







本文主要介绍了YOLO V2 关于V1的变动。
YOLO V2
1.主要变化
回顾一下,在V1中,每个图片被分成7x7的cell,每个cell产生2个预测框,每个框有(x,y,w,h,confidence score)5个维度,以及20个类,因此V1的输出为7x7x(5x2+20) 的Tensor;
而在V2中,每个图片被分为13x13的cell,每个cell产生5个预测框,每个预测框包含(x,y,w,h,confidence score)5个维度以及20个类,因而V2的输出为13x13x5x(5+20)
(1)Batch normalization
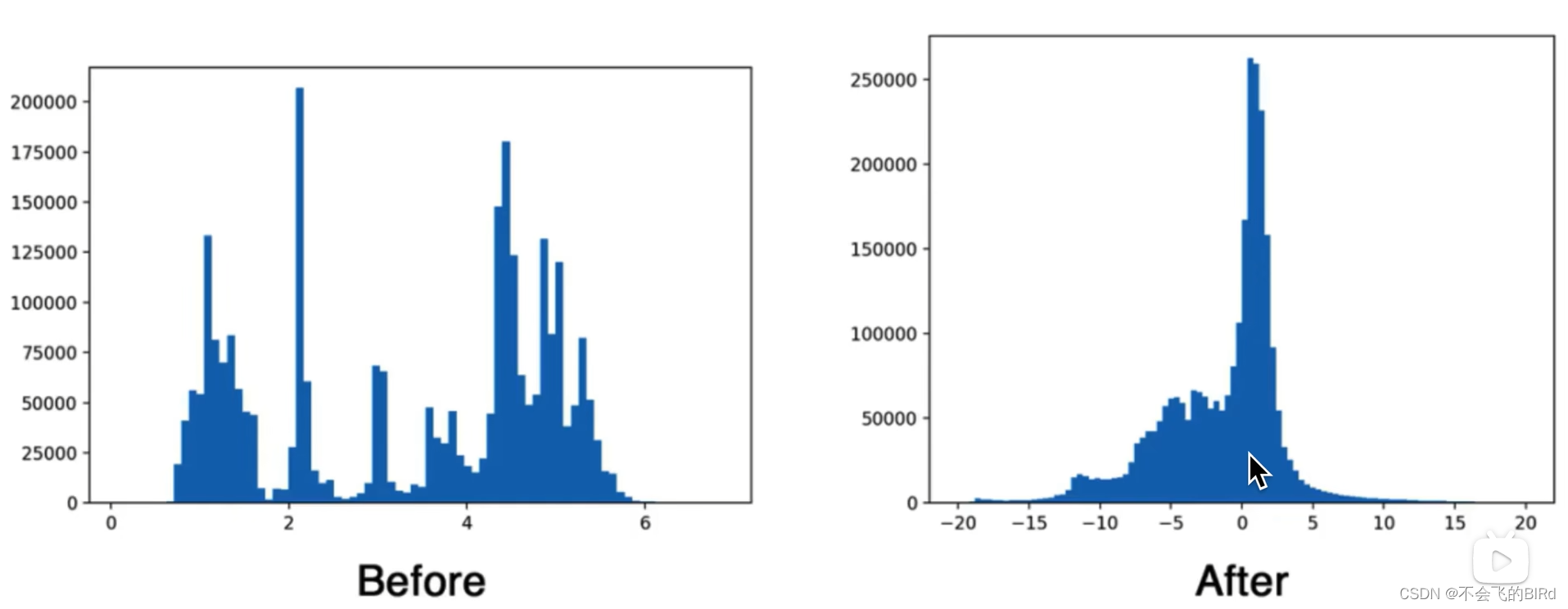
在V2中对每一conv层都添加了BN,BN的具体步骤:
标准化具体步骤: 将输出减去均值,除以标准差,以将其集中到0附近,将标准化后的结果乘以权重加上偏置,就能得到BN后的结果
这里的偏置和权重需要训练得到
在测试阶段只需对训练阶段得到的所有参数进行线性变换即可得到测试阶段所需的偏置和权重
作用:
-
由于很多激活函数(例如sigmoid)在0附近为非饱和区,可以避免梯度消失,利于训练,因此使用BN将输出集中到0附近。
-
缩短训练时间:在神经网络的训练过程中,BN层可以使得网络加速收敛,从而缩短训练时间。
-
提高模型泛化能力:BN层可以有效地减少过拟合,提高模型的泛化能力。

(2)High-resolution classifier
如果使用在224x224 的数据集上训练好的模型再在448x448 的数据集上训练,会浪费很多时间,因此,在训练过程中首先使用 224 × 224 张图片进行分类器训练,然后使用 448 × 448 张图片重新调整分类器。这样可以减少训练时间。
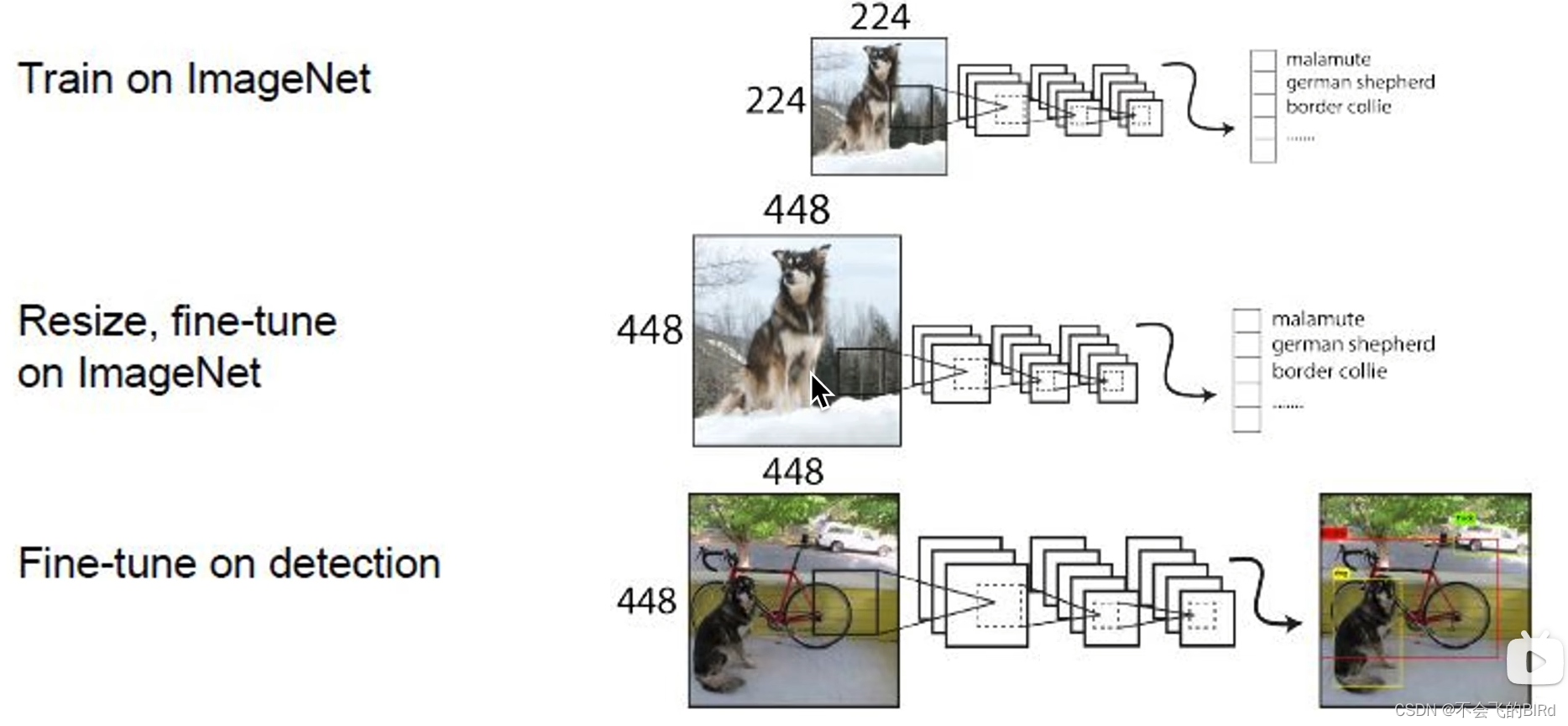
(3)Convolutional with Anchor Boxes
在v2中使用锚框替换掉FC层,这样可以适应不同尺寸的输入数据。
将图像分为13x13的 grid cell ,每个cell 产生5个锚框
这里锚框是固定的宽高比是固定的
因此从一开始,每个框就有自己的使命(各负责检测不同的形状的物体)具体步骤:
-
物体落在哪一个cell中就由这个cell来负责预测该物体
-
每个cell产生5个锚框
-
选择5个锚框中与ground truth IOU最大的那一个锚框来产生预测框预测该物体
-
预测框输出与对应锚框的偏移量
(4)Fine-Grained Features(细粒度特征)
简单来讲就是将高维语义特征和低微细节特征进行拼接,使得特征提取既包含语义特征,也包含细节特征。该步骤使用了passthrough layer 来实现该操作:
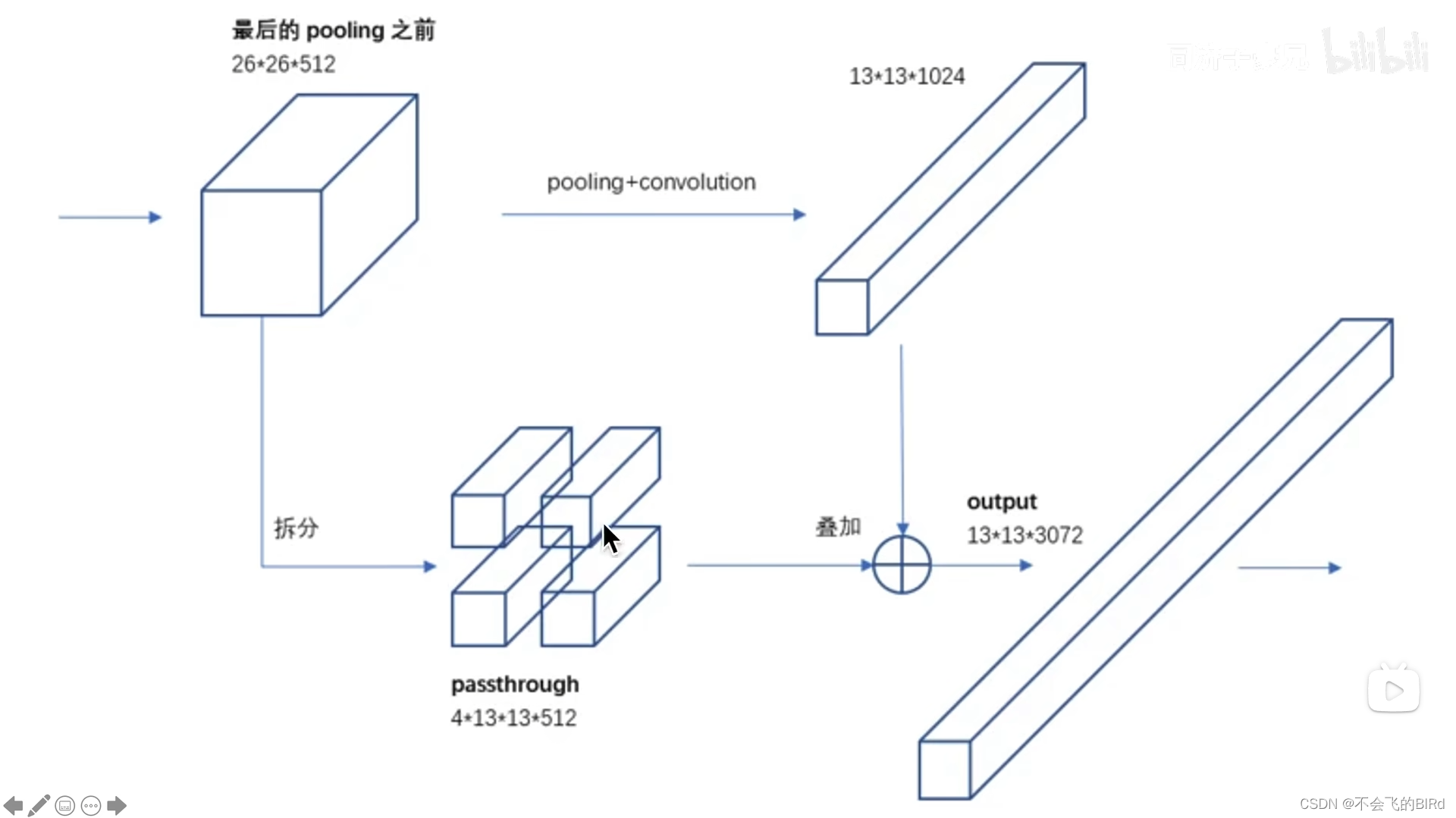
将pooling之前的输出,复制一份:
- 一份进行正常的conv和pooling操作得到,13x13x1024的高维语义特征;
- 另一份拆成四份得到4x13x13x512的特征,将四个维度拼接得到13x13x2048的低维细节特征;
然后将两个分支的特征相加。
(5)Dimension Clusters
在V1中,锚框是人工挑选的,在v2中使用k-means聚类来进行选择。
在模型复杂度与IOU进行平衡取舍,最后认为当K=5时,可以得到最平衡的结果。
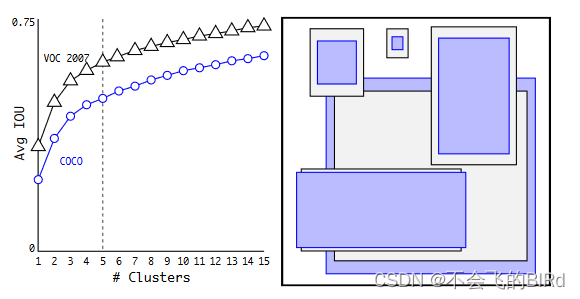
将聚类与手工选择的方法进行对比可以看到聚类使用K=5时的IOU比手工选择使用K=9时还要好,证明使用Cluster是一个很好的选择

(6)Direct location prediction
在V1中,损失主要来自于定位,由于没有对预测框的位置进行限制,导致一个cell的预测框可以出现在任何地方,这既不利于前期的训练,也不利于模型的稳定性。
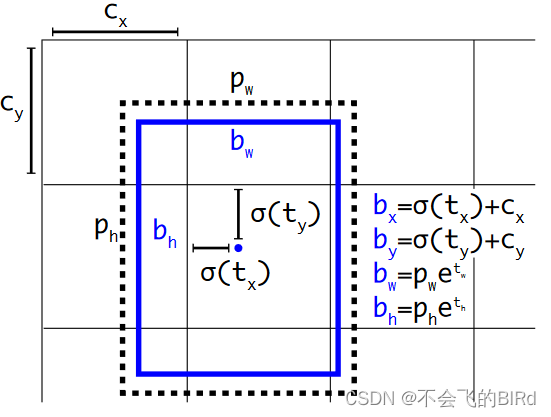
在V2中网络预测输出特征图中每个单元的 5 个边界框。网络会为每个边界框预测 5 个坐标:tx、ty、tw、th 和 to。如果单元格与图像左上角的偏移量为 (cx,cy),且边界框的宽度和高度分别为 pw、ph,则预测结果对应于:
- bx、by: 使用sigmoid函数将偏移量固定在[0,1],再加上对应cell的xy坐标,可以将预测框的中心点限制在该cell中
- bw、bh: 由于物体有大有小,因此并不对宽高做出限制,使得宽高可以自由变化
注意这里,把每一个 grid cell 归一化成1x1的网格
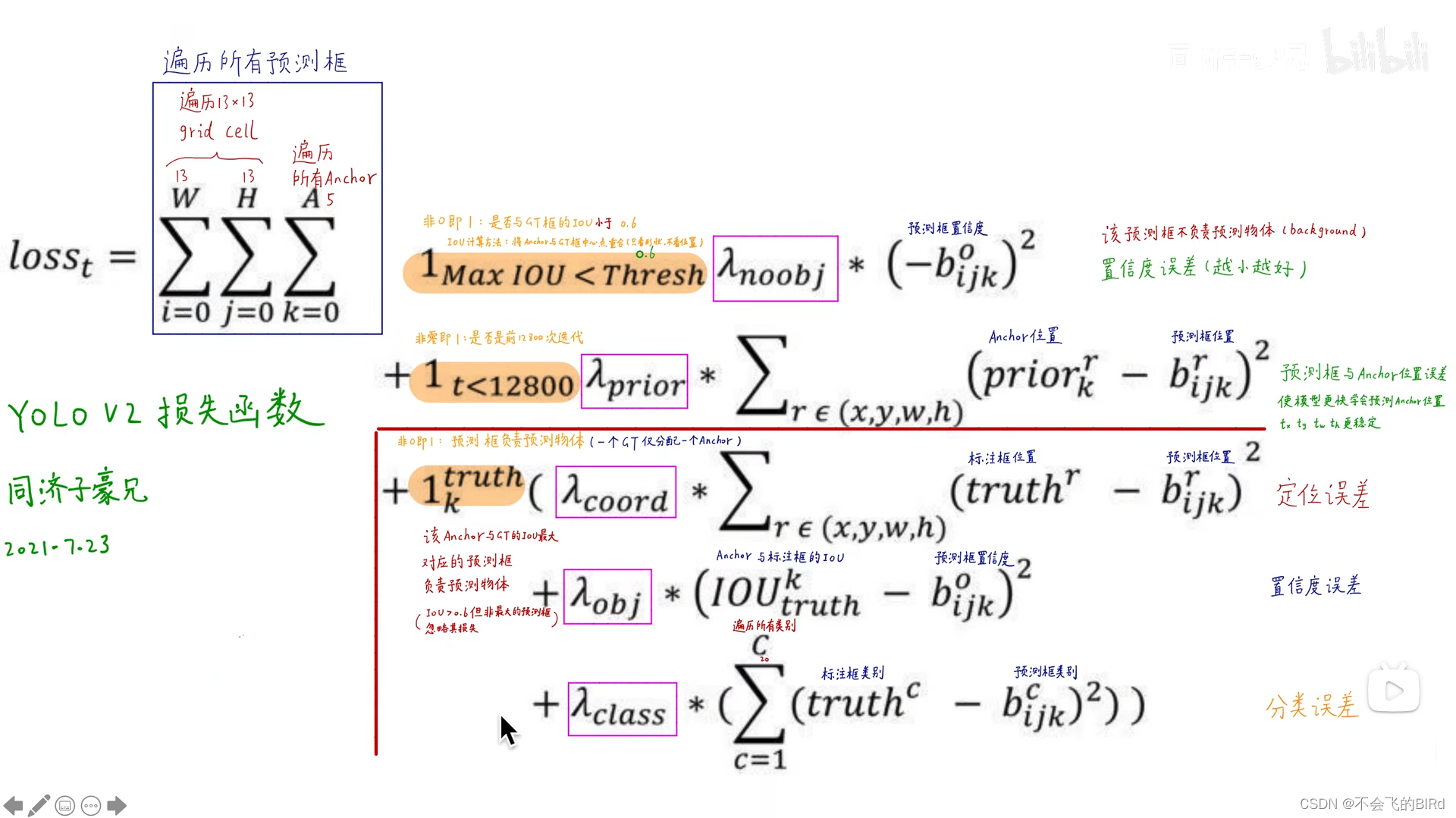
2.损失函数
遍历图像中的每一个预测框(误差来源于每个预测框和对应的anchor),损失函数分为三部分:
- 不负责预测物体的预测框:
对比threshold和最大IOU(将ground truth的中心点和预测框的中心点对齐后计算IOU),如果IOU小于threshold(说明这个预测框不预测任何物体),则计算真实置信度(由于不负责预测任何物体,因此值为0)与预测置信度的误差(由于真实的标签为0,所以该项误差越接近0越好) - 训练初期:
为了尽快让预测框接近anchor的形状(更好地各司其职,去预测不同类型的物体),计算预测框与anchor的误差,让它越小越好 - 负责预测物体的预测框:
与V1类似,分别计算定位误差、置信度误差和分类误差
以下图像来自b站 同济子豪兄
3.细粒度的类别
通用目标检测数据集(例如COCO)都没有具体的类别(抹香鲸、虎鲸、座头鲸…),但是YOLO9000可以检测出具体的细粒度的类别:
这得益于YOLO9000将图像分类数据集(Image-Net)和目标检测数据集(COCO)进行联合训练:
利用 WordTree 层次结构组合数据集。利用 WordNet 概念图,建立视觉概念的层次树。然后,通过将数据集中的类映射到树中的同义词集,就可以将数据集合并在一起:
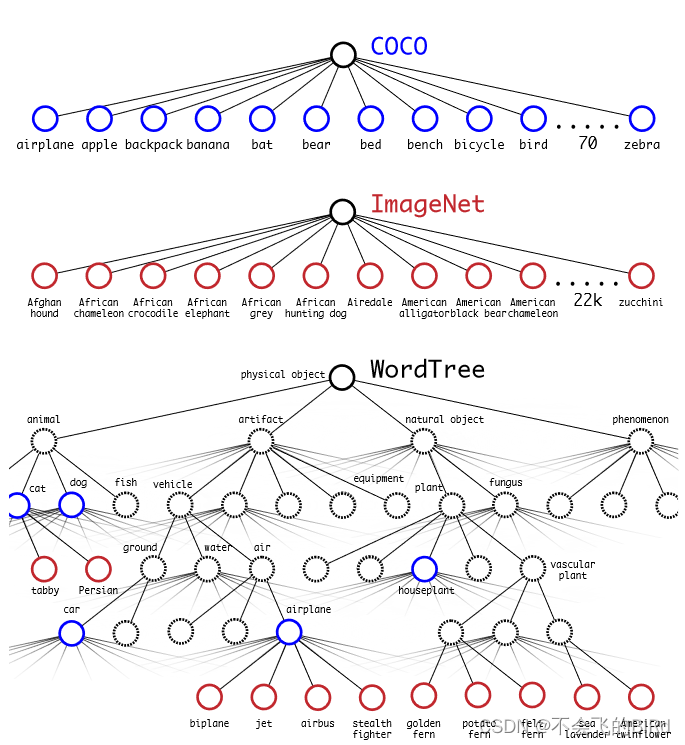
在训练中,如果遇到的的是分类数据,则训练分类属性;如果是检测数据,则训练检测能力
5.算法缺点
- 定位精度有限:由于YOLOv2的回归框是根据网格的位置和大小进行预测的,所以对于小目标或者目标尺度变化较大的情况,定位精度可能会受到一定影响。
- 对密集目标的处理较弱:由于YOLOv2在每个网格只预测有限数量的边界框,对于密集目标的检测可能不够准确,容易发生漏检或重复检测的情况。
- 对长宽比不同的目标不敏感:YOLOv2中的边界框预测是固定的,没有考虑目标的长宽比差异,因此在面对长条状目标或者宽度明显大于高度的目标时,检测结果可能不够准确。
- 目标大小要求较高:YOLOv2对目标的最小尺寸要求较高,对于过小的目标可能无法进行有效检测。















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









