







算法一:线性回归
1.建立一元线性回归模型:

给出一组训练集:
m:为训练集的数据项个数
x:为输入,是自变量
y:为输出,是因变量
h(x):给出训练集通过一些算法可以得到一个函数 ,输入一个x就可以得到接近真实数值的y

而机器学习的目的就在于找到这个一元线性函数h(x)=kx+b,找到最合适的k和b
2.找到代价函数或称平方误差函数

在求一个函数的系数的时候,即h(x)=kx+b,找到最合适的k和b,就需要找其应用的约束条件,由于计算出的函数值h(x)应该与训练集中x对应的真实值y越接近越好,所h(x)-y越小越好,所以首先应该取训练集所有预测值和真实值的差的平方的和,故这是带有k和b参数的表达式,可以称为代价函数J(k,b),在其函数值最小时,即预测和真实值最接近时,取得的k,b即为函数系数
3.保留一个参数的代价函数J(k)

训练集为{1,1}{2,2}{3,3}

4.保留两个参数的代价函数J(k,b)

高度即z轴的数值最小的点就是代价函数值最小的点
5.寻找代价函数值最小值的方法:梯度下降法

初始值:J(k1=0,k2=0...kn=0)
特点:选择下山最小路径时,越是在顶部越容易差生较大的差距
梯度下降法公式如下

1. 公式a:=b,是将b赋值给a的意思,下降梯度公式如上
2. k1,k2要同步更新,因为如果有一个数值变了,另一个对J(k1,k2)求偏导就会有偏差
3.初始化位置:
假设只考虑一个参数,上半部分图是初始化点在最低点右侧时,对函数求导数也就是初始化的一点的导数为正的,所以参数k是逐渐减小的,当初始化一点是在最小值左边时如下半部分图,初始化一点的导师为负数,那么参数k是逐渐增加的,因此初始化时要在最小值的右侧部分

4. 学习速率的大小

学习速率太小时,下降的慢,学习速率太大时可能错过最低点反而使参数值升高
5.局部最优点

此时这个点的导数为0,参数继续减小时导数为负数反而增加,所以这个点是局部最优点
6.梯度下降法的好处

例如此函数,初始化的k越大,导数越大,根据公式可知J(k)下降越快,粒度越粗,逐渐的函数图像变得平缓,导数也减小,J(k)下降的越慢,粒度越来越细,当导数为0时,即使最低点,J(k)最小的点
6.平方误差函数和梯度下降法的结合

结合之前的平方误差公式,把J(k,b)带入梯度下降公式,求出偏导:
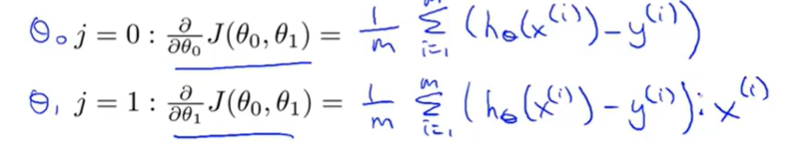
最终得到公式:

在此基础上建立假设函数和多个参数的代价函数的模型

中心位置即为全集最优解















 2603
2603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









