







 本文介绍了一种新的多模态训练方法LLaVA-RLHF,通过调整RLHF以解决大型多模态模型中的幻觉问题。通过人类反馈强化学习,结合事实增强,模型在LLaVA-Bench和MMHAL-BENCH上取得显著性能提升,为多模态模型对齐提供了一种高效且有效的解决方案。
本文介绍了一种新的多模态训练方法LLaVA-RLHF,通过调整RLHF以解决大型多模态模型中的幻觉问题。通过人类反馈强化学习,结合事实增强,模型在LLaVA-Bench和MMHAL-BENCH上取得显著性能提升,为多模态模型对齐提供了一种高效且有效的解决方案。
Abstract
大型多模态模型(LMM)是跨模态构建的,两种模态之间的不一致可能会导致“幻觉”,生成不以上下文中的多模态信息为基础的文本输出。为了解决多模态错位问题,我们将人类反馈的强化学习(RLHF)从文本领域调整到视觉语言对齐的任务,其中要求人类注释者比较两个响应并找出更幻觉的一个,以及视觉语言对齐的任务。 -训练语言模型以最大化模拟人类奖励。我们提出了一种名为 Factually Augmented RLHF 的新对齐算法,该算法通过附加事实信息(例如图像标题和真实多选选项)来增强奖励模型,从而减轻 RLHF 中的奖励黑客现象并进一步提高性能。我们还使用之前可用的人工编写的图像文本对增强了 GPT-4 生成的训练数据(用于视觉指令调整),以提高模型的一般功能。为了在现实场景中评估所提出的方法,我们开发了一个新的评估基准 MMHAL-BENCH,特别关注惩罚幻觉。作为第一个使用 RLHF 训练的 LMM,我们的方法在 LLaVA-Bench 数据集上取得了显着的改进,达到了纯文本 GPT-4 94% 的性能水平(而之前的最佳方法只能达到 87% 的水平),并且改进了MMHAL-BENCH 上的性能比其他基线高 60%。我们在 https://llava-rlhf.github.io 开源我们的代码、模型和数据。
1 简介
大型语言模型(LLM;Brown 等人(2020);Chowdhery 等(2022);OpenAI(2023))可以通过图像-文本对的进一步预训练来深入研究多模态领域(Alayrac 等人; Awadalla 等人,2023)或通过专门的视觉指令调整数据集对其进行微调(Liu 等人,2023a;Zhu 等人,2023),导致强大的大型多模态模型(LMM)的出现。然而,开发 LMM 面临挑战,特别是多模式数据与纯文本数据集的数量和质量之间的差距。考虑 LLaVA 模型 (Liu et al., 2023a),它是从预训练的视觉编码器 (Radford et al., 2021) 和指令调整的语言模型 (Chiang et al., 2023) 初始化的。它只接受了 15 万个基于合成图像的对话的训练,与使用跨越 1800 个任务的超过 1 亿个示例的纯文本模型 (Flan (Longpre et al., 2023)) 相比要少得多。数据的这种限制可能会导致不一致因此,LMM 可能会产生幻觉输出,这些输出无法准确地锚定到图像提供的上下文。
为了缓解 LMM 训练中缺乏高质量视觉指令调整数据所带来的挑战,我们引入了 LLaVA-RLHF,这是一种经过训练以改进多模态对齐的视觉语言模型。我们的关键贡献之一是改编了人类反馈强化学习(RLHF)(Stiennon et al., 2020; Ouyang et al., 2022; Bai et al., 2022a),这是一种通用且可扩展的对齐范式,显示出良好的效果基于文本的 AI 代理的成功,以及 LMM 的多模式对齐。通过收集人类偏好,重点是检测幻觉1,并在强化学习中利用这些偏好来进行 LMM 微调(Ziegler 等人,2019;Stiennon 等人,2020)。这种方法可以以相对较低的注释成本改善多模态对齐,例如,花费 3000 美元收集 10K 个人类对基于图像的对话的偏好。据我们所知,这种方法是 RLHF 首次成功适应多模态对齐。
当前 RLHF 范式的一个潜在问题称为奖励黑客,这意味着从奖励模型中获得高分并不一定会导致人类判断力的提高。为了防止奖励黑客行为,之前的工作(Bai et al., 2022a; Touvron et al., 2023b)提出迭代收集“新鲜”人类反馈,这往往成本高昂,并且无法有效利用现有的人类偏好数据。在这项工作中,我们提出了一种数据效率更高的替代方案,即我们尝试使奖励模型能够利用更大语言模型中现有的人工注释数据和知识。首先,我们通过使用具有更高分辨率和更大语言模型的更好视觉编码器来提高奖励模型的一般能力。其次,我们引入了一种名为事实增强 RLHF (Fact-RLHF) 的新颖算法,该算法通过使用图像标题或真实多选选项等附加信息来增强奖励信号,从而校准奖励信号,如图 1 所示。
 表 1:说明 RLHF 对大型多模态模型影响的定性示例。 LLaVARLHF 被认为更有帮助(上)并且更少产生幻觉(下)。
表 1:说明 RLHF 对大型多模态模型影响的定性示例。 LLaVARLHF 被认为更有帮助(上)并且更少产生幻觉(下)。
为了提高 LMM 在监督微调 (SFT) 阶段的一般能力,我们利用对话格式中现有的高质量人工注释多模态数据进一步增强了合成视觉指令调整数据 (Liu et al., 2023a)。具体来说,我们将 VQA-v2 (Goyal et al., 2017a) 和 A-OKVQA (Schwenk et al., 2022) 转换为多轮 QA 任务,并将 Flickr30k (Young et al., 2014b) 转换为 Spotting Captioning 任务(Chen 等人,2023a),并基于新的数据混合训练 LLaVA-SFT+ 模型。
最后,我们研究评估现实世界生成场景中 LMM 的多模态对齐,特别强调惩罚任何幻觉。我们创建了一组不同的基准问题,涵盖 COCO 中的 12 个主要对象类别(Lin 等人,2014),并包括 8 种不同的任务类型,最终形成了 MMHAL-BENCH。我们的评估表明,该基准数据集与人类评估非常吻合,特别是在针对抗幻觉调整分数时。在我们的实验评估中,作为第一个使用 RLHF 训练的 LMM,LLaVA-RLHF 取得了令人印象深刻的结果。我们观察到 LLaVA-Bench 显着增强,达到 94%,MMHAL-BENCH 提高 60%,并为 LLaVA 建立了新的性能基准,在 MMBench 上得分为 52.4%(Liu et al., 2023b),在 MMHAL-BENCH 上得分为 82.7% POPE 上的 F1(Li 等人,2023d)。我们已在 https://llava-rlhf.github.io 上公开提供我们的代码、模型和数据。
2 方法
2.1 多模态 RLHF
来自人类反馈的强化学习(RLHF)(Ziegler et al., 2019; Stiennon et al., 2020; Ouyang et al., 2022; Bai et al., 2022a)已经成为一种强大且可扩展的对齐大型语言模型的策略(法学硕士)与人类价值观。在这项工作中,我们使用 RLHF 来对齐 LMM。我们的多模态 RLHF 的基本流程可以概括为三个阶段:
多模态监督微调视觉编码器和预训练的 LLM 使用令牌级监督在指令跟踪演示数据集上联合微调,以生成监督微调 (SFT) 模型 πSFT。
多模态偏好建模在此阶段,奖励模型(也称为偏好模型)经过训练,可以为“更好”的响应提供更高的分数。成对比较训练数据通常由人类注释者注释。形式上,让聚合的偏好数据表示为 DRM = {(I, x, y0, y1, i)},其中 I 表示图像,x 表示提示,y0 和 y1 是两个关联的响应,i 表示索引的首选响应。奖励模型采用交叉熵损失函数:
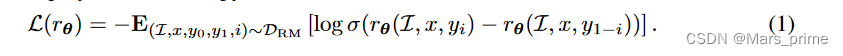
强化学习这里,通过多模态监督微调(SFT)(Ouyang et al., 2022; Touvron et al., 2023b)初始化的策略模型经过训练,通过最大化所提供的奖励信号来为每个用户查询生成适当的响应通过奖励模型。为了解决潜在的过度优化挑战,特别是奖励黑客攻击,有时会应用从初始策略模型(Ouyang et al., 2022)派生的每个代币 KL 惩罚。形式上,给定一组收集的图像和用户提示,DRL = {(I, x)},以及固定的初始策略模型 πINIT 和 RL 优化模型 πRL φ ,完整的优化损失表示为
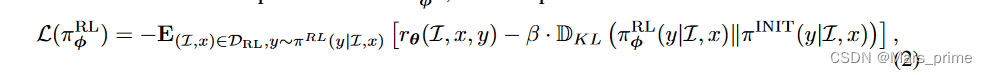
其中β是控制KL惩罚规模的超参数。
2.2 通过高质量指令调优增强 LLAVA
最近的研究(Zhou 等人,2023;Touvron 等人,2023b)表明,高质量的指令调优数据对于调整大型语言模型 (LLM) 至关重要。我们发现这对于 LMM 来说变得更加重要。由于这些模型跨越广阔的文本和视觉领域,清晰的调整指令至关重要。正确对齐的数据可确保模型产生上下文相关的输出,有效地弥合语言和视觉差距。
例如,LLaVA 使用纯文本 GPT-4 合成了 150k 视觉指令数据,其中图像表示为边界框上的关联标题以提示 GPT-4。尽管已应用仔细的过滤来提高质量,但管道偶尔会生成视觉上未对齐的指令数据,这些数据无法使用自动过滤脚本轻松删除,如表 1 中突出显示的那样。
在这项工作中,我们考虑使用从现有人类注释中导出的高质量指令调整数据来增强 LLaVA(在进行了 60k 次对话进行偏好建模和 RL 训练之后,98k 次对话)。具体来说,我们策划了三类视觉指导数据:来自 VQA-v2 (83k) 的“是”或“否”查询(Goyal 等人,2017b)、来自 A-OKVQA (16k) 的多项选择题(Marino 等人) ., 2019),以及来自 Flickr30k (23k) 的接地字幕(Young 等人,2014a)。我们的分析表明,数据集的合并显着提高了 LMM 在基准测试中的能力。令人印象深刻的是,这些结果超过了在比我们大一个数量级的数据集上训练的模型(Dai 等人,2023;Li 等人,2023a;Laurenc ̧on 等人,2023),如表 7 和表 4 所示。每个数据集影响的全面细分,请参阅第 3.5 节。
2.3 具有幻觉意识的人类偏好集合
受最近分别收集有用性和无害性偏好的 RLHF 研究的启发(Bai 等人,2022b;Touvron 等人,2023b),在本研究中,我们决定区分那些仅仅不太有帮助的反应和那些与图像(通常以多模态幻觉为特征)。为了实现这一目标,我们为众包工作者提供了表 2 所示的模板,以指导他们在比较两个给定响应时进行注释。通过我们当前的模板设计,我们的目标是促使众包工作者识别模型响应中潜在的幻觉。
尽管如此,我们的培训过程集成了一个单一的奖励模型,强调多模式协调和整体帮助2。我们通过使用我们的 SFT 模型和 0.7 的温度对最后一个响应进行重新采样,收集人类对 10k 保留 LLaVA 数据的偏好。奖励模型由SFT模型初始化,以获得基本的多模态能力。
2.4 事实上增强的 RLHF (FACT-RLHF)
我们对 50k 保留 LLaVA 对话进行多模态 RLHF,另外还有来自 A-OKVQA 的 12k 多项选择问题和从 VQA-v2 二次抽样的 10k 是/否问题。由于担心 LLaVA 的合成多轮对话数据中存在幻觉,我们仅使用每个对话中的第一个问题进行 RL 训练,这避免了对话上下文中预先存在的幻觉。
RLHF 中的奖励黑客在初步的多模态 RLHF 实验中,我们观察到,由于 SFT 模型中固有的多模态错位,奖励模型很弱,有时无法有效检测 RL 模型响应中的幻觉。在文本领域,之前的工作(Bai 等人,2022a;Touvron 等人,2023b)提出迭代收集“新鲜”人类反馈。然而,这可能成本相当高,并且无法有效利用现有的人工注释数据,并且不能保证更多的偏好数据可以显着提高奖励模型对多模态问题的判别能力。
为了增强奖励模型的能力,我们提出了事实增强 RLHF(Fact-RLHF),其中奖励模型可以访问额外的真实信息(例如图像标题)来校准其判断。在原始的 RLHF 中(Stiennon et al., 2020; OpenAI, 2022),奖励模型只需要根据用户查询(即输入图像和提示)来判断响应的质量:

在 Factually Augmented RLHF (Fact-RLHF) 中,奖励模型具有有关图像文本描述的附加信息:

当策略模型产生一些显然与图像说明不符的幻觉时,这可以防止奖励模型被策略模型攻击。对于 COCO 图像的一般问题,我们连接五个 COCO 标题作为附加事实信息,而对于 A-OKVQA 问题,我们使用带注释的理性作为事实信息。
事实上增强奖励模型是在与普通奖励模型相同的二元偏好数据上进行训练的,只不过事实信息是在模型微调和推理过程中提供的。
象征性奖励:正确性惩罚和长度惩罚在我们的一些 RL 数据中,某些问题带有预定的真实答案。这包括 VQA-v2 中的二元选择(例如“是/否”)和 A-OKVQA 中的多项选择选项(例如“ABCD”)。这些注释也可以被视为额外的事实信息。因此,在 Fact-RLHF 算法中,我们进一步引入了一种符号奖励机制,用于惩罚偏离这些真实选项的选择。
此外,我们观察到 RLHF 训练的模型通常会产生更详细的输出,Dubois 等人也注意到了这一现象。 (2023)。虽然这些冗长的输出可能会受到用户或基于 LLM 的自动化评估系统的青睐(Sun 等人,2023b;Zheng 等人,2023),但它们往往会给 LMM 带来更多的幻觉。在这项工作中,我们遵循 Sun 等人的做法。 (2023a) 并纳入以令牌数量衡量的响应长度作为辅助惩罚因素。
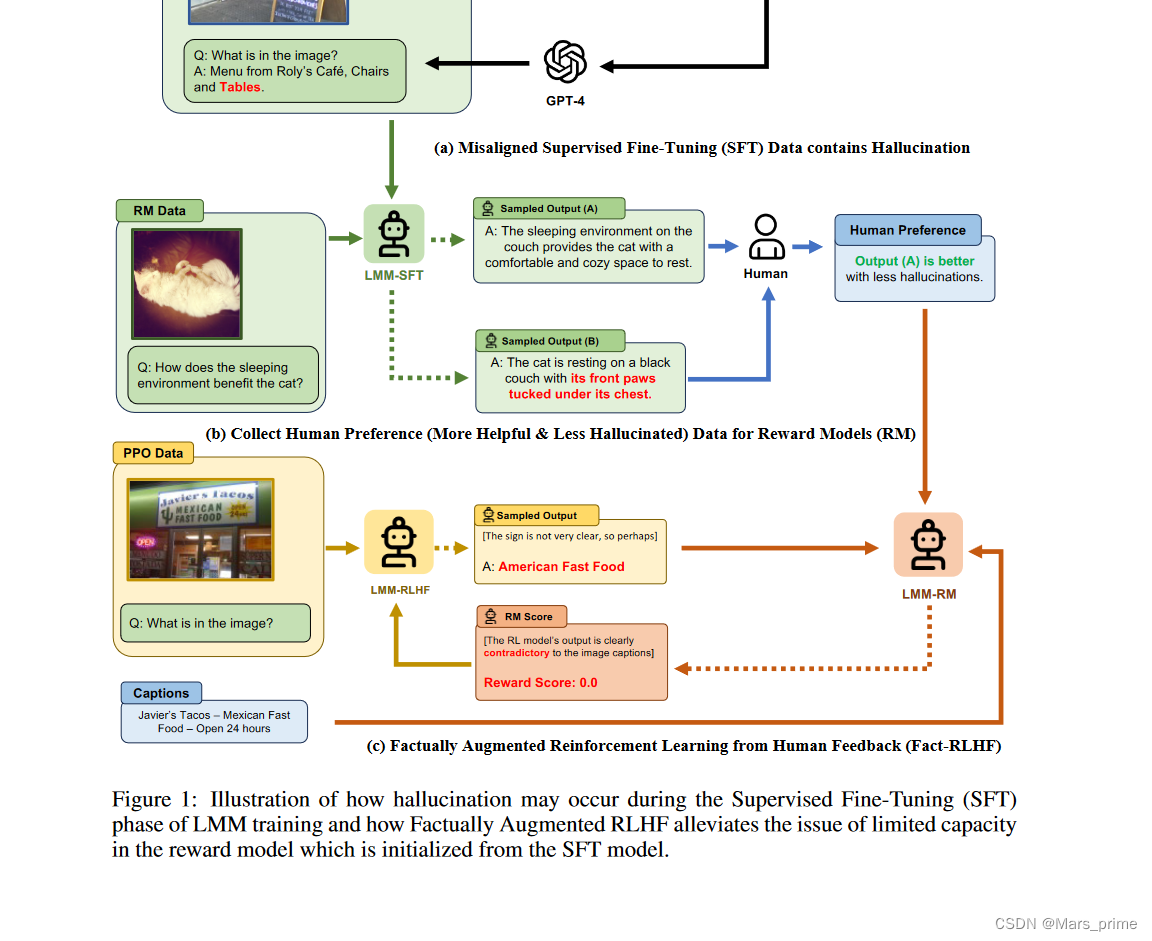
图 1:说明在 LMM 训练的监督微调 (SFT) 阶段如何可能出现幻觉,以及事实增强 RLHF 如何缓解从 SFT 模型初始化的奖励模型中容量有限的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









