







 针对推荐系统中的冷启动问题,本文介绍了三种类型的冷启动:用户冷启动、物品冷启动及系统冷启动,并提供了多种解决方案,如热门排行推荐、基于用户注册信息推荐、利用社交网络账号等。
针对推荐系统中的冷启动问题,本文介绍了三种类型的冷启动:用户冷启动、物品冷启动及系统冷启动,并提供了多种解决方案,如热门排行推荐、基于用户注册信息推荐、利用社交网络账号等。
我们之前讨论推荐系统的UserCF算法和ItemCF等算法都是以拥有大量用户行为数据为先决条件,并以此对物品或者用户进行自动聚类。但是对于一个刚刚开始运行推荐系统的应用的网站来说,如何在没有大量用户行为数据的情况下设计个性化推荐系统并且让用户对推荐系统满意,从而愿意使用推荐系统,这就是冷启动问题。
对于冷启动问题,一般分为三类:
一)用户冷启动:如何对新用户做个性化推荐。
二)物品冷启动:如何将新加进来的物品推荐给对它感兴趣的用户。
三)系统冷启动:新开发的网站如何设计个性化推荐系统。
对以上三个冷启动,通常参考如下解决方案:
一)提供个性化的推荐:比如热门排行榜。等用户行为数据收集到一定时候再切换为个性化推荐。
二)利用注册信息,比如提供的年龄,性别等做粗粒化的推荐。
三)利用用户社交网络账号登录。
四)要求用户在注册时对一些物品进行反馈。收集用户兴趣信息。
五)对新加的物品,利用内容信息,将他们推荐给喜欢过和他们内容类似的用户。
六)系统冷启动时,可引入专家知识,通过一定高效方式迅速建立物品的相关度表。
以下详细说明以上的解决方案
一 新用户冷启动问题:
方法一 : 利用用户注册信息
(1)人口统计学:用户年龄,性别,职业,民族,学历和居住地
(2)用户兴趣描述:一些网站会让用户描述他们的兴趣爱好
(3)从其他网站导入用户站外行为数据
基于注册信息的个性化推荐流程基本如下:
①获取用户注册信息
②根据用户注册信息对用户进行分类,分类可以是多分类(也即是多个特征)
③给用户推荐他所在分类的用户最喜欢的物品,每个分类(特征)用户最喜欢的物品加权求和。
实际应用中也会考虑组合特征,但是新用户不一定具有所有的特征,因为有些时候并不要求用户填写相关特征信息。
由以上可知,基于用户注册信息的推荐算法其核心问题是计算出每种特征(所属分类)用户喜欢的物品,也就是说,对于每种特征f,计算具有这种特征的用户对每个物品的喜欢程度p(f,i)
p(f,i)可以简单定义为具有特征f的用户对物品i的喜好程度:
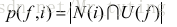
其中N(i)表示喜欢物品i的用户集合,U(f)表示具有特征f的用户集合。
跟之前讲到推荐系统算法类似,这个公式也有一个缺点,如果一个物品是热门物品那么他的p(f,i)将会非常高,则在给用户推荐物品时会倾向于推荐热门物品,由此则覆盖率极低。我们在设计推荐系统时,主要任务不是给用户推荐热门物品,而是帮助用户发现他喜欢但是却不太容易发现的物品。因此我们可以对上面公式做以下改进,同以前一样,对热门物品进行惩罚:
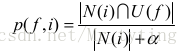
上面公式中分母的作用是解决数据稀疏的问题。比如一个物品只被一个用户喜欢过,而这个用户刚好有特征f,那么p(f,i)=1,这样的统计量没有意义,因此我们在分母上加上一个比较大的数,可以避免这样的物品产生比较大的权重。
这样我们就可以计算出每一类用户中最受欢迎的物品列表。
方法二:选择合适的物品启动用户兴趣
用户第一次访问推荐系统时,不立即进行推荐,而是提供一些物品让用户进行反馈。然后根据反馈结果进行个性化推荐。
而这些提供的物品应该具有哪些特性呢?一般来讲应该符合以下几个原则:
①比较热门
②具有代表性和区分性
③具有多样性
上面只是物品冷启动的原则,那么在实际选择启动的物品集合时应该怎么做呢?可以利用决策树的思想,给定一群用户,利用这群用户对物品评分的方差度量这群用户兴趣的一致程度,如果方差很大说明这个物品的区分性很好。
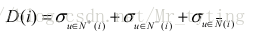
其中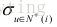
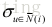

首先会从所有用户中寻找具有最高区分度的物品i,然后将用户分成3类,然后从每类中在寻找最高区分度的物品,再将用户分三类,这样就9类了,一直继续下去,最终可以通过对一系列物品的看法对用户进行分类。而在冷启动时,我们从根节点开始询问用户对该节点物品的看法,然后根据用户的选择将用户放到不同的分支,直至最后进入叶子节点。这样我们就可以对用户的兴趣有了比较清楚的了解。从而可以对用户进行个性化推荐。
二:物品冷启动问题
物品冷启动要解决的问题是如何将新加的物品推荐给对它感兴趣的用户。
之前我们介绍了UserCF算法和ItemCF算法。UserCF算法并不对新物品很敏感,在很多网站中,推荐列表并不是给用户展示物品的唯一列表。当一个用户在某个地方发现了新加的物品并对其进行了反馈。通过UserCF算法给类似具有相同兴趣的用户推荐这个物品。这样新加的物品就会源源不断的扩散开来。
但是有些网站中推荐列表就是用户获取新加物品唯一的或者是主要途径。这时就要解决第一推动力的问题。也即是第一个用户在哪发现新加物品的问题。解决这个问题的最简单的办法就是将新加的物品随机的展示给用户,但是这样做显然并不个性化。因此可以考虑利用物品内容信息,将新物品投放给曾经喜欢过和他类似内容的其他物品的用户,这类似于ItemCF思想。不过这是先通过ItemCF找到一个可能对物品感兴趣的用户,然后再通过USerCF推荐给与此用户兴趣类似的其他用户。
如果用ItemCF算法解决物品冷启动问题,就有点麻烦了,因为ItemCF通过用户行为对物品进行相似度的计算,形成物品相似度矩阵。再根据这个相似度矩阵把物品推荐给喜欢过类似这个物品的用户。这个物品相似度矩阵是线下计算好,线上放进内存。从而新物品不会出现在物品相似度矩阵中。解决的办法是频繁的更新相似度矩阵。这是一件非常耗时的事情。为此我们只能通过物品内容来计算物品相似度矩阵。这就涉及到如何通过物品内容来计算物品相似度的问题,下面来详细讲述这个问题。
一般来说,物品的内容可以用向量空间模型表示,该模型会把物品表示成一个关键词向量。对于物品d,他的内容表示成一个关键词向量如下:
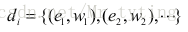
其中e是关键词,w是这个词对于权重,其中w的计算公式就是著名的TF-IDF公式:
TF-IDF重要思想就是:一个不常见的词在一篇文章中出现多次,那么对于这篇文章来说他肯定是关键词。
第一步计算词频TF:

因为不同的文章长度不一样,需要进行标准化:

然后第二步,计算逆文档频率。
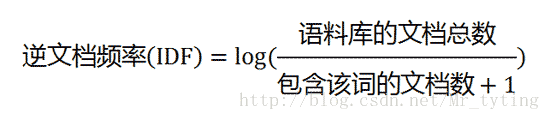
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
再计算TF-IDF值:
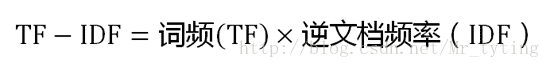
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。如此可以得出关键词排名。
在得出给定物品内容的关键词向量后,物品的内容相似度可以通过向量之间的余弦相似度计算:
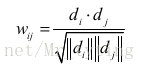
实际应用中,首先建立 关键词-物品的倒排表。由此建立物品相似度矩阵。得出物品相似度以后,可以根据ItemCF思想给用户推荐物品。
可能我们会有疑惑,内容相似度能频繁更新,而且能够解决物品冷启动问题,那么为什么还要用协同过滤算法?通过大量的实验我们可以得出这样一个结论:如果用户的行为强烈受到某一内容属性的影响,那么内容过滤的算法可以在精度上超过协同过滤,但是大多数情况下这种强的内容特征并不是所有物品都具备的,大多数情况下,内容过滤的算法精度比协同过滤算法差。
向量空间模型在内容数据丰富的情况下可以获得很好的效果,但是如果文本很短,关键词很少,又或者是两篇文章的关键词不同,但是所包含的意思很近,也即是话题相同。在这种情况下,向量空间模型很难计算出准确的相似度。此时就要研究文章的话题分布,才能准确的计算出文章的相似度。
代表性的话题模型有LDA模型,关于LDA话题模型的讲解请看如下链接:
LDA模型原理以及推导推导
LDA模型能将词很好组成不同的话题,我们可以先计算物品在话题上的分布,然后利用两个物品在话题分布计算物品的相似度。
发挥专家作用:利用专家(对物品进行标注,在计算物品的相似度。也即是人工办法对物品进行标注分类,计算相似度。

















 65
65

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









