







文章目录
embedding
在语句处理方面,如果采用我们之前机器学习当中的one-hot编码的话,对于内存的使用会是一个很大的支出,因为在于我们正常的多篇篇文章的分词,很可能达到上万以上的词,而one-hot的编码的每一个词就需要对应一个维度,我们的使用,而且还是一个稀疏矩阵,在使用的时候,这就造成了一个很大的浪费,这也不利于我们的语料分析,而且他的每一个词语之间没有相关的相似度关系,这也很关键,就比如说,他并不能计算出(男-女)=(国王-王后)这种经典的问题,这时就引入了embedding这种说法。
这些问题的解决方案是使用embedding,embedding将大型稀疏向量转换为保留语义关系的低维空间。 我们将在本单元的以下部分中直观地、概念上地和编程式地探索embedding。
embedding的原理
embedding实际上就是一个特殊的全连接层(FC),我们根据下面的定义可得,相同的,batch-size我们此时可以看成是1,或者说实际上我们可以这么理解,我们实际上的训练是根据一篇文章一篇文章进行的训练的。

然后相同的这里只是关于one-hot的embedding的介绍,但是相同的还有很多别的方式进行操作,比如词袋,tfidf(词频),ngram(滑窗),这些的操作就是基于one-hot上的进行限制,这边就不介绍了,也很好去理解。
然后就是关于sparse和one-hot的区别,前者实际上就是直接one-hot映射出来的整形数字,举个例子,一共有两个词 一个是我,一个是你。对于one-hot来说,我就是(1,0),你就是(0,1),然后就是对于sparse来说,我就是1,你就是2,这样子的说法。
相关的代码演示
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import tensorflow as tf
from tensorflow import keras
# 准备数据 karas自带的数据集imdb,电影分类,分电影是积极的,还是消极的
# -----------------------------------------------------------------------------
imdb = keras.datasets.imdb
# 词袋大小 也即总共最多设置多少个one-hot列数
vocab_size = 10000
# 代表的是偏移量,也即我们采用的是sparse进行替代one-hot编码,看了后面自然懂
index_from = 3
# 需要注意的一点是取出来的词表还是从1开始的,需要做处理,训练集是一段语料,一段就是一串文字,而label是0或1 0是消极 1是积极
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = vocab_size, index_from = index_from)
print(train_data[0])
# 载入词表,这个是已经提前训练好的了,当然之后讲解word2vec的时候,我们会自己去训练这一个词表
word_index = imdb.get_word_index()
word_index = {key:value+index_from for key, value in word_index.items()}
word_index['<PAD>'] = 0 # 做padding时,我们来填充的字符
word_index['<START>'] = 1 # 起始
word_index['<UNK>'] = 2 # 找不到就返回UNK
word_index['<END>'] = 3 # 每个句子末尾
reverse_word_index = {value:key for key,value in word_index.items()}
def decode_review(text_ids):
return ' '.join([reverse_word_index.get(word_id, "<UNK>") for word_id in text_ids])
#有了reverse我们可以反向转回来看看这句话是什么,就是把数字解释为了真实的文本
print(decode_review(train_data[0]))
print('-'*20)
# 由于文字是非等长的,所以我们这边需要统一把文字搞成等长的,这边就采用500个为界限,这也是embedding的一个关键
max_length = 500
# pre,post padding的顺序,一个是放前面,一个是后面
print(train_data.shape) # 不等长所以第二维度显示不出来
train_data = keras.preprocessing.sequence.pad_sequences(train_data,value = word_index['<PAD>'],padding = 'post',maxlen = max_length)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,value = word_index['<PAD>'],padding = 'post',maxlen = max_length)
print(train_data.shape)
print('-'*20)
# -----------------------------------------------------------------------------
# 搭建模型 或者说embedding本身就是一个layer
# -----------------------------------------------------------------------------
# embedding_dim,每个词的向量维度是16
embedding_dim = 16
batch_size = 128
model = keras.models.Sequential([
# 传入的时候实际上会把sparse转化为one-hot,所以实际上vocab_size可以当作是输入矩阵的列维度,embedding_dim自然就是输出出来的维度了,input_shape就是输入和输出的行数
keras.layers.Embedding(vocab_size, embedding_dim, input_length = max_length),
# GlobalAveragePooling1D是把batch_size * max_length * embedding_dim 变成 batch_size * embedding_dim,消除维度max_length
keras.layers.GlobalAveragePooling1D(),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation = 'sigmoid'),
])
# 参数需要自己学会如何进行计算,如这边的embedding层的参数,自然就是vocab_size*embedding的结果。
model.summary()
model.compile(optimizer = 'adam', loss = 'binary_crossentropy',metrics = ['accuracy'])
# -----------------------------------------------------------------------------
# 训练模型以及评估模型
# -----------------------------------------------------------------------------
history = model.fit(train_data, train_labels, epochs = 30, batch_size = batch_size, validation_split = 0.2)
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
plot_learning_curves(history, 'accuracy', 30, 0, 1)
plot_learning_curves(history, 'loss', 30, 0, 1)
model.evaluate(test_data, test_labels,batch_size = batch_size,verbose = 0)
# -----------------------------------------------------------------------------
输出:
[1, 14, 22, 16, 43, 530, ··· 19, 178, 32]
<START> this film was just brilliant ··· us all
--------------------
(25000,)
(25000, 500)
--------------------
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 500, 16) 160000
global_average_pooling1d_1 (None, 16) 0
(GlobalAveragePooling1D)
dense_2 (Dense) (None, 64) 1088
dense_3 (Dense) (None, 1) 65
=================================================================
Total params: 161153 (629.50 KB)
Trainable params: 161153 (629.50 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/30
157/157 [==============================] - 4s 15ms/step - loss: 0.6790 - accuracy: 0.6368 - val_loss: 0.6340 - val_accuracy: 0.7632
······
Epoch 30/30
157/157 [==============================] - 2s 12ms/step - loss: 0.0198 - accuracy: 0.9969 - val_loss: 0.6016 - val_accuracy: 0.8756
图片1
图片2
[0.6545140147209167, 0.8585600256919861]
图片1
图片2
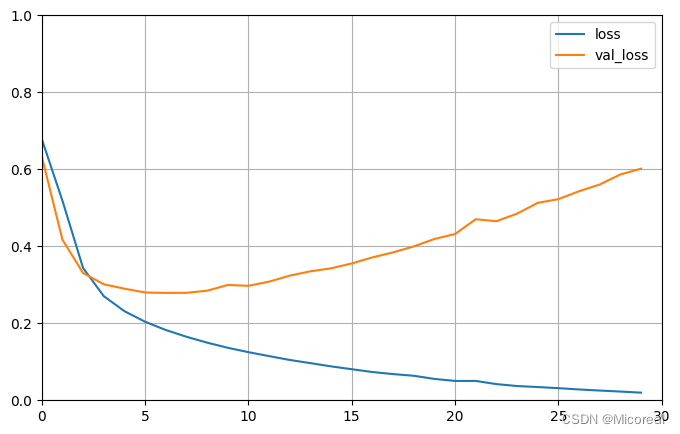
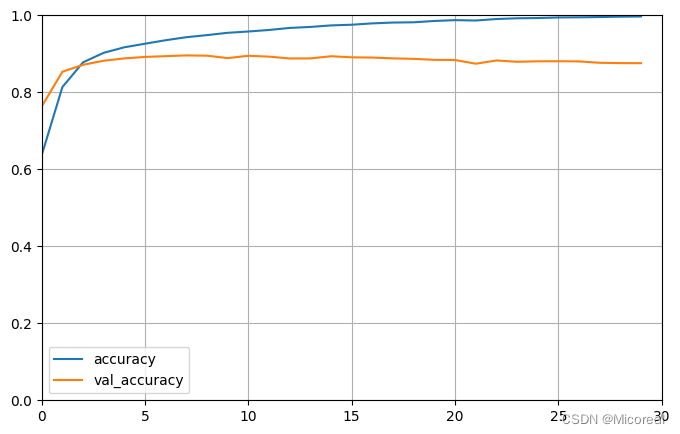
哈哈,这边可以明显看出过拟合了doge,寻思训练的很快,就定了30
RNN
出现的原因
只完成上面的embedding,我们却没有办法实现一篇篇文章之间的顺序区别,比如只用embedding的话,我们只能知道此篇文章出现了这个词语,但是往往很多情况之下,词语与词语之间的顺序也会有一定的意思,比如说前文说过我是中国人,后文我会说i speak 然后填写,如果对于一个没有记忆力的人来说,我们这边只根据speak,我们会回答english,但是前文出现了china,所以这边需要根据前文的信息,填上chinese,这是有点关键的,所以也可以这么说RNN,完成的是模型的记忆力,也称作序列能力sequence。
还有就是RNN也解决了我们生成序列的不确定数目以及输入的不确定数目。
基本原理
基本细胞:
基本模型:
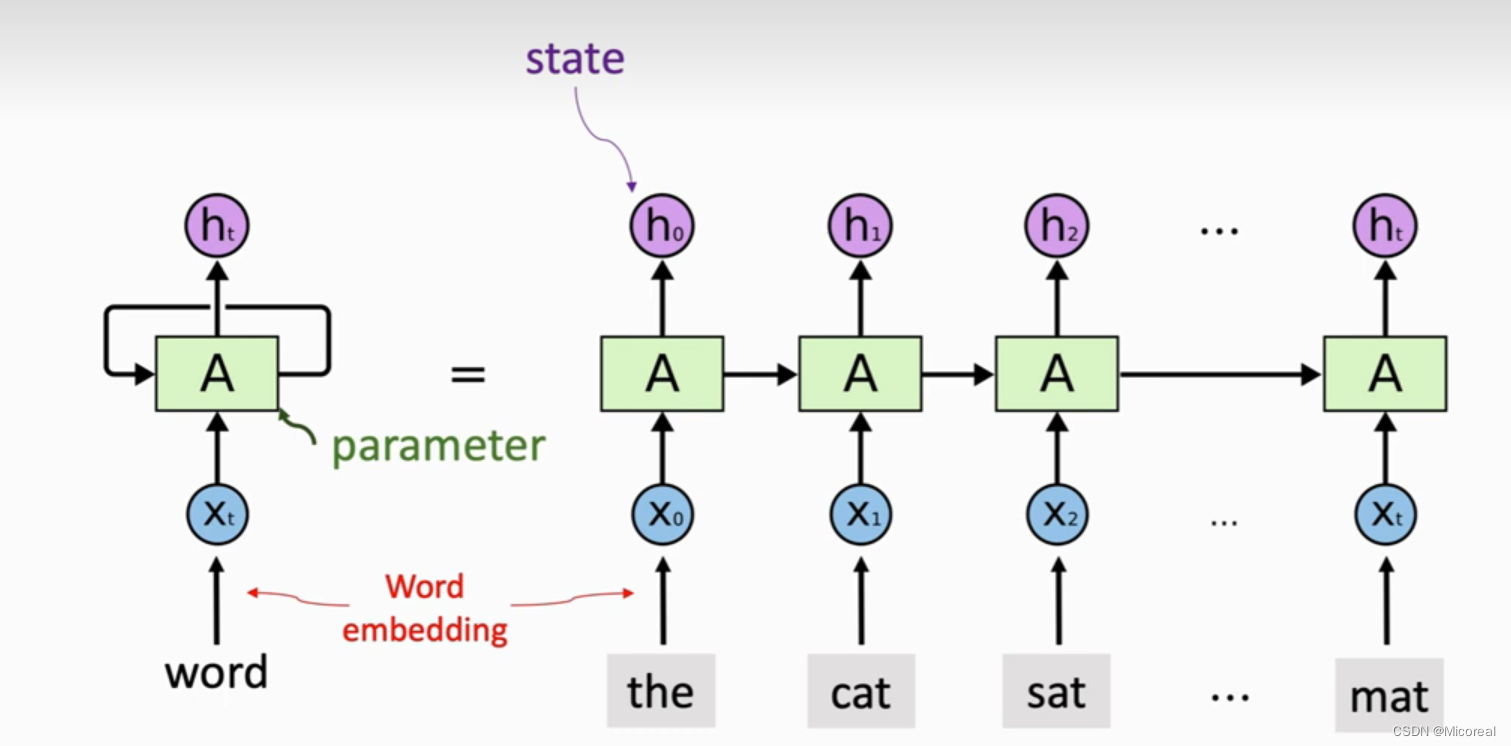
可以看出在RNN模型当中,每一次输出的东西都会传递给下一个式子,然后和下一个输入拼接好,进行运算,也就是说我们后一个的输出兼具了之前所有输入的所有消息,这和我们正常的人的阅读是很相同的,当人阅读一篇文章的时候,都是从左到右看,然后看到一个新的文字之后,就会和之前的所有文字进行相关联。
具体的计算:
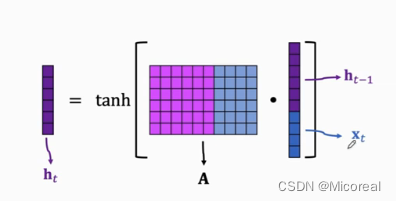
我们可以看出,我们的式子实际上是把输入和上一次的输出进行concate,然后和一个w矩阵进行相乘,最后得到下一个h,然后在和之后的x拼接或者作为最后一层进行输出。
然后就是为什么会存在这个tanh这个激活函数呢?这个实际上和我们之前所有的定义激活函数的功能也差不太多,实际上就是对于数据进行的重新投射到一定的位置,避免会出现梯度爆炸或者梯度消失(之前可能没说过激活函数可以解决梯度爆炸和梯度消失,原因就是之前的神经网络几乎都是在模仿逻辑回归这种做法,自然就存在激活函数,个人没往那个地方想hh)。
那么还有第二个问题,参数该怎么计算呢?
首先RNN和CNN一样,也是共享参数,这边个人不懂共享参数的理论支持是什么,暂时也没有发现,但这样子的操作确实做的很好,然后参数的计算总量(h * (h+x)),这也很简单可以发现。
RNN基本代码------只取hn
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
# 准备数据 karas自带的数据集imdb,电影分类,分电影是积极的,还是消极的
# -----------------------------------------------------------------------------
imdb = keras.datasets.imdb
vocab_size = 10000
index_from = 3
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = vocab_size, index_from = index_from)
word_index = imdb.get_word_index()
word_index = {key:value+index_from for key, value in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2
word_index['<END>'] = 3
reverse_word_index = {value:key for key,value in word_index.items()}
max_length = 500
train_data = keras.preprocessing.sequence.pad_sequences(train_data,value = word_index['<PAD>'],padding = 'post',maxlen = max_length)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,value = word_index['<PAD>'],padding = 'post',maxlen = max_length)
# -----------------------------------------------------------------------------
# 模型搭建 主要的变化就是加了一层RNN
# -----------------------------------------------------------------------------
embedding_dim = 16
batch_size = 512
#相对于之前主要改的是这里
single_rnn_model = keras.models.Sequential([
keras.layers.Embedding(vocab_size, embedding_dim, input_length = max_length),
# return_sequences是返回输出序列中的最后一个输出还是完整序列,False就是返回最后一个,如果等于True就是返回一整个序列,也就是h1,h2···hn
# units实际上就是状态向量h的维度
keras.layers.SimpleRNN(units = 64, return_sequences = False),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
# 这边的RNN的计算参数:h*(h+x)+b(也就是h) = 64*(16+64)+64
# 然后这边没有对于embedding进行全局池化,原因是经过RNN之后,实际上降维了,原因可以认为就是我们上面的return_sequences=false,导致输入的原本是500个有序单词,但是输出的是一个单词,或者可以理解只有尾部的一个变量,这边就自然降维了
single_rnn_model.summary()
single_rnn_model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# -----------------------------------------------------------------------------
# 训练和模型评估
# -----------------------------------------------------------------------------
# 我们这里和之前不一样,没有验证集,所以分20%给验证集
history_single_rnn = single_rnn_model.fit(train_data, train_labels, epochs = 30, batch_size = batch_size,validation_split = 0.2)
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
plot_learning_curves(history_single_rnn, 'accuracy', 30, 0, 1)
plot_learning_curves(history_single_rnn, 'loss', 30, 0, 1)
model.evaluate(test_data, test_labels,batch_size = batch_size,verbose = 0)
# -----------------------------------------------------------------------------
输出:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 500, 16) 160000
simple_rnn_2 (SimpleRNN) (None, 64) 5184
dense_4 (Dense) (None, 64) 4160
dense_5 (Dense) (None, 1) 65
=================================================================
Total params: 169409 (661.75 KB)
Trainable params: 169409 (661.75 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/30
40/40 [==============================] - 24s 572ms/step - loss: 0.6936 - accuracy: 0.5023 - val_loss: 0.6950 - val_accuracy: 0.4938
······
Epoch 30/30
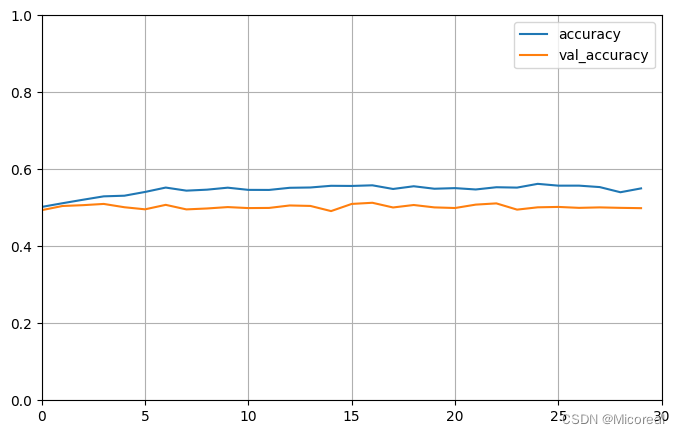
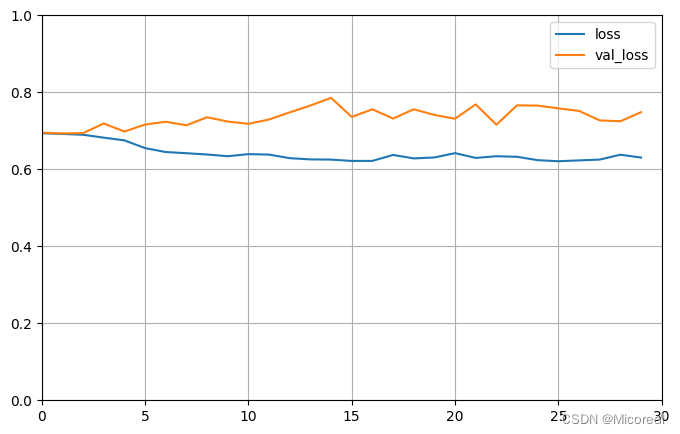
40/40 [==============================] - 20s 498ms/step - loss: 0.6304 - accuracy: 0.5504 - val_loss: 0.7483 - val_accuracy: 0.4990
图片1
图片2
[0.745481014251709, 0.49932000041007996]
图片1
图片2
简单的RNN------取整个sequence
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
import os
# 这边直接进行编号,当然效果是很不好的,但这边还没介绍过word2vec 就先这样子,了解一下思想
# 记得上传文件 文件地址:https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt
input_filepath = "./shakespeare.txt"
text = open(input_filepath, 'r').read()
# 去重
vocab = sorted(set(text))
char2idx = {char:idx for idx, char in enumerate(vocab)}
# 把vocab从列表变为ndarray 实际上就是把key拿出来,变成键的数组
idx2char = np.array(vocab)
# 把字符都转换为id
text_as_int = np.array([char2idx[c] for c in text])
# 自定义输入与输出 实际上就是输入是abcd 输出是bcde
def split_input_target(id_text):
return id_text[0:-1], id_text[1:]
# 把id text转换为 dataset
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
seq_length = 100
# 做一个batch,seq_length + 1目的是我们输入是5个字符时,输出是4,drop_remainder
# 是最后不够就丢掉,这个batch是把字变为句子,一个句子是101个字符
seq_dataset = char_dataset.batch(seq_length + 1,drop_remainder = True)
# 然后通过split_input_target函数来对seq_dataset做映射,得到输入,输出
seq_dataset = seq_dataset.map(split_input_target)
batch_size = 64
buffer_size = 10000
# 这个batch是真正的batch,上一个batch是把字变为句子,buffer_size是从数据集拿那么多元素
# drop_remainder=True 这个实际上就是不整除的部分最后不要了,就是我们每次取出来的batch-size之后最后可能会导致我们的batch-size不一样
seq_dataset = seq_dataset.shuffle(buffer_size).batch(batch_size, drop_remainder=True)
print(seq_dataset)
vocab_size = len(vocab)
embedding_dim = 256 # 资料比较小,所以dim可以设大一些
rnn_units = 1024
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = keras.models.Sequential([
keras.layers.Embedding(vocab_size, embedding_dim,batch_input_shape = [batch_size, None]),
# return_sequences是指要返回一个序列,也就是所有输出,而不是最后一个
# stateful = True把本次的x输出放到下一次batch当中训练中使用 return_sequences = True则是返回一个序列
keras.layers.SimpleRNN(units = rnn_units,stateful = True,recurrent_initializer = 'glorot_uniform',return_sequences = True),
# 全连接层,输出的需要是和输入等长,我们这边的训练是abcd 训练出 bcde
keras.layers.Dense(vocab_size),
])
return model
model = build_model(vocab_size = vocab_size,embedding_dim = embedding_dim,rnn_units = rnn_units,batch_size = batch_size)
model.summary()
def loss(labels, logits):
return keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
model.compile(optimizer = 'adam', loss = loss)
#定义一个文件夹,保存模型
output_dir = "./text_generation_checkpoints"
if not os.path.exists(output_dir):
os.mkdir(output_dir)
checkpoint_prefix = os.path.join(output_dir, 'ckpt_{epoch}')
# 只保存权重的值
checkpoint_callback = keras.callbacks.ModelCheckpoint(filepath = checkpoint_prefix,save_weights_only = True)
epochs = 100
history = model.fit(seq_dataset, epochs = epochs,callbacks = [checkpoint_callback])
输出:
<_BatchDataset element_spec=(TensorSpec(shape=(64, 100), dtype=tf.int64, name=None), TensorSpec(shape=(64, 100), dtype=tf.int64, name=None))>
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (64, None, 256) 16640
simple_rnn (SimpleRNN) (64, None, 1024) 1311744
dense (Dense) (64, None, 65) 66625
=================================================================
Total params: 1395009 (5.32 MB)
Trainable params: 1395009 (5.32 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/100
172/172 [==============================] - 20s 81ms/step - loss: 2.7906
···
Epoch 100/100
172/172 [==============================] - 15s 77ms/step - loss: 1.0401
# 调用模型生成文字
output_dir = "./text_generation_checkpoints"
model2 = build_model(vocab_size,embedding_dim,rnn_units,batch_size = 1)
model2.load_weights(tf.train.latest_checkpoint(output_dir))
model2.summary()
# 定义一个函数来实现上面的文本生成流程
def generate_text(model, start_string, num_generate = 1000):
#这一次输出的是1维的
input_eval = [char2idx[ch] for ch in start_string]
print(input_eval)
#做一个维度扩展
input_eval = tf.expand_dims(input_eval, 0)
print(input_eval)
text_generated = []
#对model进行reset,连续调用的时候使用resets_states()
model.reset_states()
for _ in range(num_generate):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
predicted_id = tf.random.categorical(
predictions, num_samples = 1)[-1, 0].numpy()
text_generated.append(idx2char[predicted_id])
# 下面这是是我们原来的公式,为什么没有append作为新的输入,因为那样比较低效
input_eval = tf.expand_dims([predicted_id], 0)
return start_string + ''.join(text_generated)
new_text = generate_text(model2, "All: ")
print(new_text)
输出:
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (1, None, 256) 16640
simple_rnn_3 (SimpleRNN) (1, None, 1024) 1311744
dense_3 (Dense) (1, None, 65) 66625
=================================================================
Total params: 1395009 (5.32 MB)
Trainable params: 1395009 (5.32 MB)
Non-trainable params: 0 (0.00 Byte)
[13, 50, 50, 10, 1]
tf.Tensor([[13 50 50 10 1]], shape=(1, 5), dtype=int32)
All:这边肯定不成话,训练的方法太差理解个原理吧
简单RNN的局限
这边虽然RNN解决了我们一直想要解决的记忆问题,但是RNN经过实践证明他的记忆和鱼一样,只有七秒,对于简单RNN来说,他的记忆只在很小的一块区域内进行,这就需要进行相关的改变。
LSTM
首先先明白一个道理,LSTM也属于一种RMM,那么LSTM解决了RNN的什么局限性呢?普通 RNN 的信息不能长久传播(存在于理论上)—原因是针对结尾较远的信息被稀释的比较厉害,而LSTM引入了,引入选择性机制,选择性输出,选择性输入,选择性遗忘机制来解决这一些问题。
原理介绍
基本的原理图阐释
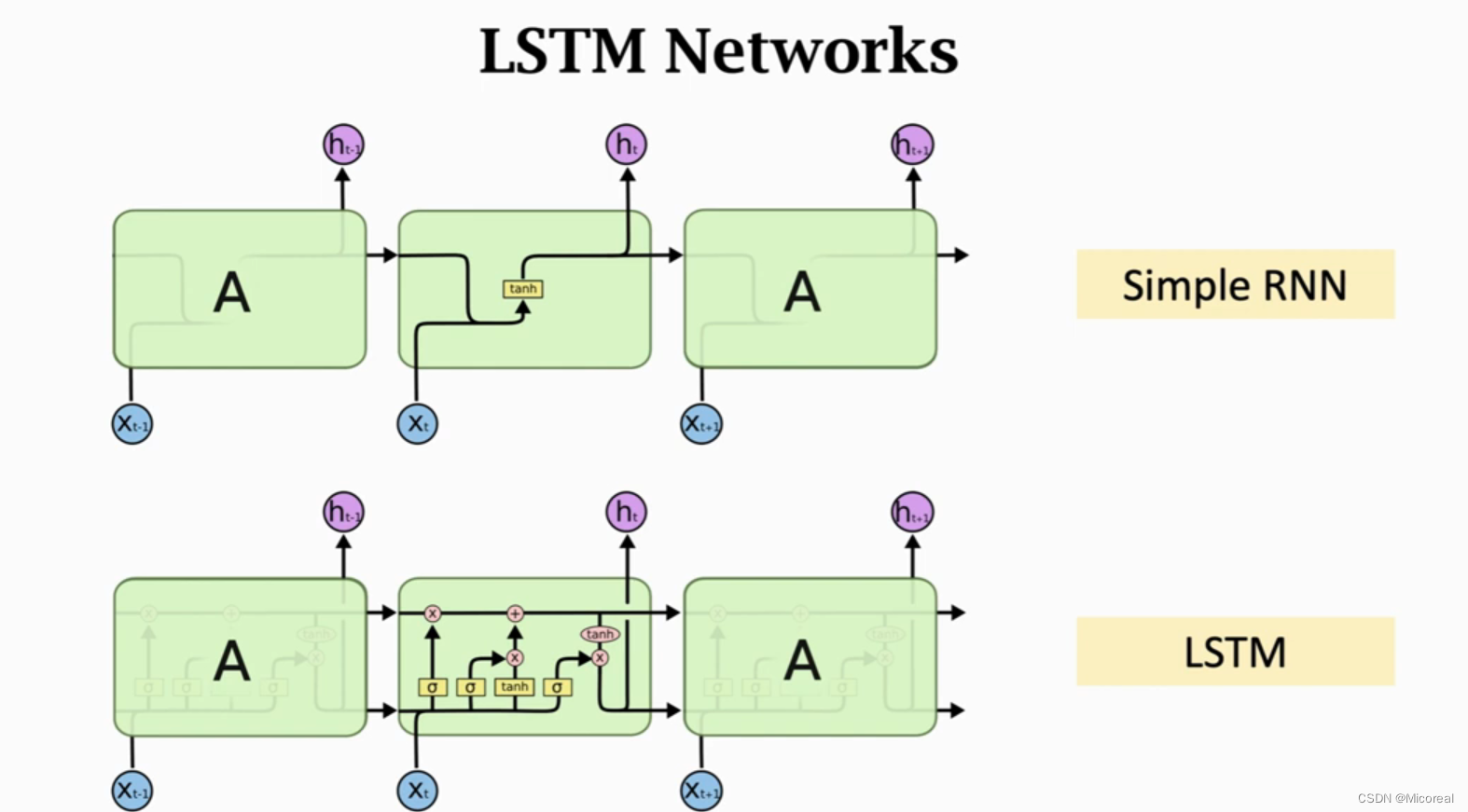
这边一看很复杂,确实很复杂,但我们分步骤去理解即可,重要理解的是LSTM相对于SimpleRNN多了一条传送带C,我们可以把他理解成神经网络的记忆,然后还有四个门,遗忘门f,输入门,当前状态门,输出门,后面会进行相关详细的介绍。
这一带四门(想着四保一战略不就是一带四吗)需要重点记忆,这也是面试考察的关键点。
一带,也可以说是当前状态带
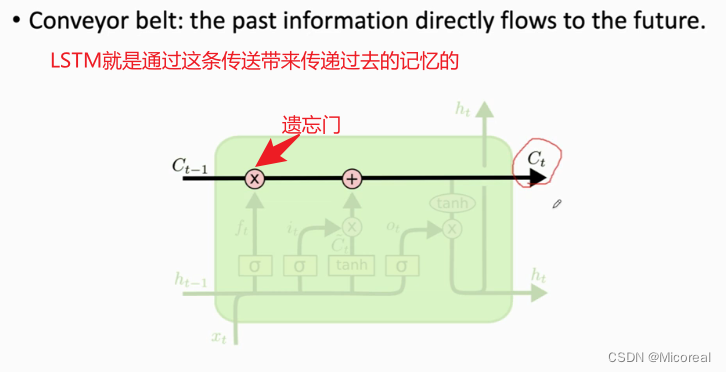
回想一下为什么需求这条传送带,原因就是我们之前所采用的是hn-1,来进行传送信息,但是hn-1每一次都需要进行运算,中间就会经历很多的运算,我们再去回忆信息的时候,就会发现,很容易产生梯度爆炸或者梯度消失的效果,所以这边我们新引入一条带子,相当于我们把记忆和传递分离开。
遗忘门:
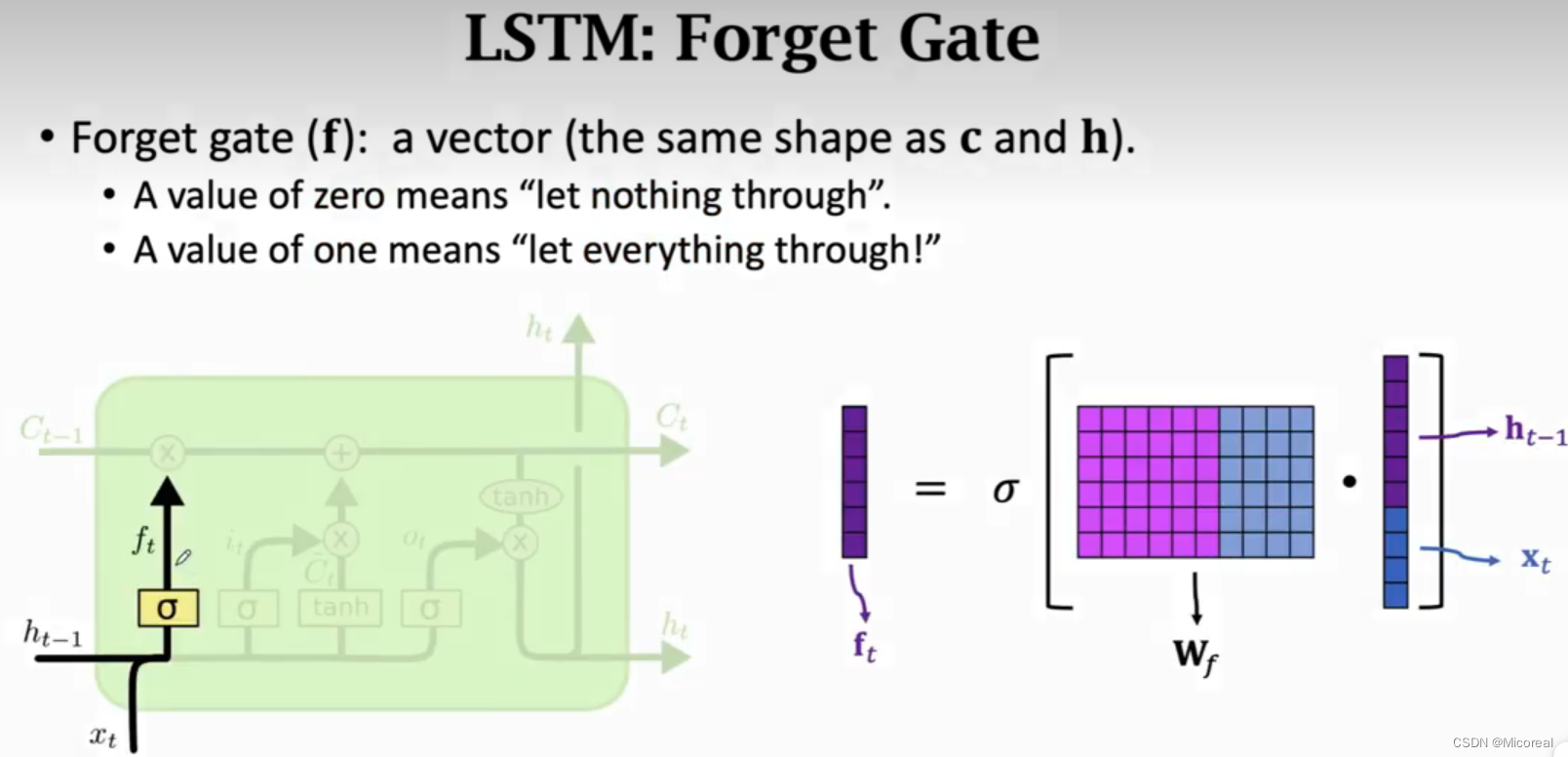
这个门所做的事情实际上是创建一个遗忘程度的门,我们通过这个门生成f矩阵,这个矩阵之后是要拿来和Ct-1进行element mult的(元素相乘的),所以效果实际上就是这个门反应出来的效果就是我对于C的记忆程度。
输入门:
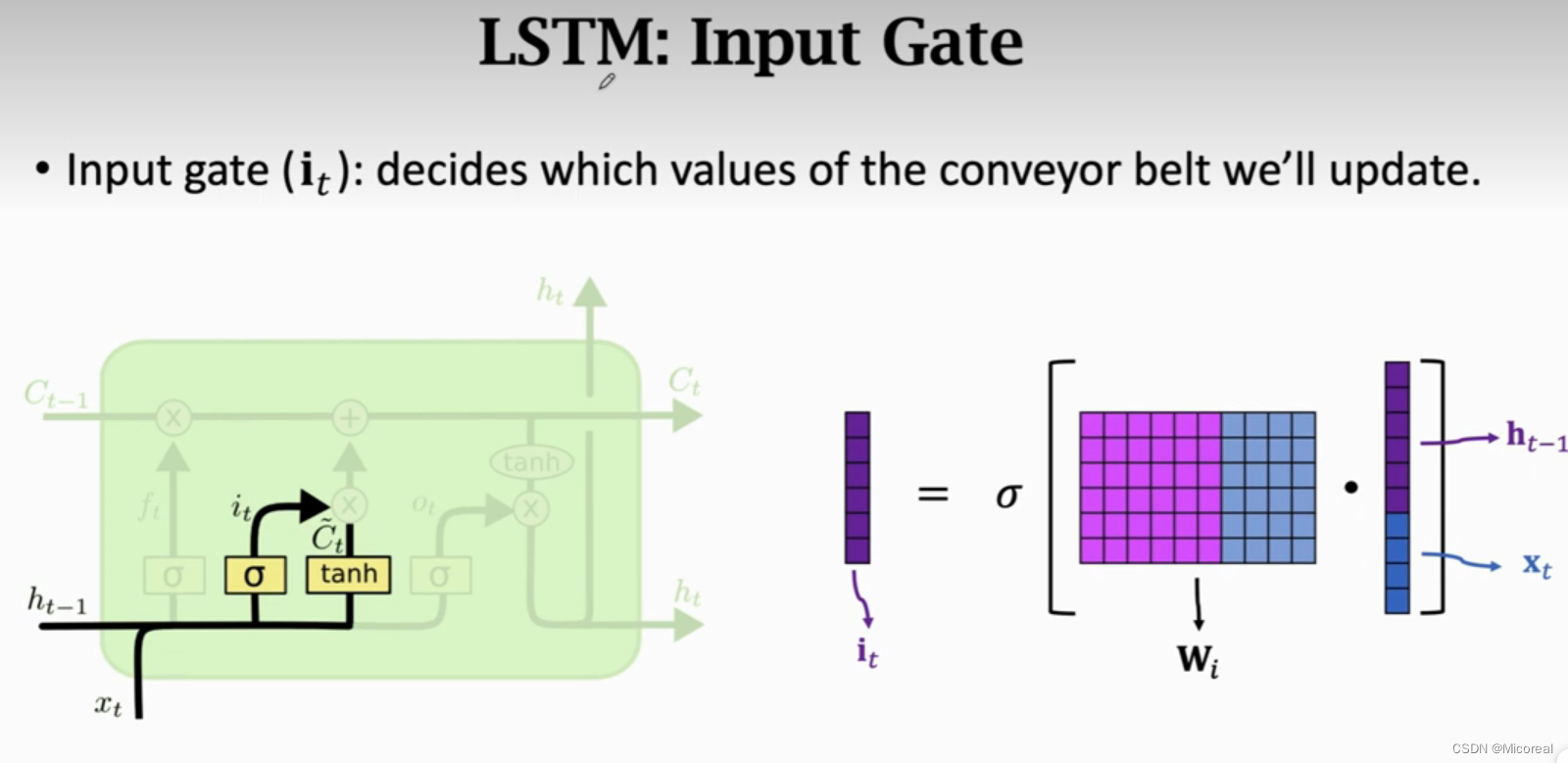
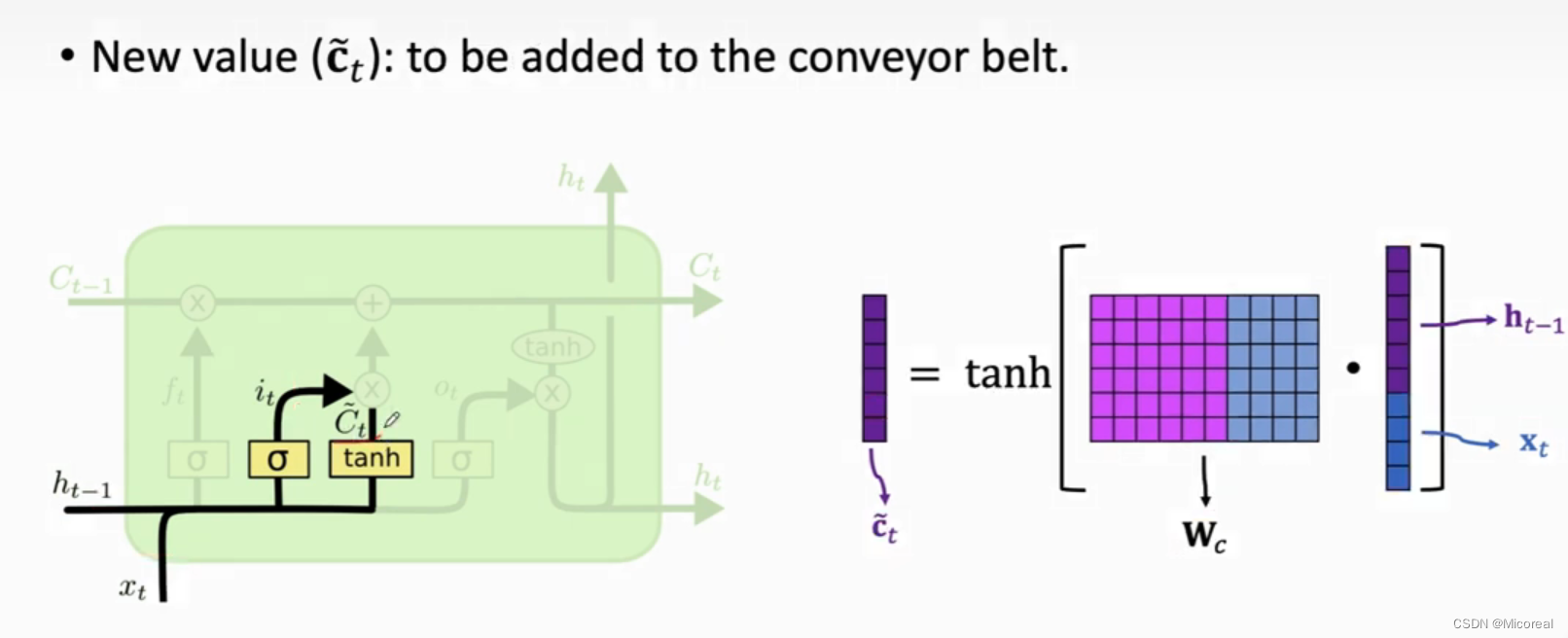
这边值得关注的是sigmoid产生的数据是(0,1),而tanh产生的数据是(-1,1),这就是这两个门比较大的差别,这个该怎么理解呢?这个门的作用是用于更新Cn-1的,个人觉得,it的计算实际上就是在传递这个记忆,然后乘上tanh,个人觉得就是在说这个记忆到底是对总的记忆产生记忆作用还是遗忘作用,然后这个新的记忆就一起到后面的相加处进行更新记忆。
更新门:
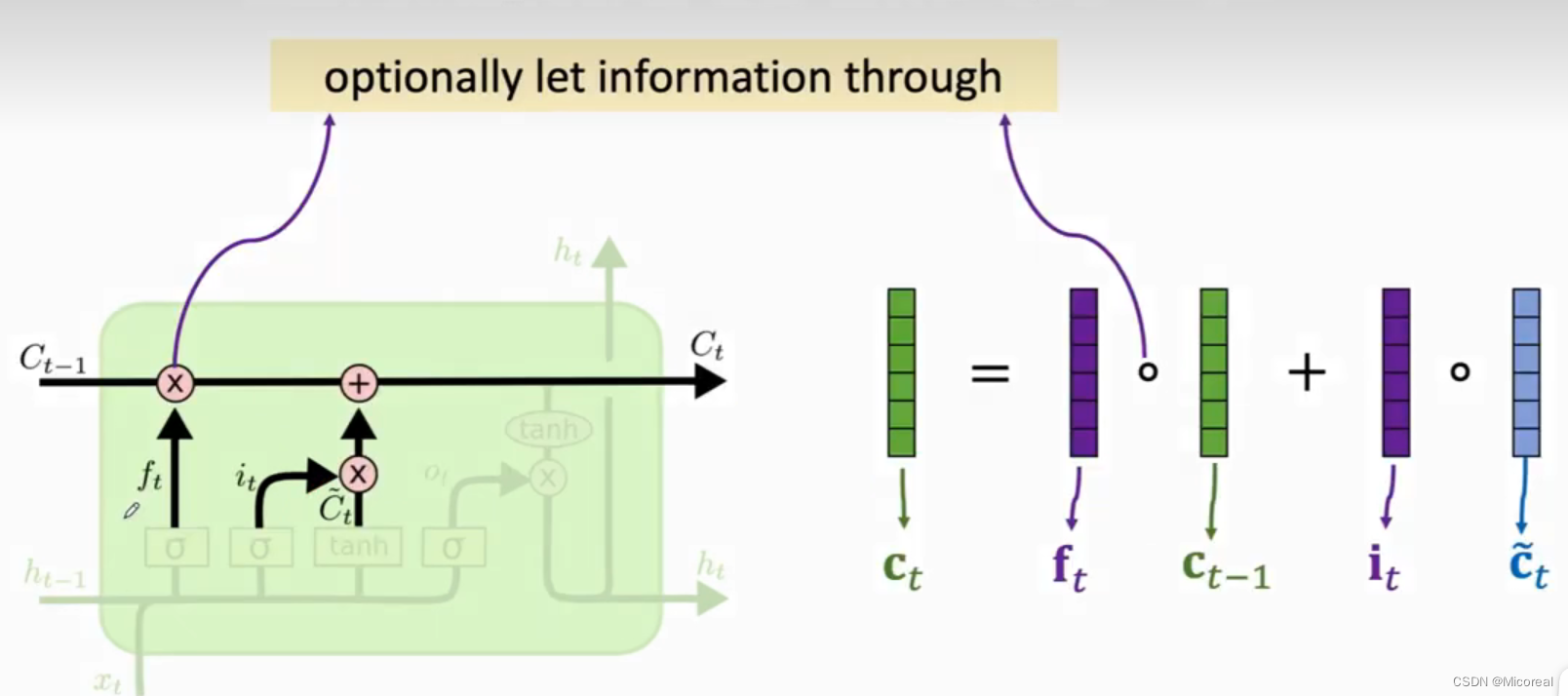
这个门的生成前面也讲解过实际的原理,这边就不再说了。
输出门:
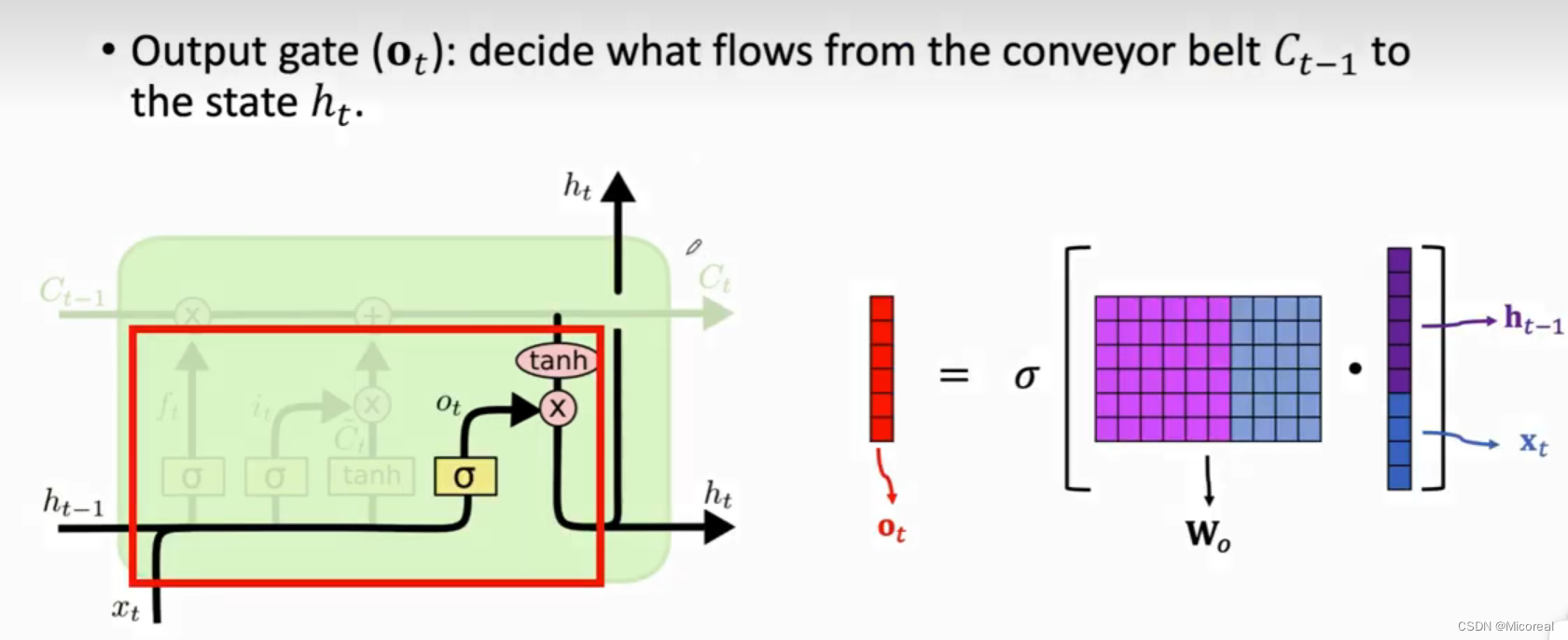
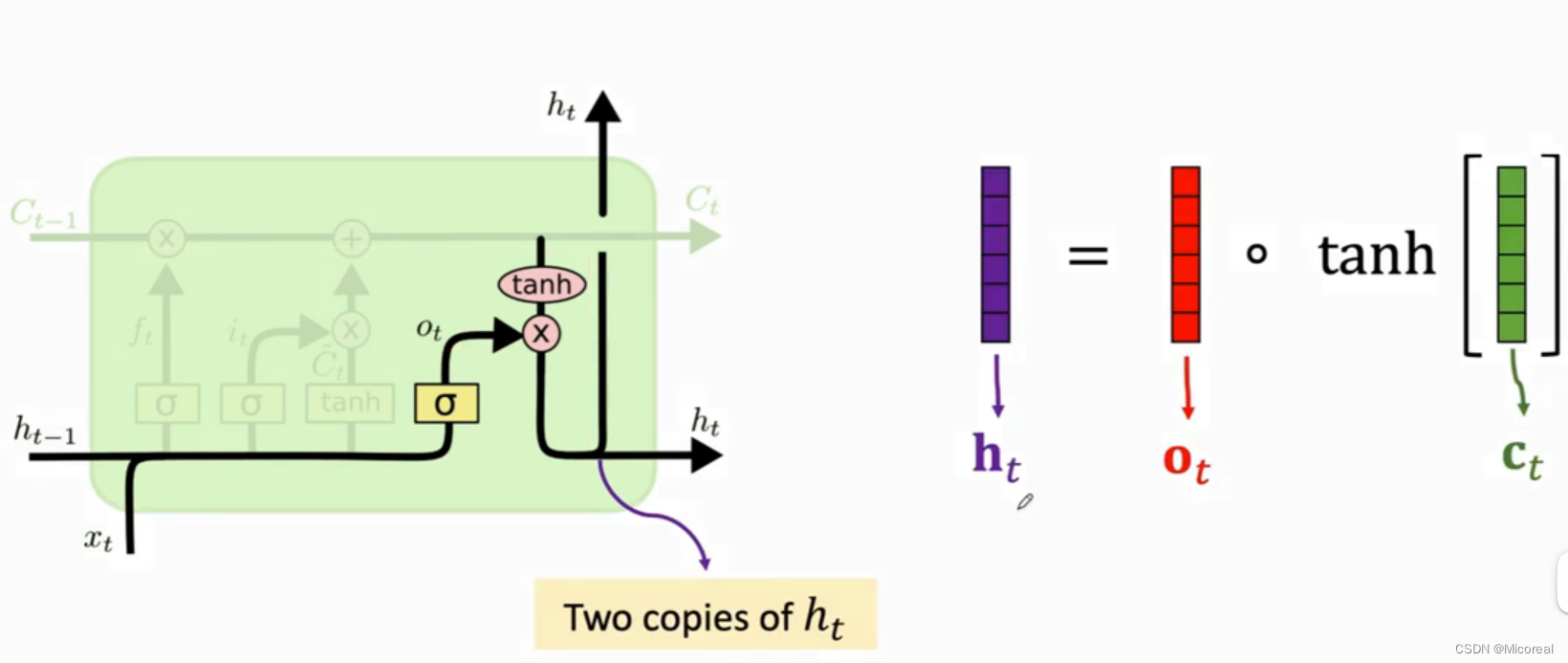
这两张图也详细说明了计算的流程,这边也只讲解关于概念上的理解,第一张图自然完成的还是把当前的状态进行输入,第二张图则是关于记忆和当前状态的合成,这边看图也很好理解。
参数:
在整个流程中,我们会发现实际上我们就只用到了四张w,和rnn一样的w,所以自然w的总数就是4 * h * (h + x)+ 4 * b
LSTM------只取hn 以及双向处理
实际上就是把之前的模型simpleRNN 直接进行修改成LSTM即可,还是很简单的。
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
# 准备数据 karas自带的数据集imdb,电影分类,分电影是积极的,还是消极的
# -----------------------------------------------------------------------------
imdb = keras.datasets.imdb
vocab_size = 10000
index_from = 3
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = vocab_size, index_from = index_from)
word_index = imdb.get_word_index()
word_index = {key:value+index_from for key, value in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2
word_index['<END>'] = 3
reverse_word_index = {value:key for key,value in word_index.items()}
max_length = 500
train_data = keras.preprocessing.sequence.pad_sequences(train_data,value = word_index['<PAD>'],padding = 'post',maxlen = max_length)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,value = word_index['<PAD>'],padding = 'post',maxlen = max_length)
# -----------------------------------------------------------------------------
# 模型搭建 主要的变化就是加了一层RNN
# -----------------------------------------------------------------------------
embedding_dim = 16
batch_size = 512
#相对于之前主要改的是这里
single_lstm_model = keras.models.Sequential([
keras.layers.Embedding(vocab_size, embedding_dim, input_length = max_length),
# return_sequences是返回输出序列中的最后一个输出还是完整序列,False就是返回最后一个,如果等于True就是返回一整个序列,也就是h1,h2···hn
# 只有这边进行了修改,双向的多层lstm结构
keras.layers.Bidirectional(
keras.layers.LSTM(
units = 64, return_sequences = True)),
keras.layers.Bidirectional(
keras.layers.LSTM(
units = 64, return_sequences = False)),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
# 这边的RNN的计算参数:h*(h+x)+b(也就是h) = 64*(16+64)+64
# 然后这边没有对于embedding进行全局池化,原因是经过RNN之后,实际上降维了,原因可以认为就是我们上面的return_sequences=false,导致输入的原本是500个有序单词,但是输出的是一个单词,或者可以理解只有尾部的一个变量,这边就自然降维了
single_lstm_model.summary()
single_lstm_model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# -----------------------------------------------------------------------------
# 训练和模型评估
# -----------------------------------------------------------------------------
# 我们这里和之前不一样,没有验证集,所以分20%给验证集
history_single_lstm = single_lstm_model.fit(train_data, train_labels, epochs = 30, batch_size = batch_size,validation_split = 0.2)
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
plot_learning_curves(history_single_lstm, 'accuracy', 30, 0, 1)
plot_learning_curves(history_single_lstm, 'loss', 30, 0, 1)
single_lstm_model.evaluate(test_data, test_labels,batch_size = batch_size,verbose = 0)
# -----------------------------------------------------------------------------
输出:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 500, 16) 160000
bidirectional (Bidirection (None, 500, 128) 41472
al)
bidirectional_1 (Bidirecti (None, 128) 98816
onal)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 308609 (1.18 MB)
Trainable params: 308609 (1.18 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/30
40/40 [==============================] - 33s 324ms/step - loss: 0.6527 - accuracy: 0.5879 - val_loss: 0.5857 - val_accuracy: 0.7124
······
Epoch 30/30
40/40 [==============================] - 8s 206ms/step - loss: 0.0402 - accuracy: 0.9868 - val_loss: 0.6438 - val_accuracy: 0.8732
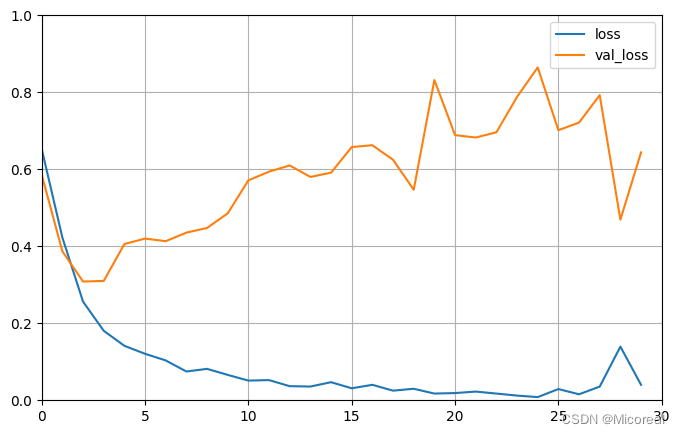
图片1
图片2
[0.7835259437561035, 0.8441200256347656]
图片1:
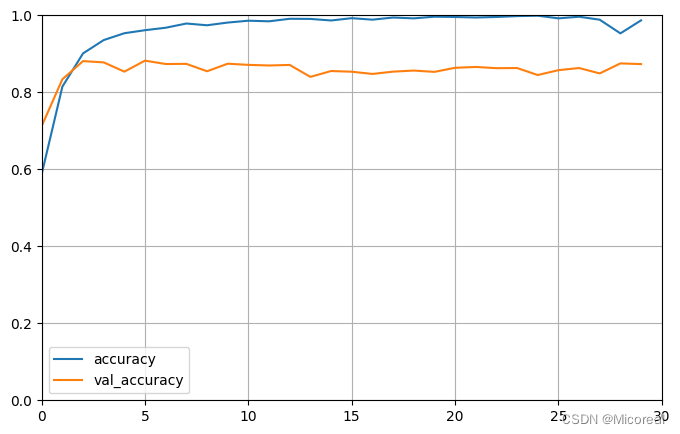
图片2:
RNN的改进
stack改进
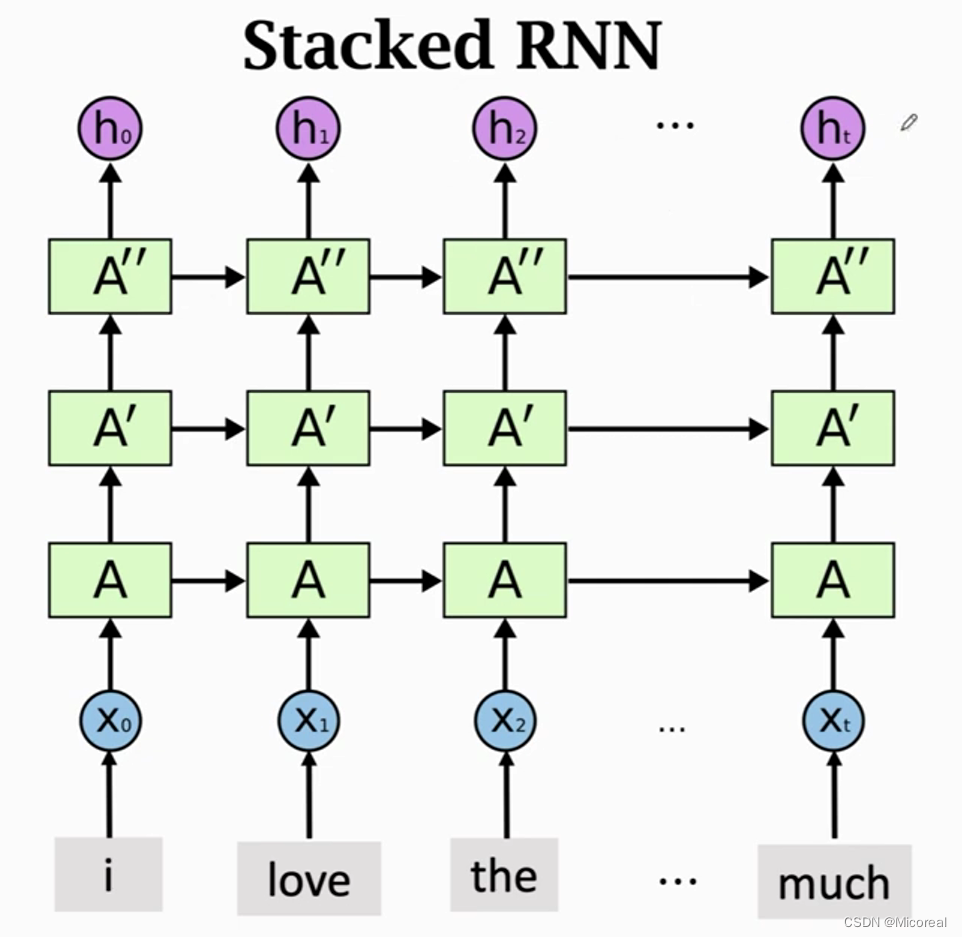
多层RNN
代码实现就是多层叠加使用,然后上一层的return_sequence打开。
Bidirectional 改进
双向改进
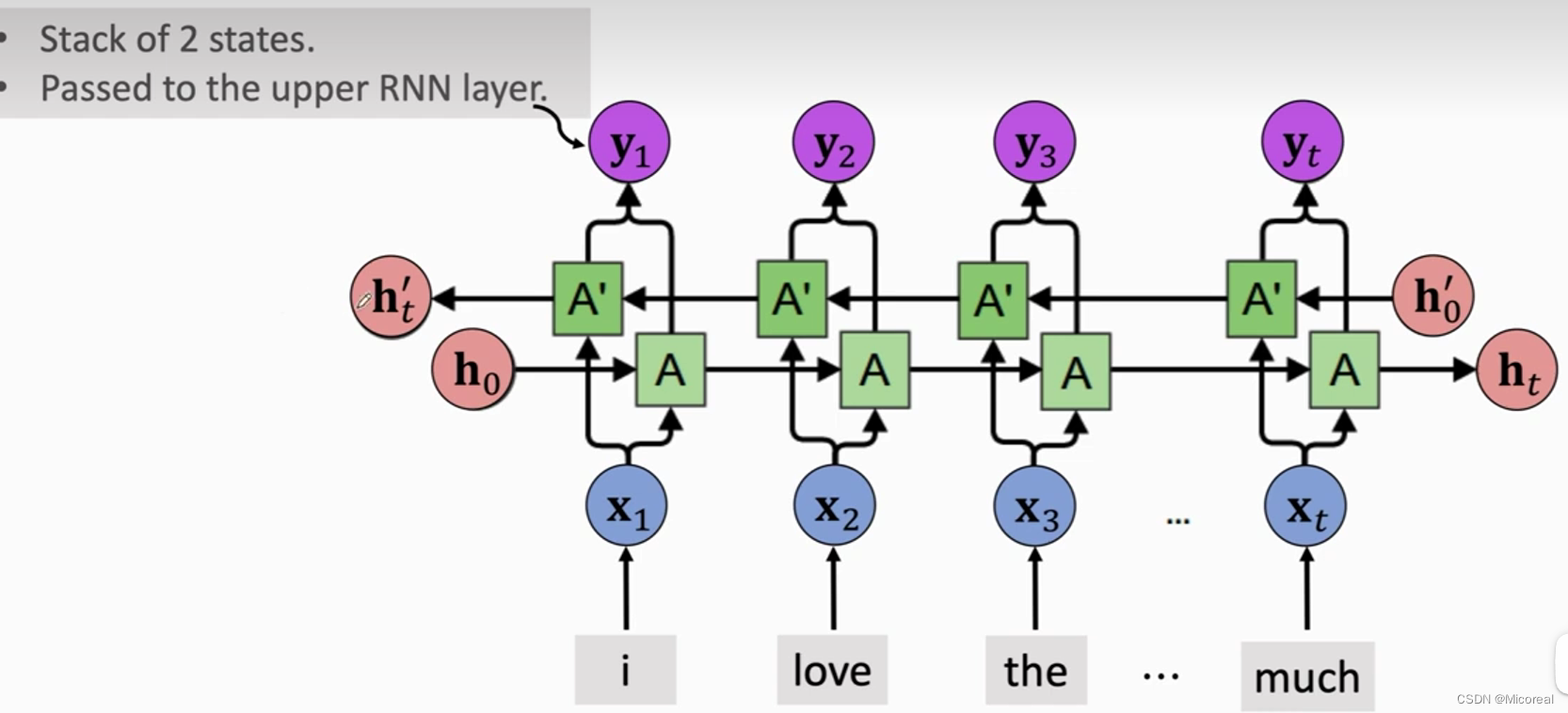
这边原理也很简单,不细说,看图自然也可以明白
embedding改进
看了之前我们的预测,我们都会发现为什么准确率什么的这么低,原因主要就是我们的embedding的参数好几百万,但是我们输入进去的数据量只有2万,明显会有一个over fitting,这边如何进行改进呢?方法就是自己去找一个新的任务,数据量要大,里面也要拥有embedding层,然后两种任务越相似,之后的效果也会越好,我们那那个大数据训练出来的model加载到我们的模型当中,然后把embedding之后的所有层丢掉,还有就是把embedding层之前的所有层参数冻结,之后基于这个embedding进行迁移学习,也可以说是fine-tune。














 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









