







本篇博文将详细总结集成学习里面的一个非常重要的模型,xgboost。
Boosting(提升)
提升是一个机器学习技术,可以用于回归和分类问 题,它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型生 成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient boosting)。
梯度提升算法首先给定一个目标损失函数,它的定义域是所有可行的弱函数集合(基函数),即自变量就是每次加进来的基函数;提升算法 通过迭代的选择一个负梯度方向上的基函数来逐渐逼近局部极小值。(沿着梯度下降方向建立基函数)这种在函数域的梯度提升观点对机器学习的很多领域有深刻影响。
提升的理论意义:如果一个问题存在弱分类器,则 可以通过提升的办法得到强分类器。
提升算法
给定输入向量x和输出变量y组成的若干训练样本(x1,y1),(x2,y2),…,(xn,yn),目标是找到近似函数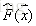
L(y,F(x))的典型定义为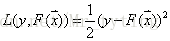
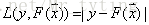
假定最优函数为
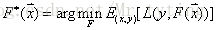
假定F(X)是一族基函数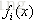
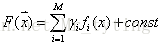
梯度提升方法寻找最优解F(x),使得损失函 数在训练集上的期望最小。方法如下:
首先,给定常函数
:
以贪心的思想扩展到
:
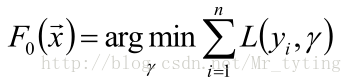
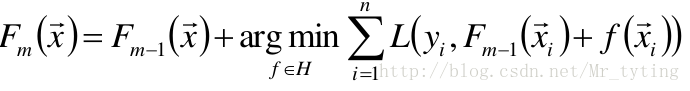
梯度近似
使用梯度下降法近似计算
将样本代入基函数f得到
,从而L退化为向量
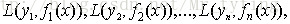
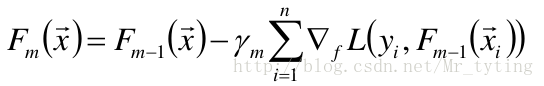
提升算法的一般步骤(GBDT):
- 给定初始模型为常数
对于m=1到M:
① 计算伪残差
注意:是对函数F求偏导,不是对x求导。
②使用数据
计算拟合残差的基函数
③给定一个步长
④更新模型
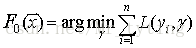
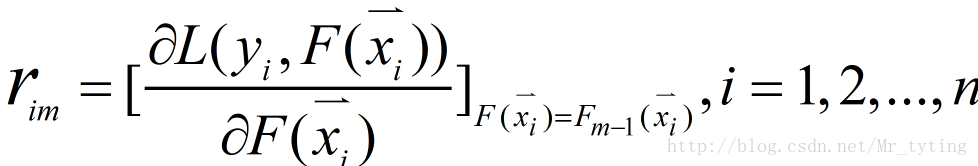
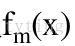
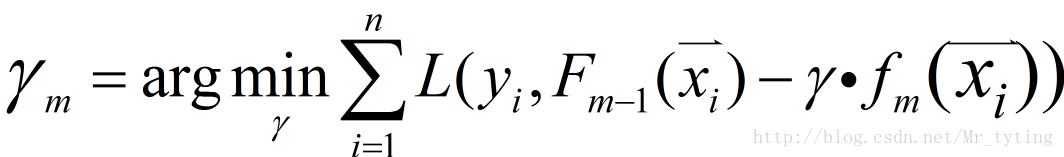
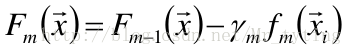
参数设置和正则化
对训练集拟合过高会降低模型的泛化能力,需要使 用正则化技术来降低过拟合。
- 对复杂模型增加惩罚项,如:模型复杂度正比于叶结点 数目或者叶结点预测值的平方和等。
- 用于决策树剪枝。
叶结点数目控制了树的层数,一般选择4≤J≤8。
叶结点包含的最少样本数目
- 防止出现过小的叶结点,降低预测方差
梯度提升迭代次数M:
- 增加M可降低训练集的损失值,但有过拟合风险
- 交叉验证
衰减因子、降采样
衰减Shrinkage
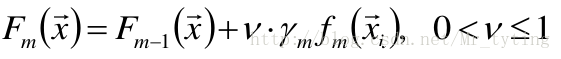
- 称ν为学习率
- ν=1即为原始模型;推荐选择v<0.1的小学习率。过小的 学习率会造成计算次数增多。
随机梯度提升Stochastic gradient boosting
- 每次迭代都对伪残差样本采用无放回的降采样,用部分 样本训练基函数的参数。令训练样本数占所有伪残差样本的比例为f;f=1即为原始模型:推荐0.5≤f≤0.8。
- 较小的f能够增强随机性,防止过拟合,并且收敛的快。
- 降采样的额外好处是能够使用剩余样本做模型验证。
Xgboost
上面说的提升只是用到了梯度,也就是一阶导。现在考虑使用二阶导信息
目标函数:也即损失函数,我们希望损失函数越小越好

需要解释下上面公式一些变量含义:L表示损失函数,





根据泰勒公式进行展开:
泰勒公式:

对应上面泰勒展式中的x即为


令:

注:在XGBoost里面,自定义损失函数后,这个一阶导和二阶导可以自定义的给出。
然后根据泰勒展式对损失函数L进行展开到二阶导,得到展开后的目标函数为:

我们观察新得出的目标函数




决策树的描述
使用决策树对样本做分类(回归),是从根结点到叶节点的细化过程;落在相同叶节点的 样本的预测值是相同的。
假定某决策树的叶结点数目为T,每个叶结点的权值为
样本x落在叶结点q中,定义f为


为什么把叶子节点上数值成为叶权值呢?因为在后面的推导过程中,为了不断的使损失函数变少,可以计算出下一课树的叶节点的值。
正则项
上面说了

这里面很明显


其中T表示当前第t个决策树的叶子的个数。

目标函数计算:
目标函数是关于


T表示叶子节点个数,

继续简化:

这样我们就计算出下一课树的叶子节点的权值。
我们的目的就是希望这个目标函数越来越小。

如何进行子树划分?

借鉴ID3/C4.5/CART的做法,使用贪心法:
- 对于某可行的划分,计算划分以后的J(f)。
- 对于所有可行划分,选择J(f)降低最小 的分割点。
- 上面两个步骤,可以并行的计算,就是尝试同时在多个点进行划分,同时计算出哪个划分点最优。这样应该就是Xgboost的并行,也就是树的生成的并行完成的。极大的提高了速度。

注意:增益最大的划分。
Xgboost包的使用
Xgboost详细的使用说明请看xgboost文档
这里给出一个简单的代码示例
# /usr/bin/python
# -*- encoding:utf-8 -*-
import xgboost as xgb
import numpy as np
# 1、xgBoost的基本使用
# 2、自定义损失函数的梯度和二阶导
# 3、binary:logistic/logitraw
# 定义f: theta * x
def log_reg(y_hat, y):
p = 1.0 / (1.0 + np.exp(-y_hat))
g = p - y.get_label()
h = p * (1.0-p)
return g, h
def error_rate(y_hat, y):
return 'error', float(sum(y.get_label() != (y_hat > 0.5))) / len(y_hat)
if __name__ == "__main__":
# 读取数据
data_train = xgb.DMatrix('agaricus_train.txt')## libsvm格式,包含特征和标签
data_test = xgb.DMatrix('agaricus_test.txt')## libsvm格式,包含特征和标签
print data_train
print type(data_train)
# 设置参数
# max_depth:树的最大深度;eta:学习步长;silent:是否打印模型训练时的一些信息;
param = {'max_depth': 3, 'eta': 1, 'silent': 1, 'objective': 'binary:logistic'}
# param = {'max_depth': 3, 'eta': 0.3, 'silent': 1, 'objective': 'reg:logistic'}
watchlist = [(data_test, 'eval'), (data_train, 'train')]## 查看输出模型训练时在训练集和测试集上的精度
n_round = 7## 最多的树木数,也就是轮数
# bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist)
##自定义错误率计算方式feval=error_rate;自定义一阶导数二阶导数obj=log_reg
bst = xgb.train(param, data_train, num_boost_round=n_round, evals=watchlist, obj=log_reg, feval=error_rate)
# 计算错误率
y_hat = bst.predict(data_test)
y = data_test.get_label()
print 'y_hat:',y_hat
print 'y:',y
error = sum(y != (y_hat > 0.5))
error_rate = float(error) / len(y_hat)
print '样本总数:\t', len(y_hat)
print '错误数目:\t%4d' % error
print '错误率:\t%.5f%%' % (100*error_rate)
总结
以上即为XGBoost使用的核心推导过程。
相对于传统的GBDT,XGBoost使用了二阶信息,可以更快的在训练集上收敛。
由于“随机森林族”本身具备过拟合的优势, 因此XGBoost仍然一定程度的具有该特性。
XGBoost的实现中使用了并行/多核计算,因此 训练速度快;同时它的原生语言为C/C++,这是 它速度快的实践原因。















 7115
7115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









