






【目标检测】在近年来的深度学习领域中备受关注,它通过识别和定位图像中的目标对象,提升了模型在图像理解和分析方面的能力。目标检测技术在自动驾驶、安防监控和医疗影像分析等任务中取得了显著成果。其独特的方法和卓越的表现使其成为研究热点之一。
为了帮助大家全面掌握目标检测的方法并寻找创新点,本文总结了最近两年【目标检测】相关的20篇顶会论文的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望能为各位的研究工作提供有价值的参考。
需要的同学扫码添加我
回复“目标检测20”即可全部领取

1、Learning Background Prompts to Discover Implicit Knowledge for Open Vocabulary Object Detection
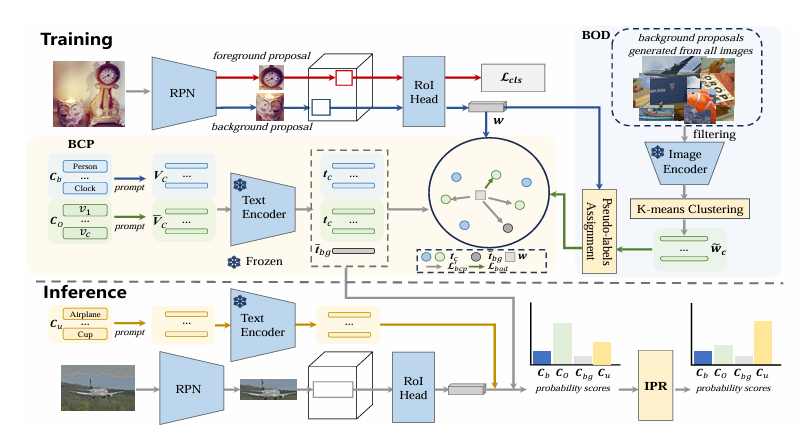
-这篇文章介绍了一种名为LBP(Learning Background Prompts)的新型框架,旨在提升开放词汇表目标检测(Open Vocabulary Object Detection, OVD)的性能。OVD的目标是设计一种能够同时识别基础类别和新类别(即在训练数据中未见过的类别)的最优目标检测器。文章指出,现有的OVD方法在背景解释和模型过拟合方面面临重大挑战,导致关键的背景知识丢失,从而影响检测器的推理性能。
-为了解决这些问题,文章提出了LBP框架,通过学习背景提示(background prompts)来利用隐含的背景知识,从而增强对基础和新类别的检测性能。具体来说,LBP框架由三个模块组成:背景类别特定提示(Background Category-specific Prompt, BCP)、背景目标发现(Background Object Discovery, BOD)和推理概率校正(Inference Probability Rectification, IPR)。BCP模块利用可学习的类别特定上下文来发现并表示从背景提议中估计出的背景潜在类别,从而改善背景解释。BOD模块进一步探索并利用与这些估计出的潜在类别相关的隐含对象知识,有助于减少模型对基础类别的偏见。IPR模块则解决在推理过程中估计的背景类别和新类别之间的概念重叠问题,使模型能够为新类别准确计算概率,显著提升检测器性能。
-文章通过在两个基准数据集OV-COCO和OV-LVIS上的评估,展示了所提出方法相较于现有最先进方法在处理OVD任务上的优越性。此外,文章还进行了消融研究,以评估每个单独模块对整体性能的影响。实验结果表明,BCP、BOD和IPR这三个模块共同作用,显著提升了模型在检测新类别方面的表现,并且通过调整背景解释策略,模型能够更好地区分和识别未知类别的对象。
-文章还探讨了不同超参数的选择对模型性能的影响,包括背景类别扩展的数量、背景损失的阈值以及背景提议的损失权重。这些分析有助于读者理解模型的不同组件是如何协同工作以及如何通过调整参数来优化模型性能的。
-最后,文章总结了LBP框架的主要贡献,并指出了其在实际应用中的潜力。通过学习背景提示,LBP框架不仅提升了对未知类别的检测能力,还增强了模型对多样化场景的适用性,为开放词汇表目标检测领域提供了一种有效的解决方案。
2、Multi-View Attentive Contextualization for Multi-View 3D Object Detection
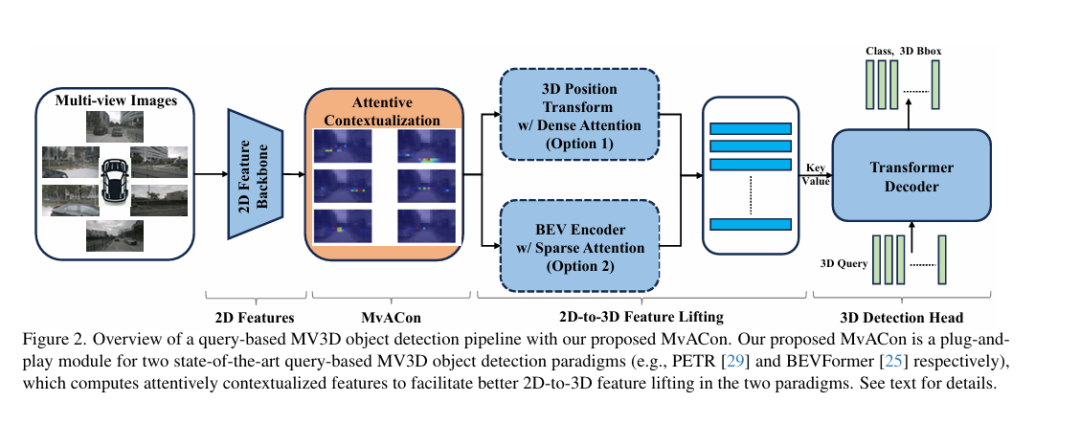
-这篇文章介绍了一种名为Multi-View Attentive Contextualization(MvACon)的新方法,旨在提升基于查询的多视图3D(MV3D)目标检测中的2D到3D特征提升。MvACon通过一种在表示上密集但计算上稀疏的注意力特征上下文化方案,解决了现有方法在密集注意力提升中未能充分利用高分辨率2D特征或在稀疏注意力提升中3D查询与多尺度2D特征结合不足的问题。
-文章首先概述了基于相机的3D目标检测的重要性,尤其是在自动驾驶和机器人自主性等成本效益高的自主系统中。尽管MV3D目标检测领域取得了显著进展,但现有方法仍存在局限性,尤其是在多视图特征聚合策略和Transformer设计中的计算成本或3D信息意识有限。为了解决这些问题,作者提出了MvACon,它通过聚类注意力操作来上下文化原始特征图,增强了2D到3D特征提升的性能。
-MvACon的核心思想是通过聚类注意力机制来提升2D特征,使其能够更好地与3D空间中的锚点进行交互。在PETR(一种基于视角的解码器和检测器)中,MvACon在特征图输入到解码器之前进行上下文化处理;对于基于编码器-解码器的检测器,如BEVFormer和DFA3D,MvACon则在空间交叉注意力操作中集成了聚类上下文化。实验结果表明,MvACon通过编码更有用的上下文,有效地提高了基于查询的MV3D目标检测器的性能,尤其是在位置、方向和速度预测方面。
-文章还进行了消融研究,探讨了不同上下文方法对检测性能的影响,以及局部上下文和全局聚类上下文之间的关系。实验结果表明,全局聚类上下文在特征编码中发挥了补充作用,显著提高了位置、方向和速度预测的准确性。
-此外,文章还展示了MvACon在NuScenes基准测试中的有效性,使用BEVFormer及其3D变形注意力(DFA3D)变体,以及PETR,显示出一致的检测性能提升。在Waymo-mini基准测试中也观察到了类似的改进。文章通过定性和定量的方式展示了全局聚类上下文如何有效地为MV3D目标检测编码密集的场景级上下文。
-最后,文章总结了MvACon的主要贡献:分析并解决了现有2D到3D特征提升的局限性,提出了一种易于集成的方法来增强MV3D目标检测器的3D表征能力,并通过在具有挑战性的数据集上的性能提升验证了其有效性。作者还感谢了支持这项研究的资金来源,并声明了研究观点和结论仅代表作者自身,并不一定代表相关机构的官方政策或认可。
需要的同学扫码添加我
回复“目标检测20”即可全部领取
3、DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
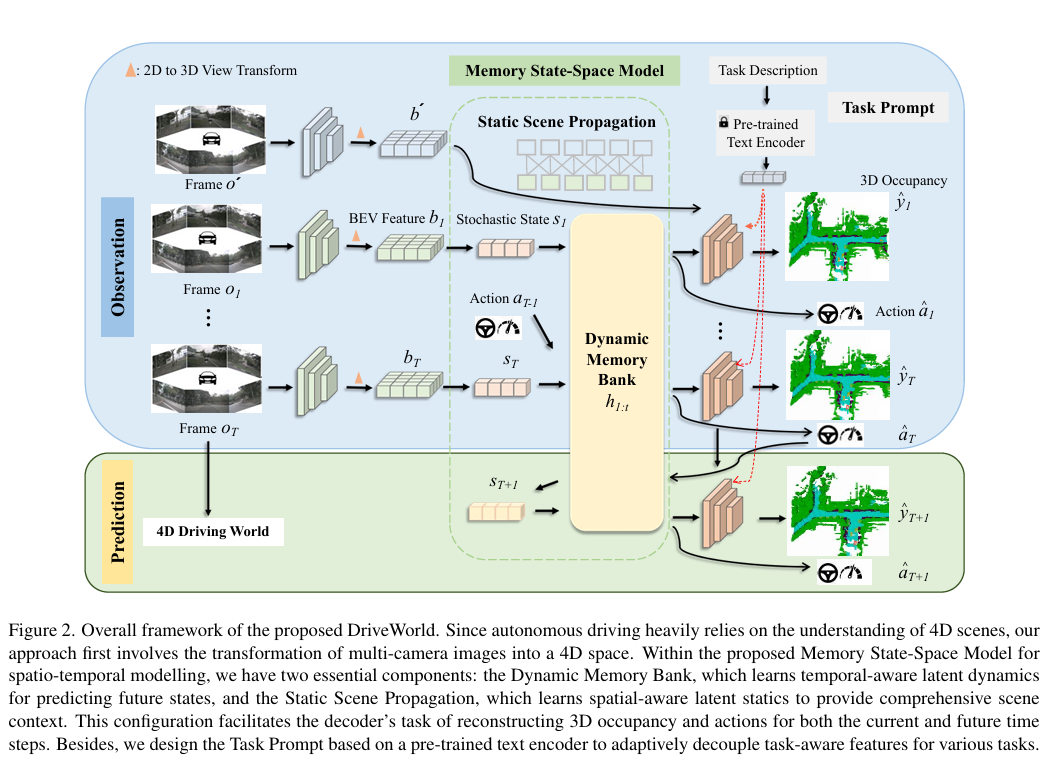
-这篇文章提出了一个名为DriveWorld的新型4D预训练场景理解框架,旨在提升自动驾驶中的视觉中心化方法。该框架通过一个基于世界模型的方法,从多摄像头驾驶视频中进行时空预训练,以学习一个能够理解四维场景的紧凑表示。
-文章首先指出,尽管基于视觉的自动驾驶因其低成本而受到广泛关注,但现有的视觉中心化预训练方法大多依赖于2D或3D的预训练任务,忽略了自动驾驶作为4D场景理解任务的时间特性。为了解决这一挑战,作者提出了一个基于世界模型的4D表示学习框架,DriveWorld,它能够在时空上进行多摄像头驾驶视频的预训练。
-DriveWorld框架的核心是记忆状态空间模型(Memory State-Space Model),该模型包含动态记忆库(Dynamic Memory Bank)模块和静态场景传播(Static Scene Propagation)模块。动态记忆库模块用于学习时间感知的潜在动态,以预测未来的变更;静态场景传播模块则用于学习空间感知的潜在静态特征,提供全面的场景上下文。此外,文章还引入了一个任务提示(Task Prompt)机制,用于为不同的下游任务解耦任务感知特征。
-在实验部分,作者展示了DriveWorld在各种自动驾驶任务上的承诺结果。当使用OpenScene数据集进行预训练时,DriveWorld在3D目标检测、在线映射、多目标跟踪、运动预测、占用预测和规划等任务上都取得了显著的性能提升。具体来说,与2D ImageNet预训练、3D占用预训练和知识蒸馏算法相比,DriveWorld在3D目标检测的mAP上提高了7.5%,在在线映射的IoU上提高了3.0%,在多目标跟踪的AMOTA上提高了5.0%,在运动预测的minADE上降低了0.1m,在占用预测的IoU上提高了3.0%,在规划的平均L2误差上减少了0.34m。
-文章还进行了消融研究,验证了DriveWorld中记忆状态空间模型(MSSM)模块的有效性。结果表明,与基于RNN的循环状态空间模型(RSSM)相比,MSSM在3D检测性能上有显著提升。此外,通过引入运动感知层归一化(Motion-aware Layer Normalization, MLN)和任务提示,模型在各项感知任务上都取得了进一步的改进。
-最后,文章讨论了DriveWorld的局限性和未来的工作方向。目前,DriveWorld的注释仍然基于激光雷达点云,未来需要探索视觉中心化预训练的自监督学习。此外,DriveWorld的有效性仅在轻量级的ResNet101骨干网络上得到了验证,未来值得考虑扩大数据集和骨干网络的规模。作者希望提出的4D预训练方法能够为自动驾驶基础模型的发展做出贡献。
需要的同学扫码添加我
回复“目标检测20”即可全部领取















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









