







上一讲讲到userCF算法,该算法是根据用户之间相似度,来给目标用户推荐与他们相似用户产生过行为的物品。该算法在某些应用场景并不适用。首先随着网站用户数目越来越大,计算用户兴趣相似矩阵越来越困难,运算时间复杂度和空间复杂度和用户增长近似于平方关系。其次,基于用户的协同过滤很难对推荐结果作出解释。
由此产生了基于物品的协同过滤(itemCF)给用户推荐和他们之前喜欢的物品相似的物品。不过ItemCF算法不是根据物品内容属性计算物品之间相似度,它主要通过分析用户的行为记录来计算物品之间的相似度。
基于物品的协同过滤算法主要分为两步。
①:计算物品之间的相似度
②:根据物品之间相似度和用户的历史行为给用户生产推荐列表。
根据定义可以用以下公式计算物品相似度:

N(i)表示喜欢物品i的用户列表,N(j)表示喜欢物品j的用户列表。上述公式可以理解成喜欢物品i的用户里有多少喜欢物品j。
但是有一个问题,如果物品j是个热门物品呢?大家都喜欢。那么上面公式岂不是接近1?因此该公式会造成任何物品都和热门物品有很大的相似性,对于致力于挖掘长尾信息来说不是一件好特性。为避免推荐出热门物品可以用下面公式:
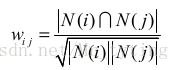
上面公式惩罚了物品j的权重,因此减轻了热门物品和很多物品的相似性。
在实际计算物品相似度时,先建立用户—>物品的倒排表(即对每个用户建立一个包含他喜欢的物品列表),然后对于每个用户,将它的物品列表里面的物品两两在共现矩阵C中加1。
得到物品相似度以后,ItemCF通过如下公式计算用户u对一物品j的兴趣:
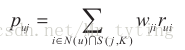
这里N(u)表示用户u喜欢的物品列表,S(j,k)表示和物品j最为相似的k个物品,Wji表示物品j和物品i的相似度。
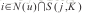
表示用户u的历史兴趣物品列表中与物品j最为相似的k个物品。
rui表示用户u对物品i的喜欢程度(对于隐反馈数据,如果用户u对物品i产生过行为,则Rui=1),该公式的含义就是,和用户历史感兴趣的物品越相似的物品越有可能在用户推荐列表获得比较高的排名。
ItemCF算法在各个评测指标上的表现:
①精度(准确率和召回率):不和k的选取成正相关或者负相关,因此选择合适的k对获得最高精度非常重要。
②流行度(降低新颖度即提高流行度):和userCF不同,ItemCF推荐结果流行度影响不是完全受k影响,随着k增加,流行度会逐渐提高,但当k提高到一定程度,流行度就不会再有变化。
③覆盖率:k增加会降低系统的覆盖率。
用户活跃度对物品相似度的影响:活跃用户对物品的相似度的贡献应该小于不活跃的用户,应该增加IUf参数来修正物品相似度的计算公式:
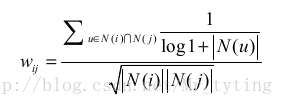
物品相似度归一化:如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率,如果得到物品的相似度矩阵,那么可以使用如下公式得到归一化之后相似度:

归一化的好处不仅仅在于增加推荐的准确率还提高了推荐的覆盖率和多样性。
下面举例说明为何归一化后结果好些:
假设物品分为两类A和B,A类内的物品相似度为0.5,B类内的物品相似度为0.6,而A类和B类之间的物品相似度为0.2.在这种情况下如果用户历史上喜欢5件A物品,喜欢5件B物品,用ItemCF给他进行推荐,推荐的就全部都是B物品,因为B类物品相似度较高。但如果归一化后,A类物品相似度为1,B类的物品相似度也为1,那么这种情况下,用户如果喜欢5个A类物品和5个B类物品,那么给他推荐的A类物品和B类物品数目应该大致相等,从这个例子来看,相似度的归一化可以提高多样性。
一般来说,热门的类其类内的物品相似度较高,如果不进行归一化,就会推荐比较热门的物品。
UseCF和ItemCF比较:
UserCF给用户推荐那些和他相似用户喜欢的物品;ItemCF给用推荐和他之前喜欢的物品相似的物品。可以看出,UserCF推荐结果着重反映和用户兴趣相似的小群体的热点;而ItemCF推荐结果着重于维系用户的历史兴趣。
个性化新闻推荐:UserCF可以给用户推荐和他相似爱好的一群其他用户今天都在看的新闻,这样抓住热点和时效性的同时,保证了一定程度的个性化。从技术方面考虑,作为一种物品,新闻更新速度快,ItemCF需要维护一张物品的相关度的表,技术上很难实现。
在电子商务,图书电影网站等:ItemCF能发挥极大优势,对这些网站来说,用户的兴趣比较固定和持久。而且物品的更新速度不是很快,一天跟新一次物品相似度矩阵损失不会太大。
总而言之,USerCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品相似度矩阵,从存储角度来说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大空间,同理,如果物品很多,那么维护物品相似度矩阵代价很大。
哈利波特问题:设计ItemCF之初发现ItemCf算法计算出图书相关表时存在一个问题,就是很多书都和《哈利波特》相关。也就是说购买一本书的人都有可能购买《哈利波特》这本书,主要是因为《哈利波特》太热门了。
回归下ItemCF计算物品相似度的经典公式:
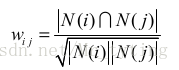
分母里面的N(j)用来惩罚热门的j,但在实际应用中,热门的j任然会获得较高的相似度。
为此我们可以在分母中加大对热门j的惩罚力度。
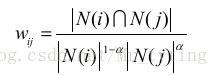
通过实验得知:只有a=0.5时才会有较高的准确率和召回率,但是a越大,覆盖率越高,并且结果的平均热门程度会降低。因此这种办法可以通过在适当牺牲准确率和召回率的情况下提升结果的覆盖率和新颖度。
两个不同热门物品类,即使不属于一种类,但是因为用户经常同时购买他们,许多用户历史兴趣物品列表里都含有这两种不同的热门类物品,这就导致ItemCF计算这两种不同类的物品相似度的结果很高。这个时候仅仅依靠用户行为是不能解决这个问题的。
实战:实现ItemCF算法
数据源下载
#coding:utf-8
import random
import math
from numpy import *
import csv
import datetime
NumOfItems=1690
def GetData(datafile='u.data'):
'''
把datafile文件中数据读出来,返回data对象
:param datafile: 数据源文件名称
:return: 一个列表,每一个元素是一个元组(userId,movieId)
'''
data=[]
try:
file=open(datafile)
except:
print ("No such file name"+datafile)
for line in file:
line=line.split('\t')
try:
data.append((int(line[0]),int(line[1])))
except:
pass
file.close()
return data
def SplitData(data,M,k,seed):
'''
划分训练集和测试集
:param data:传入的数据
:param M:测试集占比
:param k:一个任意的数字,用来随机筛选测试集和训练集
:param seed:随机数种子,在seed一样的情况下,其产生的随机数不变
:return:train:训练集 test:测试集,都是字典,key是用户id,value是电影id集合
'''
test=dict()
train=dict()
random.seed(seed)
# 在M次实验里面我们需要相同的随机数种子,这样生成的随机序列是相同的
for user,item in data:
if random.randint(0,M)!=k:
# 相等的概率是1/M,所以M决定了测试集在所有数据中的比例
# 选用不同的k就会选定不同的训练集和测试集
if user not in test.keys():
test[user]=set()
test[user].add(item)
else:
if user not in train.keys():
train[user]=set()
train[user].add(item)
return train,test
def Recall(train,test,N,k,W,relateditems,k_similar):
'''
:param train: 训练集
:param test: 测试集
:param N: TopN推荐中N数目
:param k:
:return:返回召回率
'''
hit=0# 预测准确的数目
totla=0# 所有行为总数
for user in train.keys():
tu=test[user]
rank=GetRecommendation(user,train,W,relateditems,k,N,k_similar)
for item in rank:
if item in tu:
hit+=1
totla+=len(tu)
return hit/(totla*1.0)
def Precision(train,test,N,k,W,relateditems,k_similar):
'''
:param train:
:param test:
:param N:
:param k:
:return:
'''
hit=0
total=0
for user in train.keys():
tu = test[user]
rank = GetRecommendation(user,train,W,relateditems,k,N,k_similar)
for item in rank:
if item in tu:
hit += 1
total += N
return hit / (total * 1.0)
def Coverage(train,test,N,k,W,relateditems,k_similar):
'''
计算覆盖率
:param train:训练集 字典user->items
:param test: 测试机 字典 user->items
:param N: topN推荐中N
:param k:
:return:覆盖率
'''
recommend_items=set()
all_items=set()
for user in train.keys():
for item in train[user]:
all_items.add(item)
rank=GetRecommendation(user,train,W,relateditems,k,N,k_similar)
for item in rank:
recommend_items.add(item)
return len(recommend_items)/(len(all_items)*1.0)
def Popularity(train,test,N,k,W,relateditems,k_similar):
'''
计算平均流行度
:param train:训练集 字典user->items
:param test: 测试机 字典 user->items
:param N: topN推荐中N
:param k:
:return:覆盖率
'''
item_popularity=dict()
for user,items in train.items():
for item in items:
if item not in item_popularity:
item_popularity[item]=0
item_popularity[item]+=1
ret=0
n=0
for user in train.keys():
rank= GetRecommendation(user,train,W,relateditems,k,N,k_similar)
for item in rank:
if item!=0:
ret+=math.log(1+item_popularity[item])
n+=1
ret/=n*1.0
return ret
def getW(train):
#train本身已经是用户->物品倒排表
#W[u][v]表示物品u和物品v的相似度
W=zeros([NumOfItems,NumOfItems],dtype=float16)
#C[u][v]表示喜欢u有喜欢v物品的用户有多少个
C=zeros([NumOfItems,NumOfItems],dtype=float16)
#N[u]表示有多少用户喜欢物品u
N=zeros([NumOfItems],dtype=float16)
item_relateditems=dict()
for user,items in train.items():
for item1 in items:
N[item1]+=1
for item2 in items:
if item1==item2:
continue
if item1 not in item_relateditems:
item_relateditems[item1]=set()
item_relateditems[item1].add(item2)
C[item1][item2]+=(1/math.log(1+len(items)*1.0))
for item1 in range(1,NumOfItems):
if item1 in item_relateditems:
for item2 in item_relateditems[item1]:
W[item1][item2]=C[item1][item2]/sqrt(N[item1]*N[item2])
return W,item_relateditems
def k_similar_item(W,item_relateditems,k):
'''
:param W:
:param item_relateditems:
:param k:
:return:返回一个字典,key是每个item,value是item对应的k个最相似的物品
'''
begin=datetime.datetime.now()
k_similar=dict()
for i in range(1,NumOfItems):
relateditems=dict()
try:
for x in item_relateditems[i]:
relateditems[x]=W[i][x]
relateditems=sorted(relateditems.items(),key=lambda x:x[1],reverse=True)
k_similar[i]=set(dict(relateditems[0:k]))#返回k个与物品i最相似的物品
except KeyError:
print(i, " doesn't have any relateditems")
k_similar[i]=set()
for x in range(1,k+1):
k_similar[i].add(x)
end=datetime.datetime.now()
print("it takes ", (end - begin).seconds, " seconds to get k_similar_item for all items.")
return k_similar
def GetRecommendation(user,train,W,relateditems,k,N,k_similar_items):
'''
:param user: 目标用户
:param train: 训练集 字典user->items
:param W: 物品相似度矩阵
:param relateditems: 字典 items->相关item
:param k: 从目标用户历史兴趣列表中选取k个与推荐item最为相似的物品
:param N: 给目标用户推荐N个物品
:param k_similar_items: 一个字典,key是每个item,value是item对应的k个最相似的物品
:return:
'''
rank=dict()#key是电影id,value是兴趣大小
for i in range(NumOfItems):
rank[i]=0
possible_recommend=set()
for item in train[user]:
##返回训练集中和目标用户历史兴趣物品相似度不为0的物品item
possible_recommend=possible_recommend.union(relateditems[item])
for item in possible_recommend:
k_items=k_similar_items[item]#返回与item最为相似的k个物品
for i in k_items:
if i in train[user]:#且返回的k个物品必须在目标用户历史兴趣物品列表里
rank[item]+=1.0*W[item][i]
##rank字典,key是itemId,value是用户user对这个推荐的itemId的兴趣程度,前提是这个item不能出现在用户user历史兴趣物品列表里
for rank_key in rank:
if rank_key in train[user]:##如果推荐的item出现在用户历史兴趣物品列表里,则赋值0
rank[rank_key]=0
#按照用户user对推荐的item兴趣程度,从大到小排序,推荐N个物品
return dict(sorted(rank.items(),key=lambda x:x[1],reverse=True)[0:N])
def evaluate(train,test,N,k):
##计算一系列评测标准
recommends=dict()
W,relateditems=getW(train)
k_similar = k_similar_item(W, relateditems, k)
for user in test:
recommends[user]=GetRecommendation(user,train,W,relateditems,k,N,k_similar)
recall=Recall(train,test,N,k,W,relateditems,k_similar)
precision=Precision(train,test,N,k,W,relateditems,k_similar)
coverage=Coverage(train,test,N,k,W,relateditems,k_similar)
popularity=Popularity(train,test,N,k,W,relateditems,k_similar)
return recall,precision,coverage,popularity
def test2():
N=int(input("input the number of recommendations: \n"))
k=int(input("input the number of related items: \n"))
data=GetData()
train,test=SplitData(data,2,1,1)
del data
recall,precision,coverage,popularity=evaluate(train,test,N,k)
print("Recall: ",recall)
print("Precision: ",precision)
print("Coverage: ",coverage)
print("Popularity: ",popularity)
if __name__=='__main__':
test2()














 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









