







TensorRT工作流程

如上图所示,是一个从摄像头获取视频流并使用TensorRT加速推理的一个过程,下面大致对上图进行讲解。
1.首先要获得一个TensorRT支持的模型格式,TensorRT支持uff、onnx、caffee三种格式。
2.工作流程图中使用转好的uff格式的模型构建TensorRT Engine,有两种构建方式,一种使用TensorRT自带的工具trtexec,另一种使用TensorRT的C++和python的API接口用于构建。
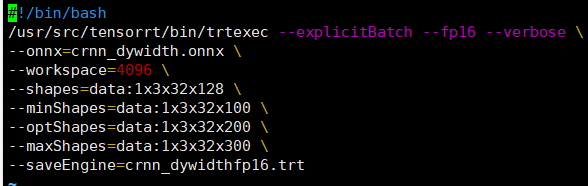
TensorRT自带的工具trtexec,例子如下,将onnx模型转为trt:
python API
# The Onnx path is used for Onnx models.
def build_engine_onnx(model_file):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(common.EXPLICIT_BATCH) as network,\
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = common.GiB(1)
# Load the Onnx model and parse it in order to populate the TensorRT network.
with open(model_file, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
return builder.build_cuda_engine(network)
3.得到Engine后,就可以使用Engine进行推理。
下面这些函数在TensorRT的sample都有详细的介绍,文尾会附上链接。
首先得到engine,然后创建运行环境context,然后使用allocate_buffers()函数分配内存,在调用do_inference进行推理。
对于分配内存的理解:在主机和jetson设备上分配同样大小内存的input和output。input在此文中是输入的图片大小*batch_size,然后将主机的输入拷贝到jeston设备种,调用do_inference获得output,其大小为网络推理的输出大小,为一维的numpy数组,然后将output从jetson设备中拷贝到主机内存。
注:inputs[0].host和trt_outputs都是numpy数组。
with build_engine_onnx(onnx_model_file) as engine, engine.create_execution_context() as context:
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
print('Running inference on image {}...'.format(input_img_path))
inputs[0].host = img
trt_outputs = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
allocate_buffers
# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
do_inference
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
4.需要对得到的网络的输出进行后处理,具体根据网络来决定。
参考链接:
https://docs.nvidia.com/deeplearning/tensorrt/sample-support-guide/index.html
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html
https://github.com/NVIDIA/TensorRT
https://developer.nvidia.com/zh-cn/tensorrt
https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/gettingStarted.html















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









