Model(model_config=model_config)
# 将权重加载到模型中
model.load_state_dict(model_weights)
# 设置模型为评估模式
model.eval()
# 构造输入张量(需要根据模型的实际输入尺寸设置)
# 示例输入张量,假设输入是3通道RGB图像,分辨率为736x736
dummy_input = torch.randn(1, 3, 736, 736)
# 导出为ONNX格式
onnx_path = "dbnet.onnx"
torch.onnx.export(
model,
dummy_input,
onnx_path,
export_params=True, # 存储训练好的参数
opset_version=11, # ONNX opset版本
input_names=['input'], # 输入张量的名称
output_names=['output'], # 输出张量的名称
)
print(f"ONNX模型已保存到: {onnx_path}")
shufflenetv2转换:
import torch
import numpy as np
import onnx
from model import shufflenet_v2_x1_0
model = shufflenet_v2_x1_0()
model.load_state_dict(torch.load('shufflenetv2.pt', map_location=torch.device('cpu')))
model.eval()
with torch.no_grad():
input_img = torch.randn(1, 3, 224, 224)
onnx_path = "dbnet.onnx"
torch.onnx.export(
model,
input_img,
onnx_path,
export_params=True, # 存储训练好的参数
opset_version=11, # ONNX opset版本
input_names=['input'], # 输入张量的名称
output_names=['output'], # 输出张量的名称
)
crnn转换:
import torch
import numpy as np
import onnx
from Net.net import CRNN
model = CRNN(class_num=len(Config.alphabet) + 1 )
model.load_state_dict(torch.load('crnn.pt', map_location=torch.device('cpu')))
model.eval()
with torch.no_grad():
input_img = torch.randn(1, 3, 48, 320)
onnx_path = "crnn.onnx"
torch.onnx.export(
model,
input_img,
onnx_path,
export_params=True, # 存储训练好的参数
opset_version=11, # ONNX opset版本
input_names=['input'], # 输入张量的名称
output_names=['output'], # 输出张量的名称
)
6. 模型C++推理
(1)DBNet文本检测
std::vector<std::vector<cv::Point2f>> TextDetector::detect(cv::Mat& srcimg)
{
float* blob = nullptr;
int h = srcimg.rows;
int w = srcimg.cols;
cv::Mat dstimg = this->preprocess(srcimg);
this->normalize_(dstimg,blob);
std::vector<int64_t> inputTensorShape{ 1, 3, dstimg.rows, dstimg.cols };
size_t inputTensorSize = utils::vectorProduct(inputTensorShape);
std::vector<float> inputTensorValues(blob, blob + inputTensorSize);
std::vector<Ort::Value> inputTensors;
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorSize,
inputTensorShape.data(), inputTensorShape.size()));
std::vector<Ort::Value> outputTensors = this->session.Run(Ort::RunOptions{ nullptr },
this->inputNames.data(),
inputTensors.data(),
1,
this->outputNames.data(),
this->outputNames.size());
const float* floatArray = outputTensors[0].GetTensorMutableData<float>();
int outputCount = 1;
for (int i = 0; i < outputTensors.at(0).GetTensorTypeAndShapeInfo().GetShape().size(); i++)
{
int dim = outputTensors.at(0).GetTensorTypeAndShapeInfo().GetShape().at(i);
outputCount *= dim;
}
cv::Mat binary(dstimg.rows, dstimg.cols, CV_32FC1);
std::memcpy(binary.data, floatArray, outputCount * sizeof(float));
// 阈值化
cv::Mat bitmap;
cv::threshold(binary, bitmap, binaryThreshold, 255, cv::THRESH_BINARY);
// Scale ratio
float scaleHeight = (float)(h) / (float)(binary.size[0]);
float scaleWidth = (float)(w) / (float)(binary.size[1]);
// 寻找轮廓
std::vector<std::vector<cv::Point>> contours;
bitmap.convertTo(bitmap, CV_8UC1);
cv::findContours(bitmap, contours, cv::RETR_LIST,cv::CHAIN_APPROX_SIMPLE);
// 限制候选数量
size_t numCandidate = std::min(contours.size(), (size_t)(maxCandidates > 0 ? maxCandidates : INT_MAX));
// 计算每个轮廓的置信度分数,并存储索引和分数
std::vector<std::pair<float, size_t>> scores;
for (size_t i = 0; i < contours.size(); i++) {
float score = contourScore(binary, contours[i]);
scores.emplace_back(score, i);
}
// 按置信度降序排序
std::sort(scores.begin(), scores.end(), [](const std::pair<float, size_t>& a, const std::pair<float, size_t>& b) {
return a.first > b.first;
});
// 选择置信度最高的 numCandidate 个轮廓
std::vector<std::vector<cv::Point>> selectedContours;
for (size_t i = 0; i < numCandidate; i++) {
selectedContours.push_back(contours[scores[i].second]);
}
std::vector<std::vector<cv::Point2f>> results;
for (const auto& contour : selectedContours) {
// Rescale
std::vector<cv::Point> contourScaled;
contourScaled.reserve(contour.size());
for (const auto& point : contour) {
contourScaled.push_back(cv::Point(int(point.x * scaleWidth), int(point.y * scaleHeight)));//映射到输入图像上的坐标
}
//如果矩形的最长边小于这个值,说明该轮廓太小,可能是噪声或无意义的目标
cv::RotatedRect box = minAreaRect(contourScaled);
float longSide = std::max(box.size.width, box.size.height);//计算矩形的最长边
if (longSide < longSideThresh) {
continue;
}
// 获取旋转矩形的四个顶点
cv::Point2f vertex[4];
box.points(vertex); // 顶点顺序:bl, tl, tr, br
std::vector<cv::Point2f> approx;
for (int j = 0; j < 4; j++)
approx.emplace_back(vertex[j]);
// 多边形扩展
std::vector<cv::Point2f> polygon;
unclip(approx, polygon);
// 再次检查解包后的轮廓
box = minAreaRect(polygon);
longSide = std::max(box.size.width, box.size.height);
if (longSide < longSideThresh + 2) {
continue;
}
results.push_back(polygon);
}
delete[] blob;
return results;
}

(2)ShuffleNet v2文本分类器
- 对每个文本检测框进行裁剪。
cv::Mat TextDetector::get_rotate_crop_image(const cv::Mat& frame, std::vector<cv::Point2f> vertices) {
if (vertices.size() != 4) {
throw std::invalid_argument("Vertices must contain exactly 4 points.");
}
// **动态调整顶点顺序**
// 按照 y 进行排序,前两个点是上边缘,后两个点是下边缘
std::sort(vertices.begin(), vertices.end(), [](const cv::Point2f& a, const cv::Point2f& b) {
return a.y < b.y; // 按 y 坐标从小到大排序
});
// 对上边缘点,按 x 排序,左为左上,右为右上
if (vertices[0].x > vertices[1].x) std::swap(vertices[0], vertices[1]);
// 对下边缘点,按 x 排序,左为左下,右为右下
if (vertices[2].x > vertices[3].x) std::swap(vertices[2], vertices[3]);
// 确保顺序为:左上、左下、右下、右上
std::vector<cv::Point2f> correctedVertices{
vertices[0], // 左上
vertices[2], // 左下
vertices[3], // 右下
vertices[1] // 右上
};
// **计算裁剪区域**
cv::Rect rect = cv::boundingRect(cv::Mat(correctedVertices));
cv::Mat crop_img = frame(rect);
// 调整裁剪区域内的顶点坐标
for (int i = 0; i < 4; i++) {
correctedVertices[i].x -= rect.x;
correctedVertices[i].y -= rect.y;
}
// **目标顶点**
cv::Size outputSize(rect.width, rect.height);
std::vector<cv::Point2f> targetVertices{
cv::Point2f(0, 0), // 左上
cv::Point2f(0, outputSize.height - 1), // 左下
cv::Point2f(outputSize.width - 1, outputSize.height - 1), // 右下
cv::Point2f(outputSize.width - 1, 0) // 右上
};
// **计算透视变换矩阵**
cv::Mat rotationMatrix = cv::getPerspectiveTransform(correctedVertices, targetVertices);
// **应用透视变换**
cv::Mat result;
cv::warpPerspective(crop_img, result, rotationMatrix, outputSize, cv::BORDER_CONSTANT, 0);
return result;
}

- 裁剪后,送入分类器,调整文本方向。
int TextClassifier::predict(cv::Mat cv_image)
{
float* blob{ nullptr };
cv::Mat dstimg = this->preprocess(cv_image);
this->normalize_(dstimg, blob);
std::vector<int64_t> inputTensorShape{ 1, 3, this->inpHeight, this->inpWidth };
size_t inputTensorSize = utils::vectorProduct(inputTensorShape);
std::vector<float> inputTensorValues(blob, blob + inputTensorSize);
std::vector<Ort::Value> inputTensors;
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorSize,
inputTensorShape.data(), inputTensorShape.size()));
std::vector<Ort::Value> outputTensors = this->session.Run(Ort::RunOptions{ nullptr },
this->inputNames.data(),
inputTensors.data(),
1,
this->outputNames.data(),
this->outputNames.size());
const float* floatArray = outputTensors[0].GetTensorMutableData<float>();//输出张量
int max_id = 0;
float max_prob = -1;
for (int i = 0; i < num_out; i++)
{
if (floatArray[i] > max_prob)
{
max_prob = floatArray[i];
max_id = i;
}
}
return max_id;
}
(3)CRNN文本识别
std::string TextRecognizer::predict_text(cv::Mat cv_image)
{
float* blob{ nullptr };
cv::Mat dstimg = this->preprocess(cv_image);
this->normalize_(dstimg, blob);
std::vector<int64_t> inputTensorShape{ 1, 3, this->inpHeight, this->inpWidth };
size_t inputTensorSize = utils::vectorProduct(inputTensorShape);
std::vector<float> inputTensorValues(blob, blob + inputTensorSize);
std::vector<Ort::Value> inputTensors;
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorSize,
inputTensorShape.data(), inputTensorShape.size()));
std::vector<Ort::Value> outputTensors = this->session.Run(Ort::RunOptions{ nullptr },
this->inputNames.data(),
inputTensors.data(),
1,
this->outputNames.data(),
this->outputNames.size());
const float* floatArray = outputTensors[0].GetTensorMutableData<float>();//模型输出的张量是一个二维数组,表示每个时间步上所有类别的概率分布
int i = 0, j = 0;
int h = outputTensors.at(0).GetTensorTypeAndShapeInfo().GetShape().at(2);//h 是每个时间步的类别数量(字符集大小+1,包含空白字符)
int w = outputTensors.at(0).GetTensorTypeAndShapeInfo().GetShape().at(1);//w 是时间步的数量(序列长度)
preb_label.resize(w);
for (i = 0; i < w; i++)
{
int one_label_idx = 0;
float max_data = -10000;
for (j = 0; j < h; j++)
{
float data_ = floatArray[i * h + j];
if (data_ > max_data)
{
max_data = data_;
one_label_idx = j;
}
}
preb_label[i] = one_label_idx;
}
//去掉重复的类别和空白符(CTC解码需要移除重复字符和空白符)
std::vector<int> no_repeat_blank_label;
for (size_t elementIndex = 0; elementIndex < w; ++elementIndex)
{
if (preb_label[elementIndex] != 0 && !(elementIndex > 0 && preb_label[elementIndex - 1] == preb_label[elementIndex]))//空白符(通常索引为0)
{
no_repeat_blank_label.push_back(preb_label[elementIndex] - 1);
}
}
//将类别索引转换为字符
int len_s = no_repeat_blank_label.size();
std::string plate_text;
for (i = 0; i < len_s; i++)
{
plate_text += alphabet[no_repeat_blank_label[i]];
}
return plate_text;
}
考虑到,识别到的文本顺序应与输入图像的内容顺序保持一致,笔者首先对检测到的文本框进行了简单排序。对长文本进行识别,容易导致识别错误和识别不全。因此,笔者将文本框分为短文本框和长文本框进一步处理。对于短文本框,直接进行识别。而对于长文本框,笔者对其进行分段识别,最后再将其识别结果拼接起来。
int textWidth = textimg.cols;
std::string full_text = "";
if (textWidth < 250) // 对于短文本框
{
std::string text = text_rec.predict_text(textimg);
full_text = text;
}
else // 对于长文本框
{
int segmentWidth = 250; // 每段的固定宽度
int numSegments = std::ceil((float)textWidth / segmentWidth); // 计算需要的分段数
for (int seg = 0; seg < numSegments; ++seg) {
// 计算分段的ROI区域,按从左到右顺序划分
int startX = seg * segmentWidth;
int endX = std::min(startX + segmentWidth, textWidth); // 计算每段的结束位置
// 裁剪当前段
cv::Rect roi(startX, 0, endX - startX, textimg.rows);
cv::Mat segment = textimg(roi);
// OCR 识别当前段
std::string segment_text = text_rec.predict_text(segment);
full_text += segment_text; // 拼接段落结果
}


















 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









