






一、Nunchaku介绍
今天继续分享一个超级给力的新玩意 Nunchaku,让你的出图速度快到不可思议,比以前说的TeaCache厉害多了。
Nunchaku 是由 MIT Han Lab 开发的 4位扩散模型高效推理引擎,专为优化生成式模型(如Stable Diffusion)的推理速度和显存占用设计。结合 SVDQuant量化技术,它在保持生成质量的同时显著提升性能。

技术优势
显存优化:相比传统BF16模型,显存占用减少 3.6倍(例如16GB显存设备可运行更大模型)。
速度提升:在16GB显存设备上,推理速度比16位模型快 8.7倍,比传统4位量化(NF4 W4A16)快 3倍。
无损生成:通过低秩分解和核融合技术,4位量化模型生成质量与原始模型几乎无差异(参考官方对比图)。
兼容性:支持Flux模型生态、Redux、Lora、ControlNet及多显卡架构(NVIDIA Ampere/Ada/A100)。
官网地址:https://github.com/mit-han-lab/nunchaku
相关安装
插件地址:https://github.com/mit-han-lab/ComfyUI-nunchaku
节点管理器里面搜ComfyUI-nunchaku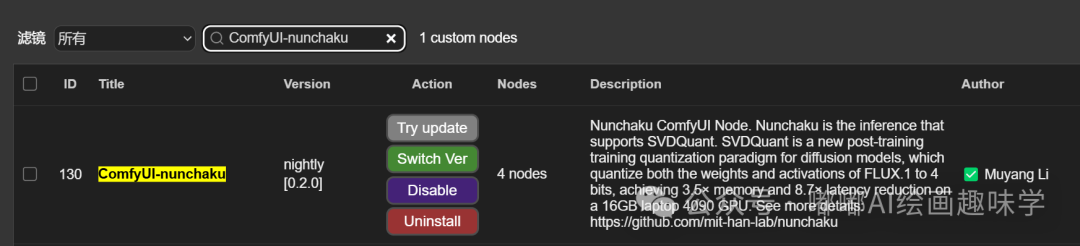
模型下载地址 https://huggingface.co/mit-han-lab
这里包含了很多模型,不过我们主要用的就2个
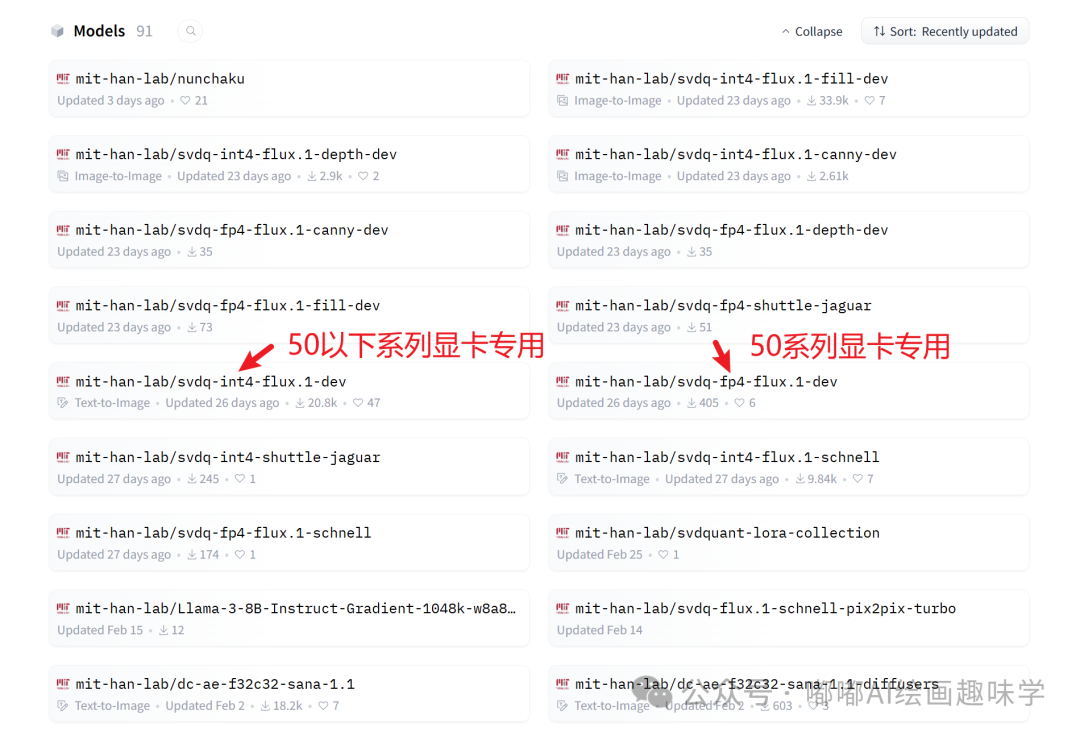
svdq-int4-flux.1-dev` 和 `svdq-int4-flux.1-fill-dev
如果你是50系列显卡,那就下载fp4这个名称的,不然就和我一样下载int4的就行。
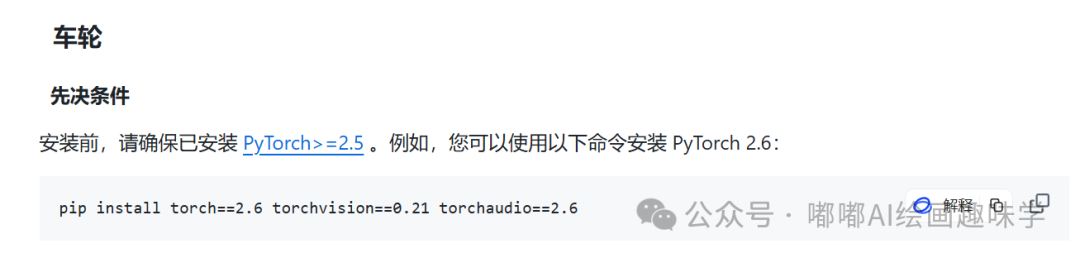
要想使用上 nunchaku 这个加速技术,对版本依赖有要求
官网有要求必须PyTorch>=2.5才行
如何看自己本地安装的ComfyUI PyTorch版本呢,一般启动的时候系统打印的信息里面会带,比如下面这样
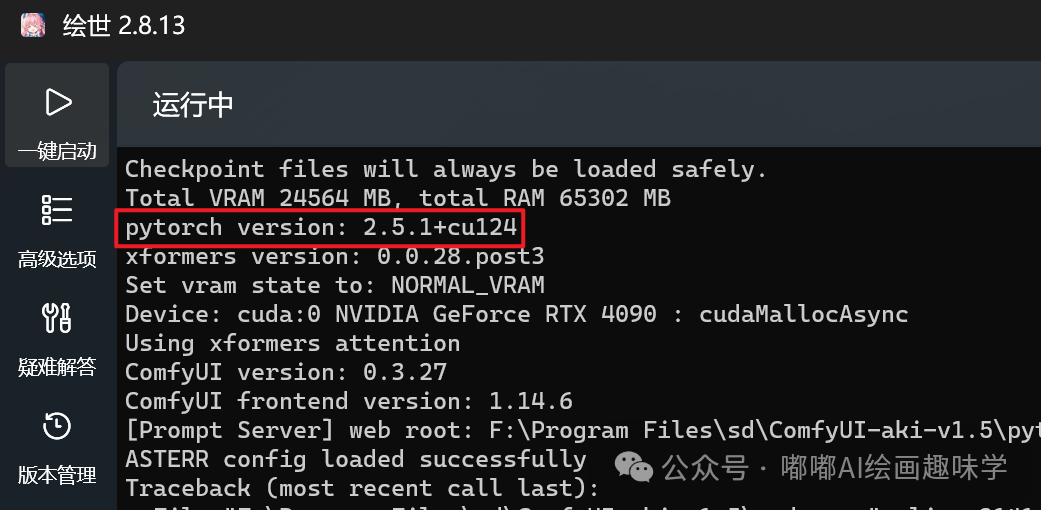
我之前是2.4.1+cu124,所以就升级到2.5.1+cu124了。
安装 PyTorch 是要配套的,我是本地安装秋叶整合版,这里有介绍匹配的依赖版本。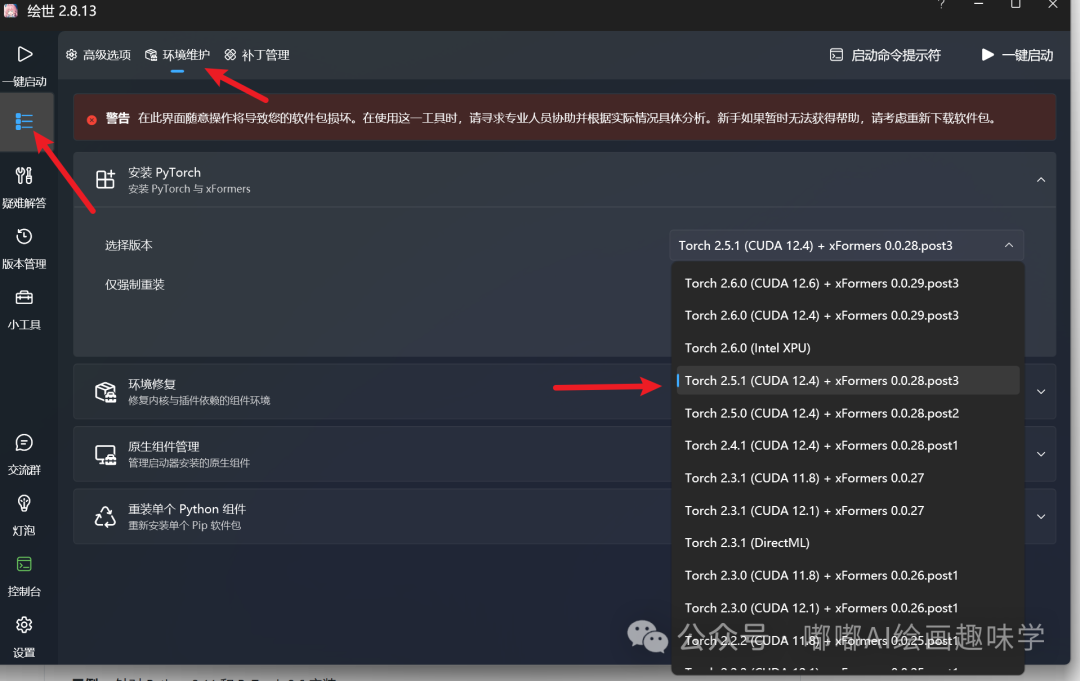
CUDA驱动就不用说了,一开始大家都安装了,一般安装12.4就够了。
Torch以及Xformers我是通过命令执行的,我这里也分享下我升级Torch到2.5.1的命令。
步骤一:卸载旧的
pip uninstall torch torchvision torchaudio
步骤二:安装对应版本
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
步骤三:安装xformers
pip uninstall xformers
python.exe -m pip install xformers==0.0.28.post3 --pre --extra-index-url https://download.pytorch.org/whl/cu124
依赖升级好了后,就要开始配套的安装轮子,这里需要安装nunchaku这个依赖库。
轮子配套文件:https://huggingface.co/mit-han-lab/nunchaku/tree/main
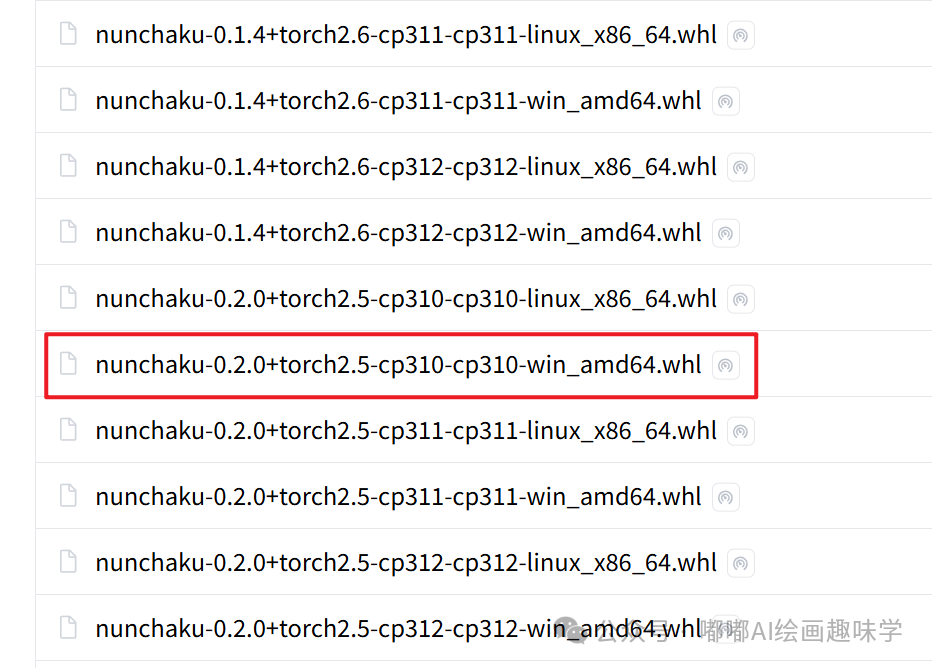
这里有好多版本,需要大家根据自己本地情况下载指定的
比如我本地torch是2.5.1,那就是对应torch 2.5 然后我python是3.10,就对应cp310 最终我要下载的就是 nunchaku-0.2.0+torch2.5-cp310-cp310-win_amd64.whl这个轮子
下载好了之后,我丢到ComfyUI对应的python目录下。
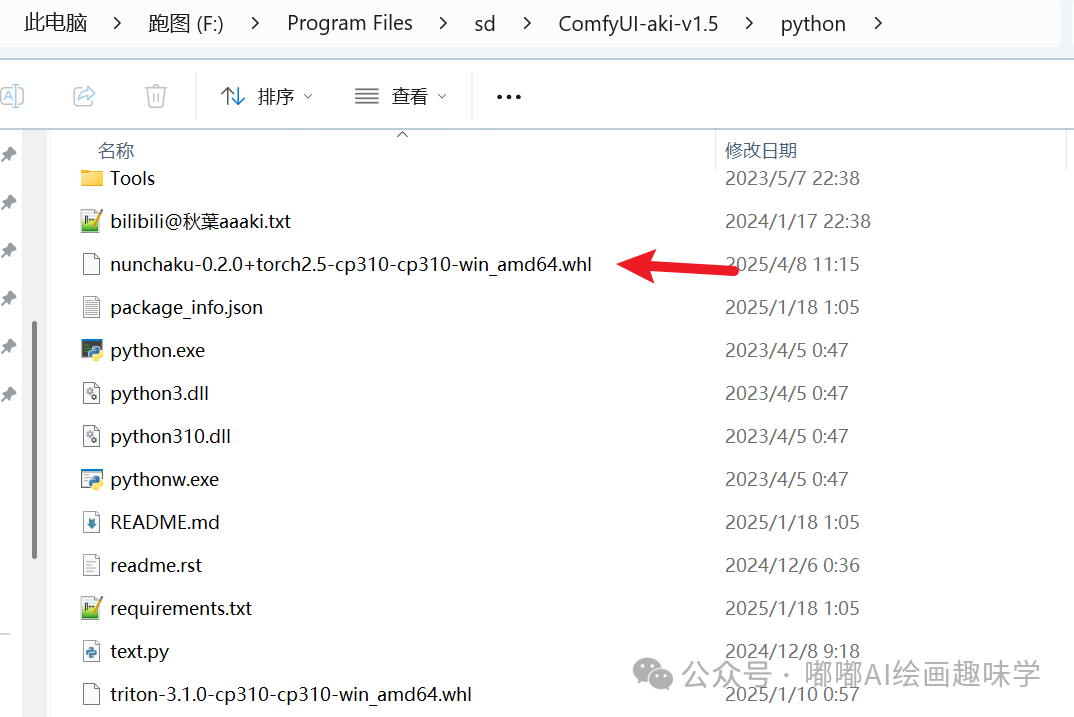
然后打开对应的CMD路径,输入下面安装命令,就能安装上这个依赖了。
python.exe -m pip install nunchaku-0.2.0+torch2.5-cp310-cp310-win_amd64.whl
以上,基本环境就搞定了。
三、使用说明
RH在线体验:https://www.runninghub.cn/post/1909977345107918850?utm_source=1c704ef9
要使用这个新技术,工作流变化其实不大,就加载模型的换一下而已,完整文生图工作流如下
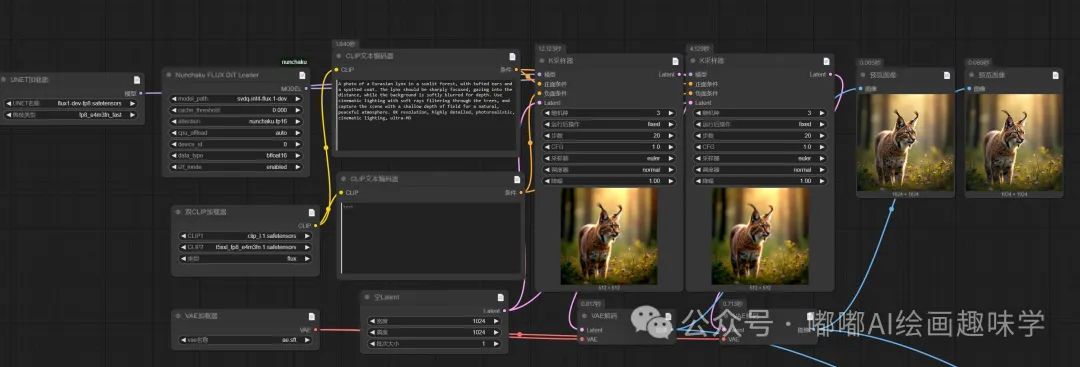
看下图,这个就是唯一的区别点了,以前用的是UENT加载器,现在该用Numchaku Flux DiT Loader
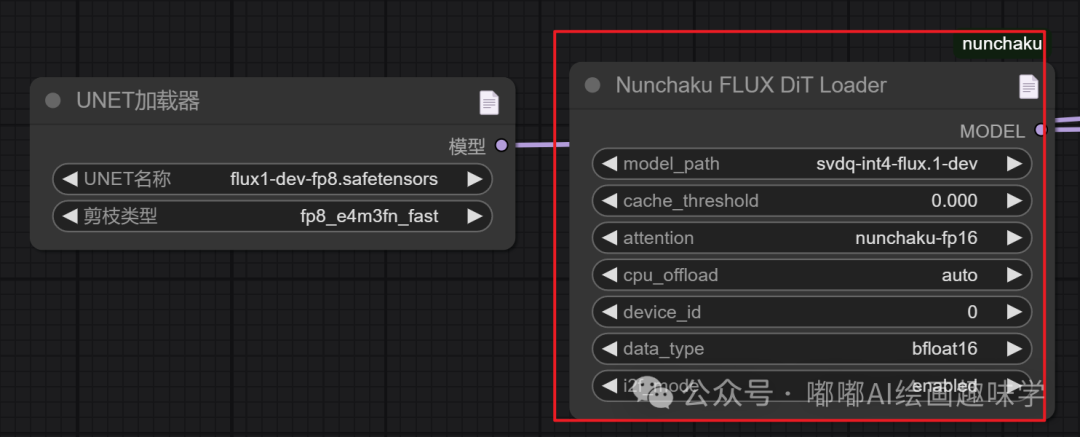
参数说明
- cache_threshold :控制首块缓存容差,类似于 WaveSpeed 中的 residual_diff_threshold 。增加此值可提高速度,但可能会降低质量。典型值为 0.12。将其设置为 0 可禁用该效果。
- attention :定义注意力实现方法。您可以选择 flash-attention2 或 nunchaku-fp16 。我们的 nunchaku-fp16 比 flash-attention2 快约 1.2 倍,且不影响精度。对于不支持 flash-attention2 的 Turing GPU(20 系列),您必须使用 nunchaku-fp16 。
- cpu_offload :为 Transformer 模型启用 CPU 卸载。虽然这会减少 GPU 内存使用量,但可能会减慢推理速度。当设置为 auto 时,它将自动检测您的可用 GPU 内存。如果您的 GPU 内存超过 14GiB,则卸载将被禁用。否则,它将被启用。
- device_id :运行模型的 GPU ID。
- data_type :定义反量化张量的数据类型。Turing GPU(20 系列)不支持 bfloat16 ,只能使用 float16。
- i2f_mode :对于 Turing(20 系列)GPU,此选项控制 GEMM 实现模式。 enabled 和 always 模式略有不同。其他 GPU 架构会忽略此选项。
文生图
来看看跑的效果,一方面看速度差距啊,一方面看出图对比
An elegant, art deco-style cat with sleek, geometric fur patterns reclining next to a polished sign that reads 'MIT HAN Lab' in bold, stylized typography. The sign, framed in gold and silver, exudes a sophisticated, 1920s flair, with ambient light casting a warm glow around it.
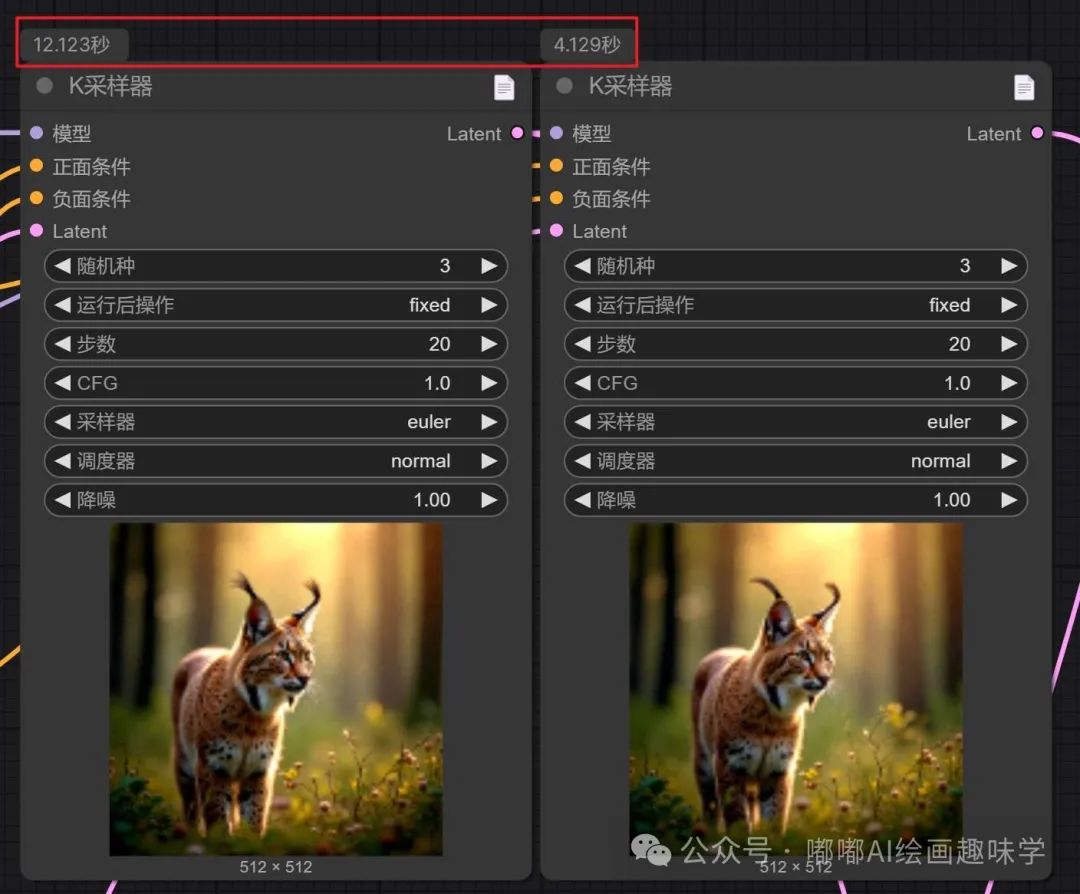
左边是Flux默认的流用了Flux-dev-fp8模型,右边是用上了 Nunchaku后,模型这里的是 svdq-int4-flux.1-dev,其他参数保持一致。 初速时间差距有3倍,分別12秒和4秒。
另外Flux fp8模型我显存用了16G,而用了int4的话,显存只用了12G。
可以看到图片质量差距不大。

Realistic Skin,AJFCY,A beautifully styled portrait featuring a character in a stunning,intricately embroidered white cheongsam,showcasing elegance and traditional charm. The dress is adorned with delicate floral patterns and sequins,reflecting light and adding a luxurious touch. The background features a soft-focus wooden lattice design,creating depth and a cultural ambiance. The lighting is warm and natural,enhancing the texture of the fabric and the intricate details of the outfit. The character poses gracefully with one hand gently holding part of the dress,displaying a poised and confident expression. Accessories include floral hairpins and earrings that complement the outfit,further enhancing the overall aesthetic,closed mouth,Detailed hand,Detailed feet,posing,detailed image,perfection style,

Cozy bedroom with vintage wooden furniture and a large circular window covered in lush green vines, opening to a misty forest. Soft, ambient lighting highlights the bed with crumpled blankets, a bookshelf, and a desk. The atmosphere is serene and natural. 8K resolution, highly detailed, photorealistic, cinematic lighting, ultra-HD.

从这三张图片对比可以看到,图片质量没有降低,但是速度缺提升了数倍,显存使用也更少了,这就是这个新技术的厉害之处。
Fill模型测试
我们来试试其他模型,比如Fill模型 我拿一个基本的扩图来测试
原图:

效果图对比
full-fill-dev:显存占用15.4G,出图42秒
svdq-int4-flux.1-fill-dev:显存占用12G,出图时间20秒
出图画质差距微乎其微,但是显存和出图时间差距很大,真香。
再来试试局部重绘的
原图

效果图
完美,太强了,以后要用Fill模型,直接用这个int4版本的就好了,显存占用地,效果还一样。
Controlent、lora支持
目前 Nunchaku 也已经支持了lora支持,直接用Flux的lora就行
在大模型加载器后面接入 Nunchaku FLUX.1 LoRA Loader 这个节点即可。
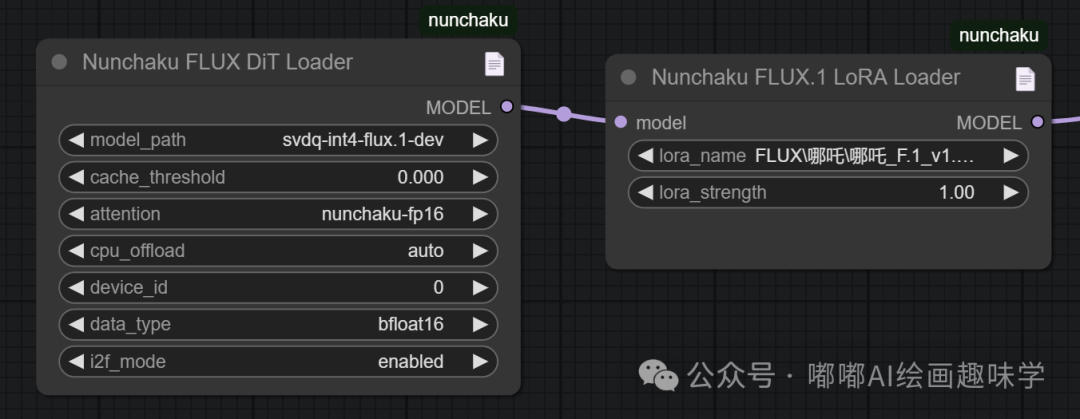
下面是我以前测试哪吒的lora,出的图也很完美。
Nezha, a digital computer-generated image of a young anime-style boy with black hair tied into twin buns, red eyes, and a mischievous smile. There is a red forehead mark.
He is wearing a pink trench coat and walking on a fashionable catwalk with the Paris Fashion Week stage in the background and the audience sitting around him

Controlent目前也是支持的,可以直接用以前的

Redux支持
目前最新的版本我看也已经支持了Redux了,相当不错 我来试试万物迁移工作流看看效果
在原来万物迁移工作流上就修改了下模型,其他保持不变。
下面是跑的两组案例测试
- 原Fill模型,跑图费时42秒,显存占用20G
- int4版本模型 跑图费时19秒,显存占用14G


RH平台
推荐不想本地自己折腾的同学一个可在线使用Runninghub平台可在线体验AI应用和工作流(注册即送1000积分可用)。
注册地址:https://www.runninghub.cn/?inviteCode=1c704ef9

四、总结
以上就是今天的加速神器 Nunchaku 的测评了,这是我目前用过出图最快的加速技术了,质量几乎无损,速度又快,应该会作为我后期常用的模型了,大家用起来,必备技能之一。
AI时代,值得我们去投入时间研究。
技术的迭代是飞快的,要关注最新的消息才不会掉队。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









