







简介
在拿到数据之后,我们需要做数据整理。比如:
- 创建一些新变量。
- 重命名变量。
- 更改殊勋。
- 筛选数据。
- …
为了做到这个,我们可以用dplyr包来进行数据的转换。
dplyr已经整合进tidyverse了,所以加载tidyverse就行。
用到的数据集
为了进行演示,我们用到nycflights13库中flights数据集。
这个数据集
library(nycflights13)
library(tidyverse)
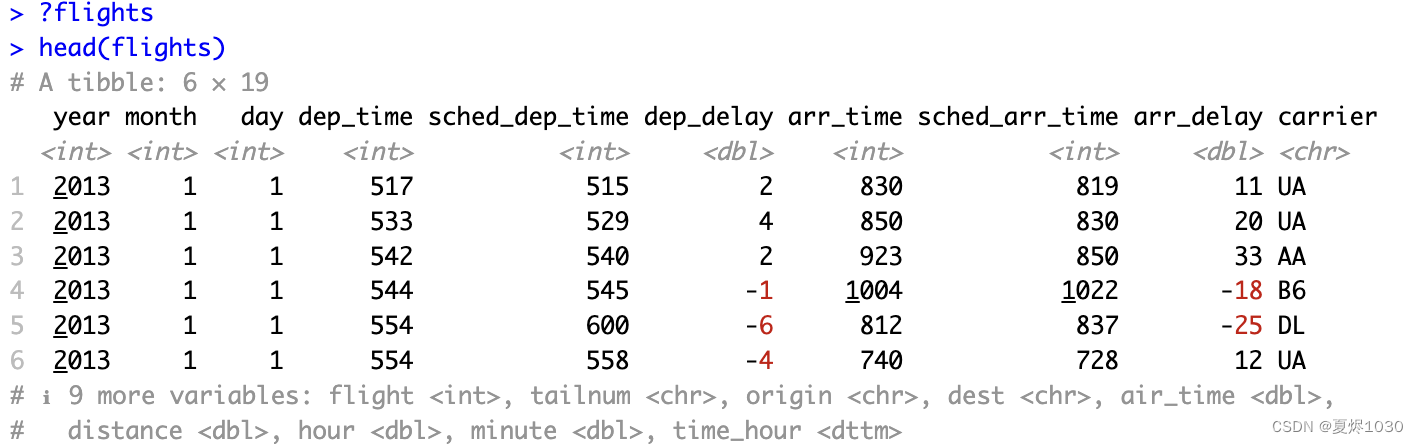
# 了解flights的内容
?flights
常用操作
通过值筛选数据(filter())
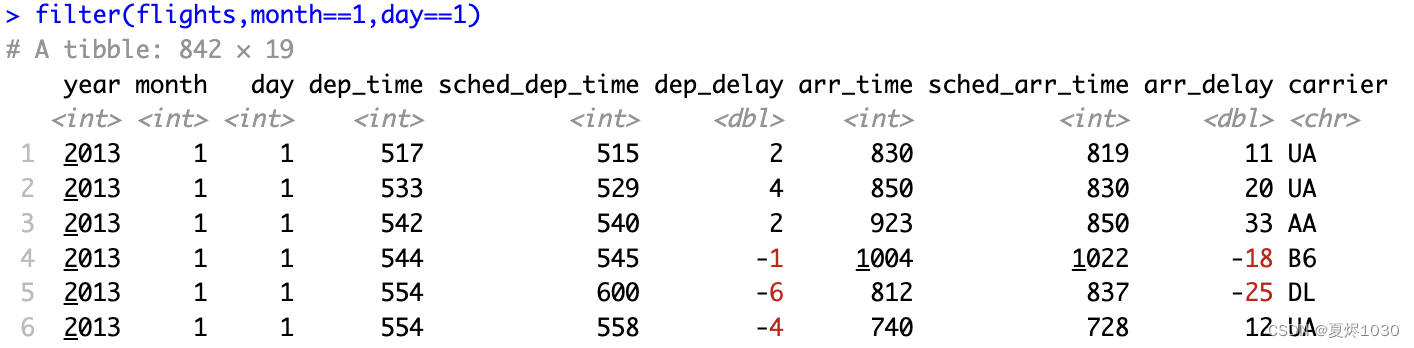
任务1:筛选1月1日的航班
filter(flights,month==1,day==1)
任务2:筛选11月和12月的航班
方法1:
filter(flights,month==11 | month==12)
方法2:
filter(flights, month %in% c(11,12))

任务3:筛选到达延迟超过两小时的航班
filter(flights,arr_delay >= 120)
任务4:筛选凌晨到8点的航班
filter(flights,dep_time>=000 & dep_time <=800)
还有一种写法是用到between函数,between返回一个区间范围。
filter(flights, between(dep_time,000,800))

任务5:筛选没有出发时间的航班
filter(flights,is.na(dep_time))

重新排序数据(arrange())
注意:缺失值总是排在最后
任务1:按照时间排序(默认升序)
arrange(flights,year,month,day)

任务2:按降序排列到达时间
arrange(flights,desc(arr_time))

通过名字选择变量(select())
有些数据集有很多变量,这代表着有很多列。可以通过select来选择某些列。
select(flights,year,month,day,arr_time)
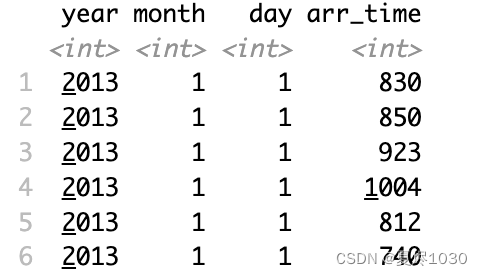
通过已经存在的变量创建新变量(mutate())
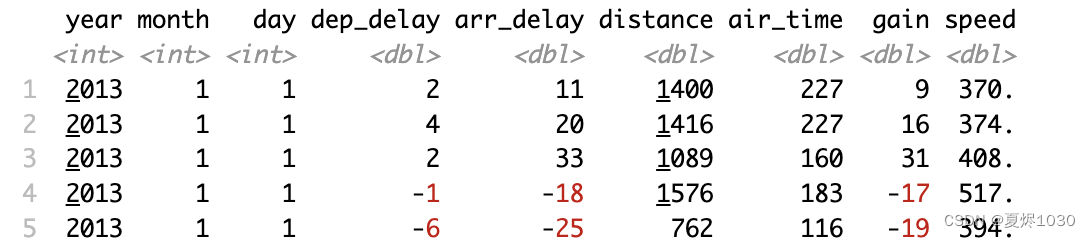
mutate会在数据集的最后增加新列,所以要创建一个新的数据集来借助。
flights_new <- select(flights, year:day,ends_with("delay"),distance,air_time)
mutate(flights_new,gain=arr_delay-dep_delay,speed=distance/air_time*60)
如果只想要新创建的数据,把mutate换成transmute。
其他函数也都可以放在mutate中,但是必须是向量。
总结数据(summarize())
summarize(flights,delay=mean(dep_delay,na.rm=TRUE))

summarize配合group_by()
我们一步步来看:
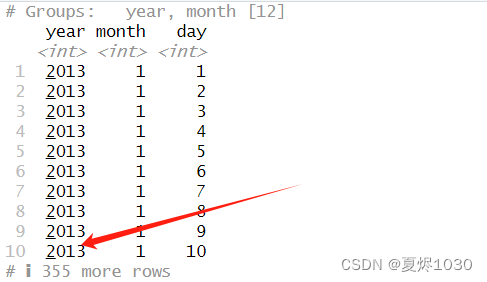
第一步:
flightsPerDay <- group_by(flights, year,month,day)
(summarize(flightsPerDay))
第一行代码,就是对flights数据集进行分组,按照year,month,day三个变量分组。
这代表着,相同一天的数据被分到了一起。一年365天,所以,当我们进行summarize的时候,我们看到有365个数据。
第二步:统计数量
(summarize(flightsPerDay,count=n()))
在原本的基础上加上一个count变量
结果如下:
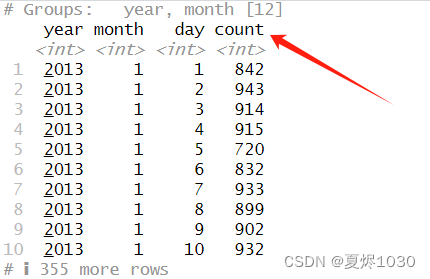
新加了一个统计,也就是每一天的有多少飞机在机场离开。
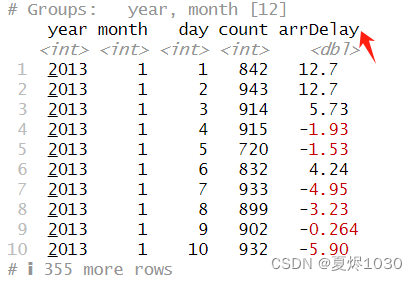
第三步:统计平均晚到时间
(summarize(flightsPerDay,count=n(),arrDelay=mean(arr_delay,na.rm=TRUE)))
na.rm=TRUE一定要加,否则但凡有一个NA,所有数据都会被计算成NA。
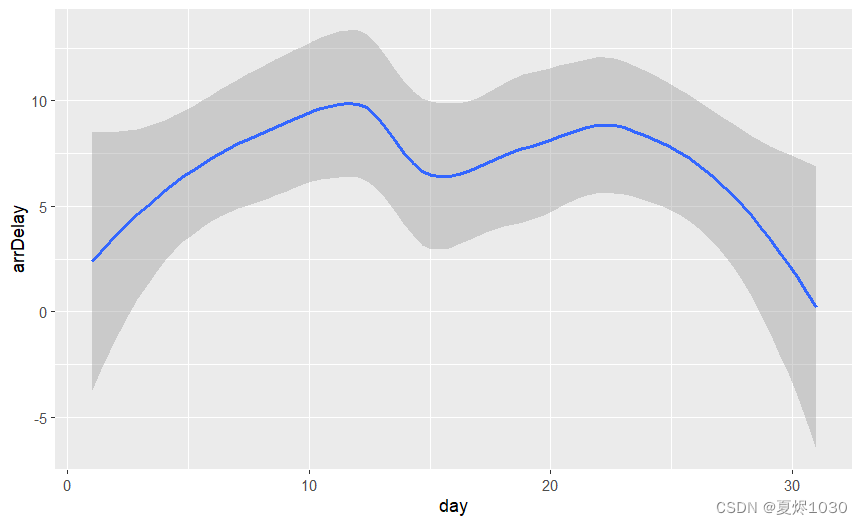
第四步:用ggplot作图
这一步不清楚的,参照前面的文章。
DayDelay <- summarize(flightsPerDay,count=n(),arrDelay=mean(arr_delay,na.rm=TRUE))
# 把统计结果交给一个新的数据集
ggplot(DayDelay)+geom_smooth(mapping=aes(x=day,y=arrDelay))
# 用ggplot画拟合曲线
下面就是每个月的哪一天,飞机晚点的一个大体走势。















 6570
6570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









