







Hierarchical Aggregation for 3D Instance Segmentation是一个用于实例分割的方法,他主要利用了点以及点集之间的空间关系,以此进行实例分割。大概步骤如下:
- 首先进行低带宽点汇集得到初步的实例以避免过度分割
- 之后进行动态带宽集合汇集以得到完整的实例
- 引入实例内网络进行去噪
目录
1.网络结构
网络主要分为四大部分,分别是:逐点预测(point-wise prediction)、点汇集(point aggregation)、集合聚集(set aggregation)以及实例内预测(intra-instance prediction),接线来将分别介绍这四部分。
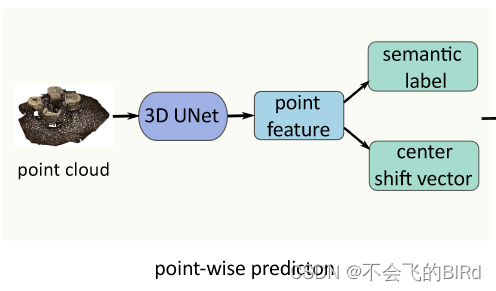
1.1 逐点预测(point-wise prediction)
逐点预测主要做了特征提取的工作,并对提取的特征做了进一步处理以方便后续的操作。具体操作步骤如下:
- 首先将点云体素化
- 之后用多层曲面稀疏卷积形成一个类似U形状的网络来提取特征
- 再将点特征映射回点特征
接下来两个分支是并行的:
- 语义标签预测:
- 在点上使用两层的MLP以及softmax来预测每个类别的语义分数,取其中最高的分数作为当前点的类别标签。使用交叉熵损失来进行优化。
- 中心偏移向量预测:
- 在点上应用2层的MLP来预测逐点中心偏移向量,它表示从每个点到对应实例中心的偏移量。其中实例中心是每个实例所有点坐标的平均值。
具体来说,这部分U-net的结构:
def forward(self, input):
output = self.blocks(input)#对输入应用块序列
#将输出转换为张量
identity = spconv.SparseConvTensor(output.features, output.indices,
output.spatial_shape, output.batch_size
)
if len(self.nPlanes) > 1:
output_decoder = self.conv(output)#编码器部分
output_decoder = self.u(output_decoder)#U形结构部分
output_decoder = self.deconv(output_decoder)#解码器部分
#将卷积前的特征和卷积后的拼接起来
output.features = torch.cat((identity.features, output_decoder.features), dim=1)
output = self.blocks_tail(output)#通过一个tail_block
return output
语义标签分支:
# semantic segmentation branch
self.semantic_linear = nn.Sequential(
nn.Linear(width, width, bias=True),
norm_fn(width),
nn.ReLU(),
nn.Linear(width, classes)
)#两层的MLP,之后会跟上softmax
中心偏移向量分支:
# center shift vector branch
self.offset_linear = nn.Sequential(
nn.Linear(width, width, bias=True),
norm_fn(width),
nn.ReLU(),
nn.Linear(width, 3, bias=True)
)#两层的MLP,之后会跟上softmax
具体结构如下:
1.2 点汇集(point aggregation)
原始点集

点汇集是为了获得初步实例,主要做了两件事:
- 首先根据中心点偏移向量将点向实例中心移动:
x
i
s
h
i
f
t
=
x
i
o
r
i
g
i
n
+
△
x
i
x_{i}^{shift} = x_{i}^{origin} + \triangle x_{i}
xishift=xiorigin+△xi 移动后的情况如图:

- 其次,忽略所有的背景点,在同语义标签,并且彼此之间距离小于点聚合阈值rpoint的点之间添加一条边。在遍历完所有的点之后,就得到了初步的实例。遍历之后的结果如图:

注:点聚合中的阈值 rpoint 大小是固定的。
1.3 集合聚集(set aggregation)
进行点汇集之后会发现有很多小的实例,观察ground truth会发现实际上这些小的实例并不存在,因此分析可能是这些小的实例属于一个大的实例,因而有了集合汇聚。
将小尺寸的实例称为片段,将大尺寸的实例称为主实例
集合汇集和点汇集的思想类似,片段 m 加入主实例 n的条件:
- 在所有与片段m相同语义的主实例中,n的中心点离m的中心点最近
- 对于片段m和实例n,二者的中心点距离小于集合聚合阈值rset
rset 的定义:
r
s
e
t
=
m
a
x
(
r
s
i
z
e
,
r
c
l
s
)
r_{set} = max(r_{size},r_{cls})
rset=max(rsize,rcls)
r
s
i
z
e
=
α
√
S
p
r
i
m
n
‾
r_{size} = \alpha \surd \overline{ S_{prim}^{n} }
rsize=α√Sprimn
r size 表示特定大小的带宽,并且考虑 r size相对于主实例 n 的大小 Sn prim 的平方根;
rcls 表示特定类别的带宽,它是特定类别的统计平均实例半径。
实例大小分布图:
由此可见,经过集合汇聚后更接近于真实状态实例大小的分布。
集合汇聚之后的结果:

1.4 实例内预测(intra-instance prediction)
由于分层聚合可能会错误地吸收属于其他实例的片段,从而产生不准确的实例预测。因此,使用实例内预测网络来进一步细化实例。
首先,裁剪实例点云补丁作为输入,并使用 3D 子流形稀疏卷积网络来提取实例内部的特征。提取特征之后,掩膜分支预测二进制掩码以区分实例前景和背景。对于每一个预测实例,选择最匹配的真值作为掩码监督。
预测实例和真值重合的部分作为正标签,其他部分作为负标签。低质量的实力包含很少的实例级信息,他们对于优化mask分支毫无用处,因此只选择IoU大于0.5的分支作为训练样本。
除了mask预测之外,还需要实例确定性分数来対实例排名,利用mask对实例进行更好的评分。
首先使用mask过滤掉背景点的特征,随后将前景点的特征送入MLP以预测实例确定性得分。
其次,将真值和预测掩膜的IoU作为掩膜质量,使用该值监督实例的确定性。
具体流程如下图:

在层次聚合过程中,点的变化过程如图:

1.5 整体网络架构

2.损失函数
整个网络以end 2 end的方式从头开始训练,并通过由多个损失项组成的联合损失进行优化,主要包括四部分:
(这里的公式太多了,手打有点费时间,直接上图吧)
2.1语义分数的交叉熵损失
使用语义分数的交叉熵损失 Lseg 用于训练该分支,在论文中没有给出具体的形式,在代码中:
使用交叉熵损失:
semantic_criterion = nn.CrossEntropyLoss(ignore_index=cfg.ignore_label).cuda()
具体的计算过程:
'''semantic loss'''
semantic_scores, semantic_labels = loss_inp['semantic_scores']#获取分数和标签
# semantic_scores: (N, nClass), float32, cuda
# semantic_labels: (N), long, cuda
semantic_loss = semantic_criterion(semantic_scores, semantic_labels)#计算损失
loss_out['semantic_loss'] = (semantic_loss, semantic_scores.shape[0])
2.2中心移位向量的损失
在该计算过程中,背景点被忽略不计,计算公式如下:

其中,1(*)是指标函数;P是整个点集;Pfg是前景点集;w(pi) 是一个点加权项(越靠近实例中心的点越少依赖于偏移向量,因此对损失贡献更少)。
'''偏移损失'''
pt_offsets, coords, instance_info, instance_labels = loss_inp['pt_offsets']
# pt_offsets: (N, 3), float, cuda
# coords: (N, 3), float32
# instance_info: (N, 9), float32 tensor (meanxyz, minxyz, maxxyz)
# instance_labels: (N), long
gt_offsets = instance_info[:, 0:3] - coords # (N, 3)
pt_diff = pt_offsets - gt_offsets # (N, 3)
pt_dist = torch.sum(torch.abs(pt_diff), dim=-1) # (N)
valid = (instance_labels != cfg.ignore_label).float()
offset_norm_loss = torch.sum(pt_dist * valid) / (torch.sum(valid) + 1e-6)
loss_out['offset_norm_loss'] = (offset_norm_loss, valid.sum())
2.3掩码预测的损失
掩码预测过程中只对IoU>0.5的做计算

其中,Nins代表实例个数;Ni代表实例i中的点数。
2.4分数预测的损失

总的损失等于上述4项的加和:L = Lseg + Lshift + Lmask + Lscore
2.5 无需NMS,只需单向推理
由于基于多提案的模型大多生成的实例数量过多,因此需要使用NMS去除效果差的部分,只保留最好的结果。但是在HAIS中,一个点只属于一个instance,所以不存在重叠的实例,因此不需使用NMS。
直接使用实例确定性分数对实例进行排序,并将分数最高的实例作为最终预测,不再需要任何后处理步骤
3.实验
实验部分在ScanNet v2和S3DIS数据集上做了实验。主要内容包括四部分:
提供了定量评估结果、定性评估结果来证明HAIS的有效性,并且提供了详细的 ablation研究,并做了推理速度评估
具体细节参见文章第四节:文章链接















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









