







介绍
本地环境:家用Windows 10系统,无GPU。
Ollama开源框架,专门用于在本地机器部署和运行大型语言模型(LLM)。
- 简化部署:简化在Docker容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。
- 轻量级与可扩展:作为轻量级框架,Ollama保持较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
- API支持:简洁API,开发者能轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
- 预构建模型库:包含多个预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
- 模型导入与定制:支持从特定平台(如GGUF)导入已有的大型语言模型,兼容PyTorch(满足微调需求)或Safetensors深度学习框架,允许用户将基于这些框架训练的模型集成到Ollama中。
- 跨平台支持:提供针对macOS、Windows、Linux以及Docker的安装指南,确保用户能在多种操作系统环境下顺利部署和使用Ollama。
下载安装Ollama
下载地址:Download Ollama on macOS,点击安装,完成后可在cmd中使用 ollama -v 命令查看版本及是否安装正确。
可点击上图中左上的Models按钮,选择需要挂载的大模型,可根据具体情况选择。
- Nvidia独立显卡(带有Cuda),根据显存大小选择,基本上1b参数=1G显存,例如6G以下显存的家用Nvidia显卡,选择7b、8b左右的轻量级模型。
- 集成显卡,根据性能、内存频宽可选择1.5b、2b、3b的超轻量级模型,处理器性能较强且内存频率&容量够大的,可以选择7b、8b左右的轻量级模型。
- Nvidia旗舰独立显卡、专业计算卡,根据显存大小可选择32b、70b模型,1b参数≈1G显存。
- 阵列专业计算卡、超融合大模型一体机,可选择405b、671b的满血大模型。
由于训练语料不同,不同大模型支持的语言不同,国产对中文支持度最好的大模型是qwen2.5,以及通过qwen2.5蒸馏出的DeepseekR1(以下简称DSR1):qwen。使用英文语料训练的llama系列不适用于中文场景。
DSR1是DSv3的逻辑链增强,只有671b的满血版才是真正的DSR1,其他参数量的模型均蒸馏自对应参数量的模型,例如DSR1:7b蒸馏自qwen2.5:7b、DSR1:8b蒸馏自llama3.1:8b,在ollama的DSR1详情页面处有标注。可以理解为qwen2.5带了逻辑链的大模型,本身推理能力相较于qwen2.5没有质的飞跃,仅加入了逻辑链推理过程。
更改Ollama下载模型的报错地址,在环境变量中添加“OLLAMA_MODELS”,填写自建的模型文件夹地址,使用命令下载1.5b的模型:ollama run deepseek-r1:1.5b(运行大模型),下载完成后会有“success”出现,并可以直接在cmd中提问。
注:配置ollama的host,类似models的配置,在环境变量中添加,11434是默认接口,如对外提供服务可修改127.0.0.1为对应的IP地址,
也可使用测试ollama是否在运行:curl http://localhost:11434/api/version
使用页面调用大模型
可使用 Open WebUI 实现,是可扩展、功能丰富且用户友好的自托管Web用户界面,专为完全离线操作设计,支持多种大型语言模型(LLM)运行程序,包括Ollama和OpenAI兼容的API。
Open WebUI的主要特性包括:
- 直观的界面:界面来自于ChatGPT(使用体验和ChatGPT一致)。
- 响应式设计:支持流式文字传输(和微信聊天一样),提升互动体验。
- 代码语法高亮:通过语法高亮功能享受增强的代码可读性(支持代码自动识别、嵌入代码块方便阅读复制)。
- 全面支持Markdown和LaTeX:通过丰富的Markdown和LaTeX功能提升LLM体验(提升阅读体验)。
- 本地RAG集成:通过检索增强生成模型(RAG)支持,方便搭建本地知识库。
- 网络浏览能力:集成网络搜索引擎,随时将大模型接入网络检索。
- 提示预设支持:使用聊天输入中的/命令即时访问预设提示,加速互动。
- 对话标记:支持分类和定位特定聊天,以便快速参考和简化数据收集。
- 多模型支持:无缝切换不同的聊天模型,根据需求进行多样化的互动。
文档地址:🏡 Home | Open WebUI
注意:安装该页面需要python版本为3.11(Python Release Python 3.11.0 | Python.org)
使用命令安装:pip install open-webui
安装完成后运行命令:open-webui serve(cmd中执行)
使用浏览器访问:127.0.0.1:8080,创建管理员账号,之后会自动挂载之前下载的大模型(此时要在另一个cmd中启动ollama中对应的大模型)
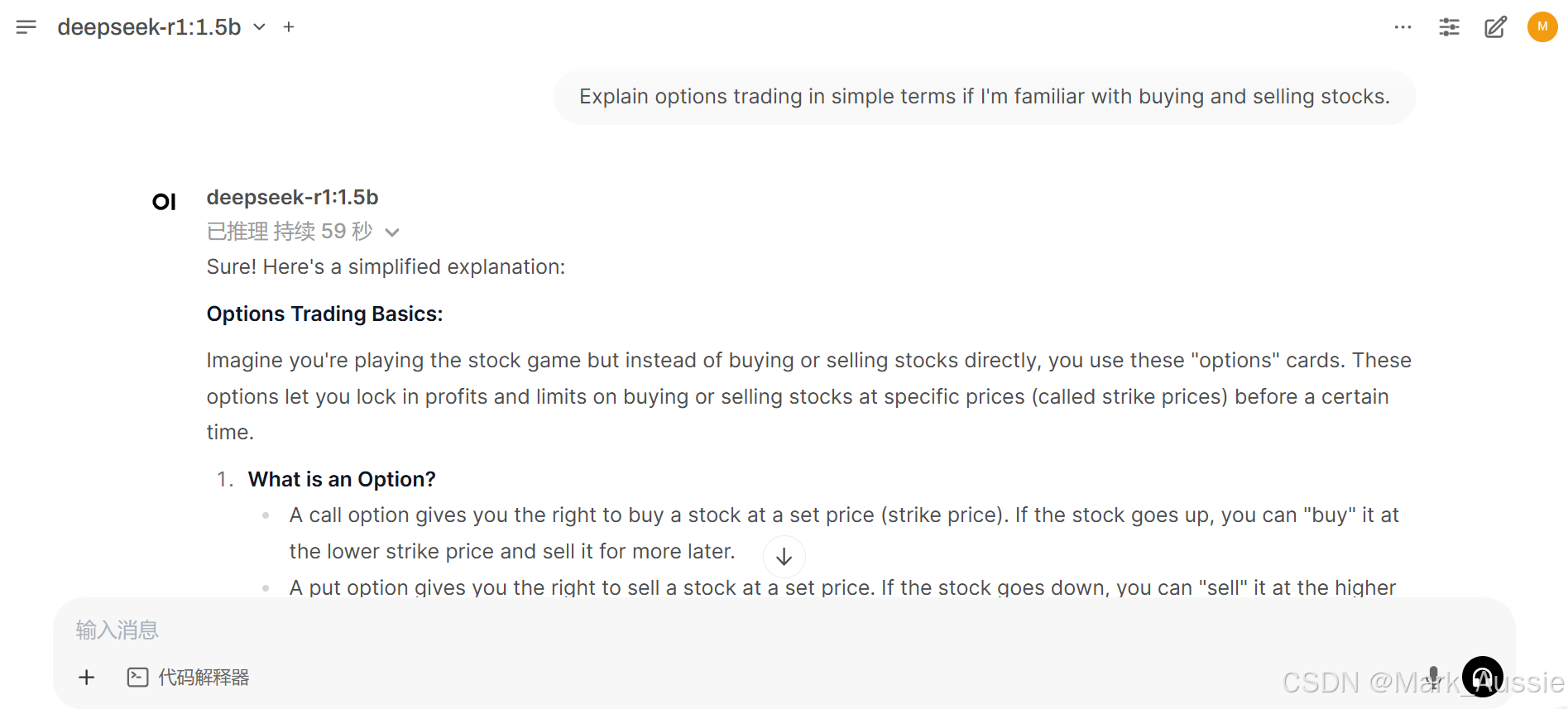
使用chatbox和cherrystudio界面
下载地址:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
Tips
1. DSR1-1.5b 逻辑较差,自动调度逻辑链的机制不明确,可使用(深度思考)前缀强制调用逻辑链。
2. Open-webui 默认开启多轮对话,在右侧【高级参数设置】中可以调整输入至大模型的上下文长度,大模型会随着输入量、对话轮次的增多逐渐变慢,因此不建议进行过长的多轮对话,转而使用左上角的【新对话】创建新的聊天框来沟通。
3. 头像-》【管理员设置】,可以开启联网搜索功能,选择开源的【duckduckgo】搜索引擎,点击右下角保存,即可在聊天窗体内嵌入【联网搜索】功能(可能需要科学上网)。
4. ollama命令:基本上和docker命令一样,可以用ollama ps 查看正在运行的大模型(无调用5分钟左右ollama会自动释放资源),ollama list 查看挂载的大模型,同理cp复制、rm删除等。
API调用
启动ollama:ollama serve
调用大模型
import json
import requests
# API的URL
url = 'http://127.0.0.1:11434/api/chat'
input_text = "我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?"
# 要发送的数据
data = {
"model": "deepseek-r1:1.5b",
"messages": [
{"role": "system", "content": "你是一个数学家,你可以计算任何算式。"},
{"role": "user", "content": " "}
],
"stream": False
}
# 找到role为user的message
for message in data["messages"]:
if message["role"] == "user":
# 将输入文本添加到content的开头
message["content"] = input_text
# 将字典转换为JSON格式的字符串
json_data = json.dumps(data)
# 发送POST请求
response = requests.post(url, data=json_data, headers={'Content-Type': 'application/json'})
# 打印响应内容
print(response.text)
print(response.json())
print(response.json()["message"]["content"])
调用Embedding模型
以使用nomic-embed-text embedding模型为例:
拉取模型:ollama pull nomic-embed-text
命令行调用:curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text", "prompt": "The sky is blue because of Rayleigh scattering"}'
python调用:
import json
import numpy as np
import requests
# API的URL
url = 'http://127.0.0.1:11434/api/embeddings'
input_text = "我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?"
# 要发送的数据
data = {
"model": "nomic-embed-text",
"prompt": "The sky is blue because of Rayleigh scattering"
}
# 将字典转换为JSON格式的字符串
json_data = json.dumps(data)
# 发送POST请求
response = requests.post(url, data=json_data, headers={'Content-Type': 'application/json'})
# 打印响应内容
print(response.json())
embedding = response.json()["embedding"]
print(f"Prompt Embedding Length: {len(embedding)}; \nEmbedding: \n{np.array(embedding).reshape(len(embedding), -1)}")
参考:

















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









