







💥💥💞💞欢迎来到Matlab仿真科研站博客之家💞💞💥💥
✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
🍎个人主页:Matlab仿真科研站博客之家
🏆代码获取方式:
💥扫描文章底部QQ二维码💥
⛳️座右铭:行百里者,半于九十;路漫漫其修远兮,吾将上下而求索。

⛄更多Matlab优化求解仿真内容点击👇
Matlab优化求解(仿真科研站版)
⛄ 一、 遗传算法简介
1 引言
公交排班问题是城市公交调度的核心内容,是公交调度人员、司乘人员进行工作以及公交车辆正常运行的基本依据。行车时刻表是按照线路的当前客流量情况,确定发车频率,提供线路车辆的首、末车时间。它是公交企业对社会的承诺,决定着为乘客服务的水平,发车间隔越小,服务水平越高,但是公交企业投入的成本越高。行车时刻表的编制应是在满足客流需求的前提下,尽量减少不必要的投入,这是个多目标优化问题。目前,遗传算法是解决公交排班问题的有效方法之一。但在引入遗传算法的时候,普遍存在几个问题:①遗传算法过于简单,导致结果不准确,计算效率低;②模型太复杂不利于求解;③以一个统计时间段(如1小时)为模型的基本对象,得出该时间段内的均匀发车间隔,这忽略了整个时间段内的数据变化。基于以上的考虑,提出了综合改进的遗传算法应用于智能公交排班,模型同时考虑了乘客和公交公司的双重利益,最大和最小发车间隔、两个相邻的发车间隔之差以及满载率等约束条件,得出非均匀的发车时刻表,利用综合改进的遗传算法提高计算效率。
2 公交排班问题描述及数学模型的建立
公交排班的目的是确定最优或者近似最优的运营车辆的发车时刻表。公交车队按照该时刻表发车能够达到最高的运营效率和服务水平。本项目选用厦门市公交总公司思明分公交的30路运营车队作为排班对象,不失一般性,只考虑上行线路,即要优化30路车始发站的发车时刻表。线路上行方向有26个站,首班车发车时间为早上6点整,末班车发车时间为22:05分,所有运营车都在整分钟时刻发车,以距离首发时刻的时间间隔为发车时刻,选择发车时刻为决策变量,单位为分钟,在这里定义首发时刻为0分钟发车即对应早上6点发车。 一天之内的总班次为m,总时间为965分钟,最后一辆车的发车时间为第965分钟发车对应晚上22:05分发车。
由于受到数目众多的排班规则的影响,以及要达到多项指标的均衡,公交车辆排班问题变得极其复杂,在这里建立数学模型,把实际的问题抽象为数学问题。
为了更好的进行排班算法的研究,有必要对公交排班问题进行简化和假设:
1)各公交车为同一车辆类型;
2)公交车按调度时间表准时进站和出站,车速恒定,保持匀速行驶,途中没有堵车和意外事故;
3)各时段以内乘客到站服从均匀分布;
4)以分钟作为最小的时间单位;
5)实行统一票价。
2.1 建立目标函数
本文以乘客的等车时间成本最小和公交公司的运营收益最大为目标建立模型。
1)一天内乘客总的等车时间成本
总的等车时间WT’ij为:
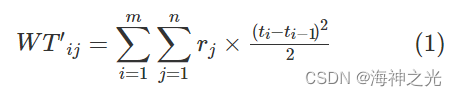
总的等车时间成本
调查的厦门市目前平均工资水平为32343元/年.人,按照双休日休息及法定的放假时间,现在一年大概有115天的休息时间,即有250天在工作,平均每天按工作8小时计算。
平均每分钟的工资为:
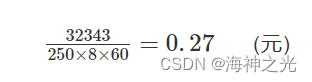
则总的等车时间成本为:
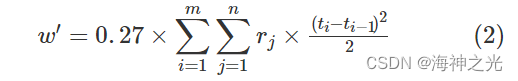
式(1)- (2)中,m表示在整个调度周期内发车车次总数;n表示线路的车站总数;t表示在整个调度周期内的连续时间;ti表示第i车次的始发站发车时间(min)(i=1,2,…,m);rj表示第j站在调度周期内随时间变化的乘客到达率(j=1,2,…,n); WT’ij表示所有乘客总的等车时间(min);w’表示总的等车时间成本(元)。
2)公交公司的运营收益
公交公司的运营收益为整个收入减去整个运营成本。
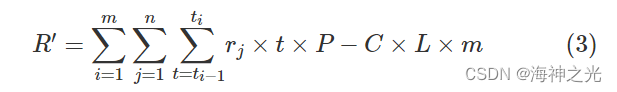
分别给乘客等车时间成本和公交公司的运营收益以不同的权系数,把以上两个目标函数转化为单目标函数,使得公交优化排班问题成为一个单目标优化问题。合并后的目标函数为:
Minz=α×w′-β×R′ (4)
即
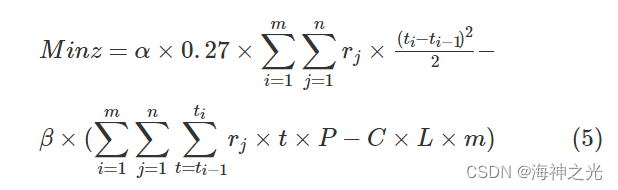
式(3)-(5)中,R’为运营收益;C为车辆运营的单位可变成本(元/车.公里);L为线路总的长度(公里);P表示统一的票价(元/人.次);α表示乘客等车时间成本权系数;β表示公交公司运营收益权系数。
2.2 模型约束条件
1)平均满载率的约束

其中:Q车容量表示车辆满载时的容量(人/车);θ表示每车平均期望满载率(0<θ<100%)。
2)最大最小发车时间间隔约束
任意相邻两车之间的发车间隔要满足最大最小发车时间间隔约束,即:
Tmin≤ti-ti-1≤Tmax (i=2,3,…,m) (7)
其中:Tmax表示相邻两车之间的最大发车间隔(min);Tmin表示相邻两车之间的最小发车间隔(min)。
3)两个相邻的发车间隔之差的约束
为保证发车时刻的连续性,任意两个相邻的发车间隔之差不宜太大,即
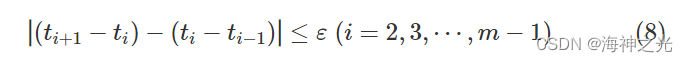
其中:ε表示两相邻发车间隔之差的限值。
2.3 发车时刻模型
综合以上的模型的目标函数和约束条件,最终得出公交发车时刻模型如下:
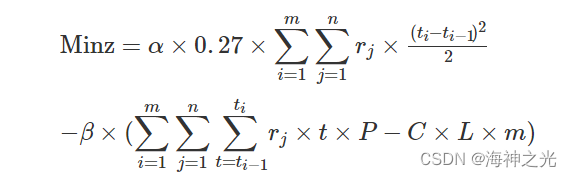
其中:
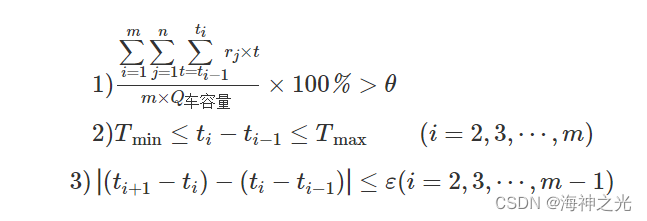
3公交排班问题的遗传算法设计
整个遗传算法的基本流程图如图1,根据公交排班的特点,对遗传算法进行了一定的改进,按如下方法进行遗传算法设计。

图1 遗传算法的基本流程图
3.1 决策变量的真实值
结合公交排班的特点,采用真实值编码方法。在这种编码方法中,个体染色体的各个基因座上的值就是决策变量的真实值。与X=[x1,x2,…,xm]T相对应的染色体X即表示为码串[x1,x2,…,xm]。采用真实值编码后,每个编码位置(基因座)的值就表示该时刻距离首发时刻的时间,单位为分钟,在这里定义首发时间为0分钟。如长度为m的编码串:(0, 3, 6,…, 965), 0表示首发时间,3表示第二趟车距首发3分钟发车,6表示第二趟车距首发6分钟发车,…,965表示第m趟车距首发965分钟发车。
针对解决公交排班问题,采用真实值编码作为染色体的基因有以下优点[6][7]:①适合于表示范围较大的数和较大空间的遗传搜索;②改善计算的复杂性,减少了编码和解码过程,提高运算效率;③便于处理复杂的决策变量约束条件。真实值编码的基因,如果一个个体中性状优良的基因片断被遗传到下一代,那么该片断在新个体中仍然是优良的。可见这种编码性质保证了遗传算法充分发挥其代代进化的特点。而用其他编码方法,一个好的基因片断复制到下一代就不一定还是好的。
3.2 约束条件的处理
数学上处理约束最优化问题时,有一类算法是通过把约束问题转换成序列化的无约束问题来进行求解。其中比较著名的有罚函数法,也称二次惩罚法[8]。作为一种有约束非线性最优化方法,其基本思想是通过建立一个新的函数把约束问题化为一系列无约束问题来处理,根据选择的惩罚项的函数形式不同又分为内点法和外点法。内点法的特点就是首先在可行域内求得一个可行的初始点,在求解过程中探索点必须保持在可行域内部。本文中运行内点法建立惩罚项。最终得到的目标函数为:
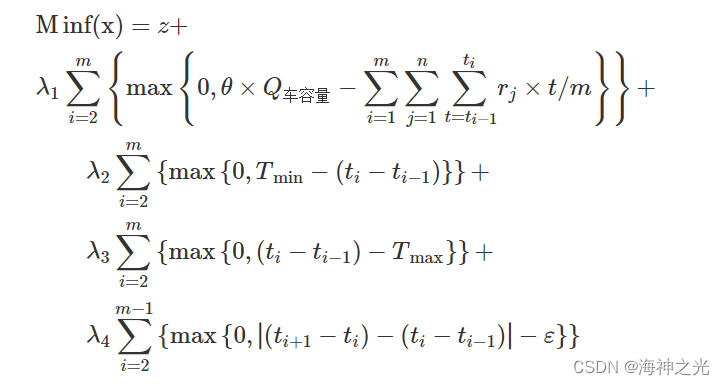
其中,z为原目标函数,f(x)是利用惩罚函数后的目标函数值,λ1、λ2、λ3、λ4>0,分别为惩罚函数作用于约束条件的系数(即惩罚系数)
3.3 适应度函数
适应度函数的设定在整个遗传算法的操作过程中占了很重要的地位。根据建立起来的目标函数来设定适应度函数。公交排班模型的目标函数是最小化问题,为了保证染色体的适应度取值为非负数,采用如下适应度函数:
F(X)=Cmax-f(X)
其中f(X)为个体的目标函数,Cmax为同一代群体中所有目标函数的最大值。
3.4 初始群体
针对公交排班的特点,采用结合先验知识产生初始群体的方法。由于乘客在时间上的分布很大程序上左右了排班的优化过程,而乘客的分布在一天内又很不均匀,一天内有几个高峰期,高峰期单位时间内到达各个车站的乘客数量会增多,这时的发车间隔应该缩短,而其他非高峰期的发车间隔应该增长。所以完全靠随机产生初始群体不能满足实际问题的需要,故应该对初始群体进行编码调整,其计算公式如下:
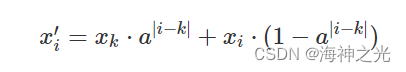
其中x′i是基因xi经过调整后的值,易知基因xk为收缩中心,a为(0,1)内的数,称为收缩系数。
3.5 遗传算子
3.5.1 选择算子
采用进行了修改的比较选择方法和最优保留策略。方法如下:
先比较群体P(t)中的各个个体,找出P(t)中所有不同的个体,组成中间群体,选择过程对中间群体进行选择同样选择M次可以产生新一代群体P(t+ 1)。该方法主要是作用于在遗传算法搜索的后期阶段,群体中可能有很多个体都是相同的这种情况。这时,用改进方法,新出现的优秀个体将以更大的概率复制到下一代。在公交排班的遗传算法中采用最优保存策略,该策略可保证最优个体不被交又、变异等遗传运算所破坏,直接进入下一代。可见改进的方法具有更强的局部搜索能力。
3.5.2 交叉算子
选择单点交叉[9]作为遗传算法的交叉运算,其基本过程如下: 对于按照交叉概率PC从种群中选出的某条染色体,随机地在染色体上选择一个断点,交换双亲上断点的右端,生成新的后代。
3.5.3 变异算子
采用均匀变异操作。其基本过程如下:依次指定染色体当中的基因座为变异点,对每个变异点以很小的变异概率从对应基因的取值范围内取一个均匀分布的随机数来代替原来的基因。由于求的是非均匀发车时刻,且以每一时刻作为染色体的基因,故染色体中任一基因xk的取值范围是(xk-1,xk+1),则变异后的新基因值x′k为:
x′k=xk-1+r×(xk+1-xk-1)
式中,r为(0,1 )内均匀分布的一个随机数。
⛄ 二、部分源代码
clear;clc;close all;
%% 生成随机OD矩阵
%od()
%%遗传参数设置
NUMPOP=200;%初始种群大小
irange_l=1; %问题解区间
irange_r=30;
LENGTH=20; %二进制编码长度
ITERATION = 10000;%迭代次数
CROSSOVERRATE = 0.8;%杂交率
SELECTRATE = 0.4;%选择率
VARIATIONRATE = 0.2;%变异率
OD = xlsread(‘OD.xlsx’);% 苏州地铁2号线调查问卷OD出行矩阵
h = xlsread(‘区间运行时间.xlsx’); % 苏州地铁2号线区间长度及运行时分
%初始化种群
pop=m_InitPop(NUMPOP,irange_l,irange_r);
pop_save=pop;
fitness_concat = [];
best_solution = [];
%开始迭代
for time=1:ITERATION
%计算初始种群的适应度
fitness=m_Fitness(pop, OD, h);
fitness_concat = [fitness_concat;max(fitness)];
pop_T = pop’;
[m,index] = max(m_Fitness(pop, OD, h));
best_solution = [best_solution;pop(:,index)'];
%选择
pop=m_Select(fitness,pop,SELECTRATE);
%编码
binpop=m_Coding(pop,LENGTH,irange_l);
%交叉
kidsPop = Crossover(binpop,NUMPOP,CROSSOVERRATE);
%变异
kidsPop = Variation(kidsPop,VARIATIONRATE);
%解码
kidsPop=m_Incoding(kidsPop,irange_l);
%更新种群
pop=[pop kidsPop];
for i=1:size(pop,1)
for j=1:size(pop,2)
if pop(i,j)<irange_l
pop(i,j)=irange_l;
end
if pop(i,j)>irange_r
pop(i,j)=irange_r;
end
end
end
end
disp([‘最优解:’ num2str(min(m_Fx(pop,OD))) ‘分钟’]);
disp([‘最优解对应的各参数:’ num2str(pop(1,1)) ‘,’ num2str(pop(2,1)) ‘,’ num2str(pop(3,1)) ‘,’ num2str(pop(4,1)) ]);
disp([‘最大适应度:’ num2str(max(m_Fitness(pop, OD, h)))]);
figure
% set(gca,‘looseInset’,[0 0 0 0]);
set(gcf,‘outerposition’,get(0,‘screensize’));
loglog(1:ITERATION, fitness_concat, ‘Blue*-’,‘linewidth’,2)
legend(‘{\bf最优适应度值}’);
xlabel(‘{\bf进化代数}’,‘fontsize’,30);
ylabel(‘{\bf最优适应度}’,‘fontsize’,30);
set(gca,‘FontSize’,20,‘Fontname’, ‘Times New Roman’);
set(get(gca,‘XLabel’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(get(gca,‘YLabel’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(get(gca,‘legend’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(get(gca,‘title’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(gca,‘linewidth’,2);
print(gcf,‘-dpng’,‘-r300’,‘最优适应度值-进化代数’);
figure
% set(gca,‘looseInset’,[0 0 0 0]);
set(gcf,‘outerposition’,get(0,‘screensize’));
semilogx(1 : ITERATION, best_solution,‘linewidth’,4)
legend(‘{\bf大小交路折返站a}’,‘{\bf大小交路折返站b}’,‘{\bf大交路发车频率f_1}’,‘{\bf小交路发车频率f_2}’);
% text(6, 0.3, ‘
←
y
=
2
−
x
\leftarrow y= 2^{-x}
←y=2−x’, ‘HorizontalAlignment’, ‘left’, ‘Interpreter’, ‘latex’, ‘FontSize’, 15);
xlabel(‘{\bf进化代数}’,‘fontsize’,15);
ylabel(‘{\bf参数各代最优值}’,‘fontsize’,15);
set(gca,‘FontSize’,20,‘Fontname’, ‘Times New Roman’);
set(get(gca,‘XLabel’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(get(gca,‘YLabel’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(get(gca,‘legend’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(get(gca,‘title’),‘Fontsize’,20,‘Fontname’, ‘宋体’);
set(gca,‘linewidth’,2);
print(gcf,‘-dpng’,‘-r300’,‘参数各代最优值-进化代数’);
⛄ 三、运行结果




⛄ 四、 matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]王庆荣,朱昌盛,梁剑波,冯文熠.基于遗传算法的公交智能排班系统应用研究[J].计算机仿真. 2011,28(03)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
🍅 仿真咨询
1 各类智能优化算法改进及应用
1.1 PID优化
1.2 VMD优化
1.3 配电网重构
1.4 三维装箱
1.5 微电网优化
1.6 优化布局
1.7 优化参数
1.8 优化成本
1.9 优化充电
1.10 优化调度
1.11 优化电价
1.12 优化发车
1.13 优化分配
1.14 优化覆盖
1.15 优化控制
1.16 优化库存
1.17 优化路由
1.18 优化设计
1.19 优化位置
1.20 优化吸波
1.21 优化选址
1.22 优化运行
1.23 优化指派
1.24 优化组合
1.25 车间调度
1.26 生产调度
1.27 经济调度
1.28 装配线调度
1.29 水库调度
1.30 货位优化
1.31 公交排班优化
1.32 集装箱船配载优化
1.33 水泵组合优化
1.34 医疗资源分配优化
1.35 可视域基站和无人机选址优化
2 机器学习和深度学习分类与预测
2.1 机器学习和深度学习分类
2.1.1 BiLSTM双向长短时记忆神经网络分类
2.1.2 BP神经网络分类
2.1.3 CNN卷积神经网络分类
2.1.4 DBN深度置信网络分类
2.1.5 DELM深度学习极限学习机分类
2.1.6 ELMAN递归神经网络分类
2.1.7 ELM极限学习机分类
2.1.8 GRNN广义回归神经网络分类
2.1.9 GRU门控循环单元分类
2.1.10 KELM混合核极限学习机分类
2.1.11 KNN分类
2.1.12 LSSVM最小二乘法支持向量机分类
2.1.13 LSTM长短时记忆网络分类
2.1.14 MLP全连接神经网络分类
2.1.15 PNN概率神经网络分类
2.1.16 RELM鲁棒极限学习机分类
2.1.17 RF随机森林分类
2.1.18 SCN随机配置网络模型分类
2.1.19 SVM支持向量机分类
2.1.20 XGBOOST分类
2.2 机器学习和深度学习预测
2.2.1 ANFIS自适应模糊神经网络预测
2.2.2 ANN人工神经网络预测
2.2.3 ARMA自回归滑动平均模型预测
2.2.4 BF粒子滤波预测
2.2.5 BiLSTM双向长短时记忆神经网络预测
2.2.6 BLS宽度学习神经网络预测
2.2.7 BP神经网络预测
2.2.8 CNN卷积神经网络预测
2.2.9 DBN深度置信网络预测
2.2.10 DELM深度学习极限学习机预测
2.2.11 DKELM回归预测
2.2.12 ELMAN递归神经网络预测
2.2.13 ELM极限学习机预测
2.2.14 ESN回声状态网络预测
2.2.15 FNN前馈神经网络预测
2.2.16 GMDN预测
2.2.17 GMM高斯混合模型预测
2.2.18 GRNN广义回归神经网络预测
2.2.19 GRU门控循环单元预测
2.2.20 KELM混合核极限学习机预测
2.2.21 LMS最小均方算法预测
2.2.22 LSSVM最小二乘法支持向量机预测
2.2.23 LSTM长短时记忆网络预测
2.2.24 RBF径向基函数神经网络预测
2.2.25 RELM鲁棒极限学习机预测
2.2.26 RF随机森林预测
2.2.27 RNN循环神经网络预测
2.2.28 RVM相关向量机预测
2.2.29 SVM支持向量机预测
2.2.30 TCN时间卷积神经网络预测
2.2.31 XGBoost回归预测
2.2.32 模糊预测
2.2.33 奇异谱分析方法SSA时间序列预测
2.3 机器学习和深度学习实际应用预测
CPI指数预测、PM2.5浓度预测、SOC预测、财务预警预测、产量预测、车位预测、虫情预测、带钢厚度预测、电池健康状态预测、电力负荷预测、房价预测、腐蚀率预测、故障诊断预测、光伏功率预测、轨迹预测、航空发动机寿命预测、汇率预测、混凝土强度预测、加热炉炉温预测、价格预测、交通流预测、居民消费指数预测、空气质量预测、粮食温度预测、气温预测、清水值预测、失业率预测、用电量预测、运输量预测、制造业采购经理指数预测
3 图像处理方面
3.1 图像边缘检测
3.2 图像处理
3.3 图像分割
3.4 图像分类
3.5 图像跟踪
3.6 图像加密解密
3.7 图像检索
3.8 图像配准
3.9 图像拼接
3.10 图像评价
3.11 图像去噪
3.12 图像融合
3.13 图像识别
3.13.1 表盘识别
3.13.2 车道线识别
3.13.3 车辆计数
3.13.4 车辆识别
3.13.5 车牌识别
3.13.6 车位识别
3.13.7 尺寸检测
3.13.8 答题卡识别
3.13.9 电器识别
3.13.10 跌倒检测
3.13.11 动物识别
3.13.12 二维码识别
3.13.13 发票识别
3.13.14 服装识别
3.13.15 汉字识别
3.13.16 红绿灯识别
3.13.17 虹膜识别
3.13.18 火灾检测
3.13.19 疾病分类
3.13.20 交通标志识别
3.13.21 卡号识别
3.13.22 口罩识别
3.13.23 裂缝识别
3.13.24 目标跟踪
3.13.25 疲劳检测
3.13.26 旗帜识别
3.13.27 青草识别
3.13.28 人脸识别
3.13.29 人民币识别
3.13.30 身份证识别
3.13.31 手势识别
3.13.32 数字字母识别
3.13.33 手掌识别
3.13.34 树叶识别
3.13.35 水果识别
3.13.36 条形码识别
3.13.37 温度检测
3.13.38 瑕疵检测
3.13.39 芯片检测
3.13.40 行为识别
3.13.41 验证码识别
3.13.42 药材识别
3.13.43 硬币识别
3.13.44 邮政编码识别
3.13.45 纸牌识别
3.13.46 指纹识别
3.14 图像修复
3.15 图像压缩
3.16 图像隐写
3.17 图像增强
3.18 图像重建
4 路径规划方面
4.1 旅行商问题(TSP)
4.1.1 单旅行商问题(TSP)
4.1.2 多旅行商问题(MTSP)
4.2 车辆路径问题(VRP)
4.2.1 车辆路径问题(VRP)
4.2.2 带容量的车辆路径问题(CVRP)
4.2.3 带容量+时间窗+距离车辆路径问题(DCTWVRP)
4.2.4 带容量+距离车辆路径问题(DCVRP)
4.2.5 带距离的车辆路径问题(DVRP)
4.2.6 带充电站+时间窗车辆路径问题(ETWVRP)
4.2.3 带多种容量的车辆路径问题(MCVRP)
4.2.4 带距离的多车辆路径问题(MDVRP)
4.2.5 同时取送货的车辆路径问题(SDVRP)
4.2.6 带时间窗+容量的车辆路径问题(TWCVRP)
4.2.6 带时间窗的车辆路径问题(TWVRP)
4.3 多式联运运输问题
4.4 机器人路径规划
4.4.1 避障路径规划
4.4.2 迷宫路径规划
4.4.3 栅格地图路径规划
4.5 配送路径规划
4.5.1 冷链配送路径规划
4.5.2 外卖配送路径规划
4.5.3 口罩配送路径规划
4.5.4 药品配送路径规划
4.5.5 含充电站配送路径规划
4.5.6 连锁超市配送路径规划
4.5.7 车辆协同无人机配送路径规划
4.6 无人机路径规划
4.6.1 飞行器仿真
4.6.2 无人机飞行作业
4.6.3 无人机轨迹跟踪
4.6.4 无人机集群仿真
4.6.5 无人机三维路径规划
4.6.6 无人机编队
4.6.7 无人机协同任务
4.6.8 无人机任务分配
5 语音处理
5.1 语音情感识别
5.2 声源定位
5.3 特征提取
5.4 语音编码
5.5 语音处理
5.6 语音分离
5.7 语音分析
5.8 语音合成
5.9 语音加密
5.10 语音去噪
5.11 语音识别
5.12 语音压缩
5.13 语音隐藏
6 元胞自动机方面
6.1 元胞自动机病毒仿真
6.2 元胞自动机城市规划
6.3 元胞自动机交通流
6.4 元胞自动机气体
6.5 元胞自动机人员疏散
6.6 元胞自动机森林火灾
6.7 元胞自动机生命游戏
7 信号处理方面
7.1 故障信号诊断分析
7.1.1 齿轮损伤识别
7.1.2 异步电机转子断条故障诊断
7.1.3 滚动体内外圈故障诊断分析
7.1.4 电机故障诊断分析
7.1.5 轴承故障诊断分析
7.1.6 齿轮箱故障诊断分析
7.1.7 三相逆变器故障诊断分析
7.1.8 柴油机故障诊断
7.2 雷达通信
7.2.1 FMCW仿真
7.2.2 GPS抗干扰
7.2.3 雷达LFM
7.2.4 雷达MIMO
7.2.5 雷达测角
7.2.6 雷达成像
7.2.7 雷达定位
7.2.8 雷达回波
7.2.9 雷达检测
7.2.10 雷达数字信号处理
7.2.11 雷达通信
7.2.12 雷达相控阵
7.2.13 雷达信号分析
7.2.14 雷达预警
7.2.15 雷达脉冲压缩
7.2.16 天线方向图
7.2.17 雷达杂波仿真
7.3 生物电信号
7.3.1 肌电信号EMG
7.3.2 脑电信号EEG
7.3.3 心电信号ECG
7.3.4 心脏仿真
7.4 通信系统
7.4.1 DOA估计
7.4.2 LEACH协议
7.4.3 编码译码
7.4.4 变分模态分解
7.4.5 超宽带仿真
7.4.6 多径衰落仿真
7.4.7 蜂窝网络
7.4.8 管道泄漏
7.4.9 经验模态分解
7.4.10 滤波器设计
7.4.11 模拟信号传输
7.4.12 模拟信号调制
7.4.13 数字基带信号
7.4.14 数字信道
7.4.15 数字信号处理
7.4.16 数字信号传输
7.4.17 数字信号去噪
7.4.18 水声通信
7.4.19 通信仿真
7.4.20 无线传输
7.4.21 误码率仿真
7.4.22 现代通信
7.4.23 信道估计
7.4.24 信号检测
7.4.25 信号融合
7.4.26 信号识别
7.4.27 压缩感知
7.4.28 噪声仿真
7.4.29 噪声干扰
7.5 无人机通信
7.6 无线传感器定位及布局方面
7.6.1 WSN定位
7.6.2 高度预估
7.6.3 滤波跟踪
7.6.4 目标定位
7.6.4.1 Dv-Hop定位
7.6.4.2 RSSI定位
7.6.4.3 智能算法优化定位
7.6.5 组合导航
8 电力系统方面
微电网优化、无功优化、配电网重构、储能配置















 2506
2506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









