






Nunchaku 的4位量化发布极大的友好于Flux生态的使用,使低显存用户也能享受到满血蛮的Flux出图质量,而且速度极快,同时对于Flux的生态支持也很好,像 lora、fill等模型也全部支持;但是官方发布的量化lora有限,遇到喜欢的lora我们应该如何结合Flux量化模型使用,官方也给出了转换的方法,作者自己也试了下,十分简单,分享记录下作者的实操过程。
选择想要的lora
===
选择一款喜欢的lora,选择的是一款让物体爆裂效果的lora;
官网效果如图:
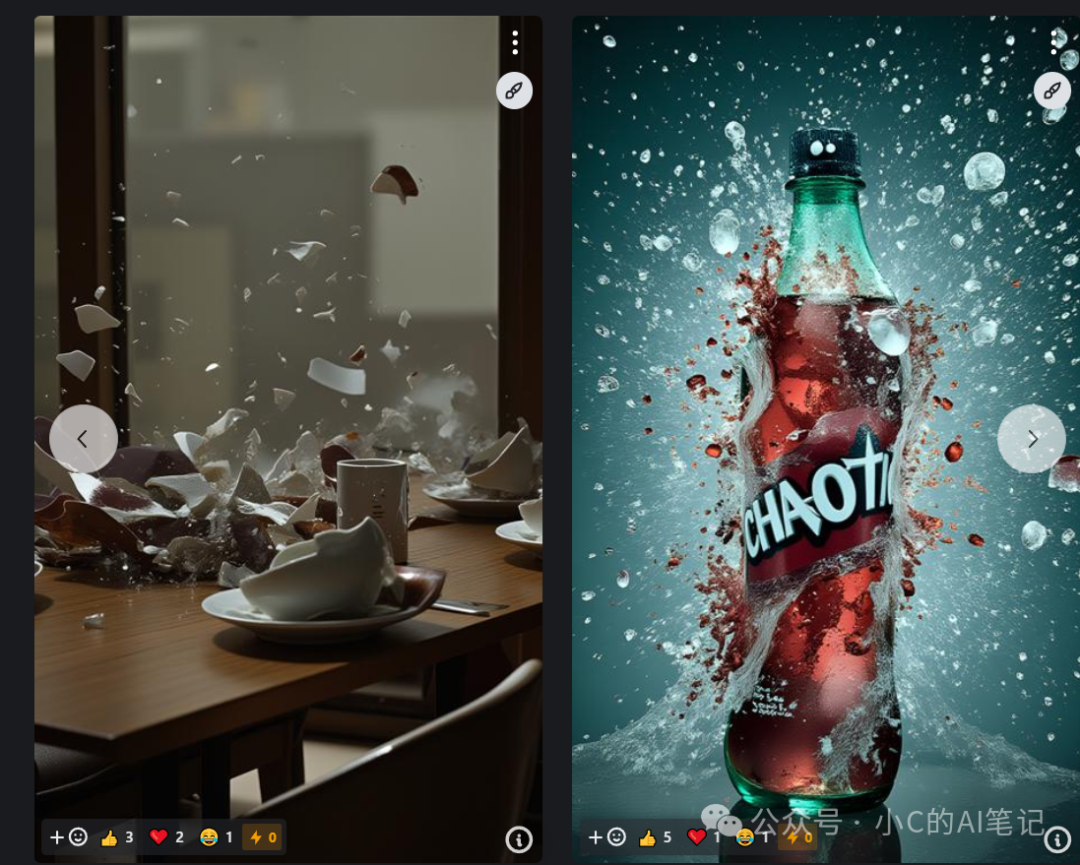
下载后放入本地;

新建一个文件夹 nunchaku_loras用于存放量化后的lora
然后再终端执行命令
E:\ComfyUI_windows_portable_nvidia\python_embeded\python.exe -m nunchaku.lora.flux.convert –quant-path F:\comfyui-portable-nfc1.1-windows\ComfyUI\models\diffusion_models\mit-han-lab\svdq-int4-flux.1-dev\transformer_blocks.safetensors –lora-path .\flux_lora_v1_boom.safetensors –output-root ./nunchaku_loras –lora-name svdq-int4-flux-boom
参数解释:
quant-path : 你lora需要使用的主模型的存放地址,` `这里我们是要用于 svdq-int4-flux.1-dev 模型`` ``lora-path : 你需要转换的lora地址`` ``output-root:转换后的存放地址`` ``lora-name: 转换后的lora的名字
直接执行此命令即可,执行速度还蛮快的;
出现这个说明执行完成了
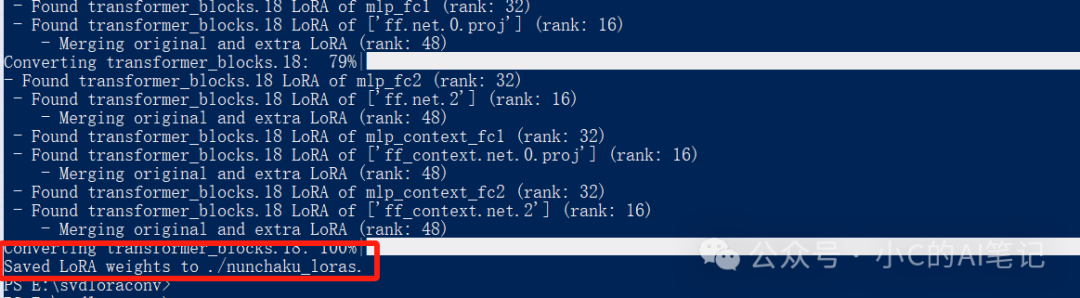
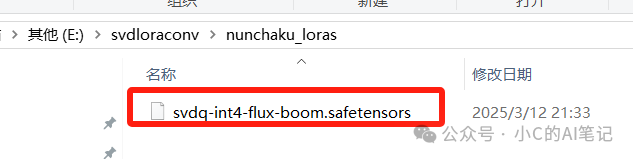
执行完成后;在之前的 output-root 目录会出转换后的lora就说明转换完成了
使用对比
===
我们将转换前的原始lora和转换后的做一下对比
转换前的虽然能够正常生成图像,但是lora的效果无法体现出来
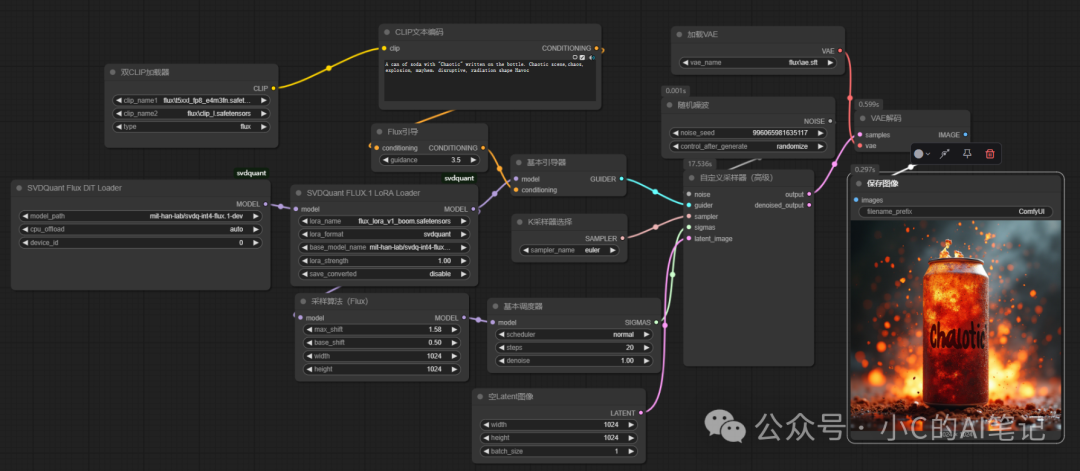

使用转换后的 lora 效果就出来了 如下:
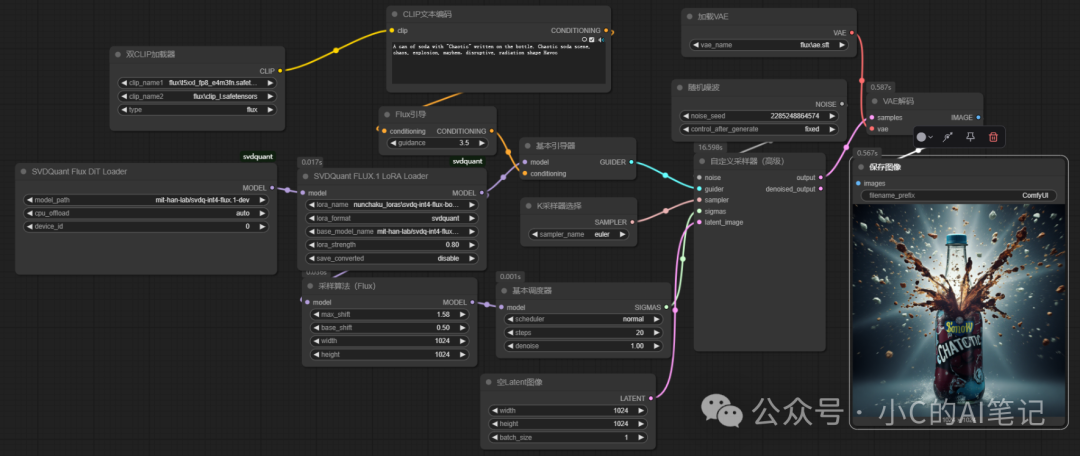


===
总结
===
以上就是Flux lora 量化的全过程了,快去使用自己喜欢的Lora吧!
注意:在使用lora后,如果不在使用lora需要手动点击

这两个图标将lora释放,不然会一直生效;这个bug官方已在修复中了;
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









