






问题
前段时间一直被困扰,为何beam类的结果这么差,还以为代码出了问题:

发现
后来在CBL论文里也发现了这个问题:
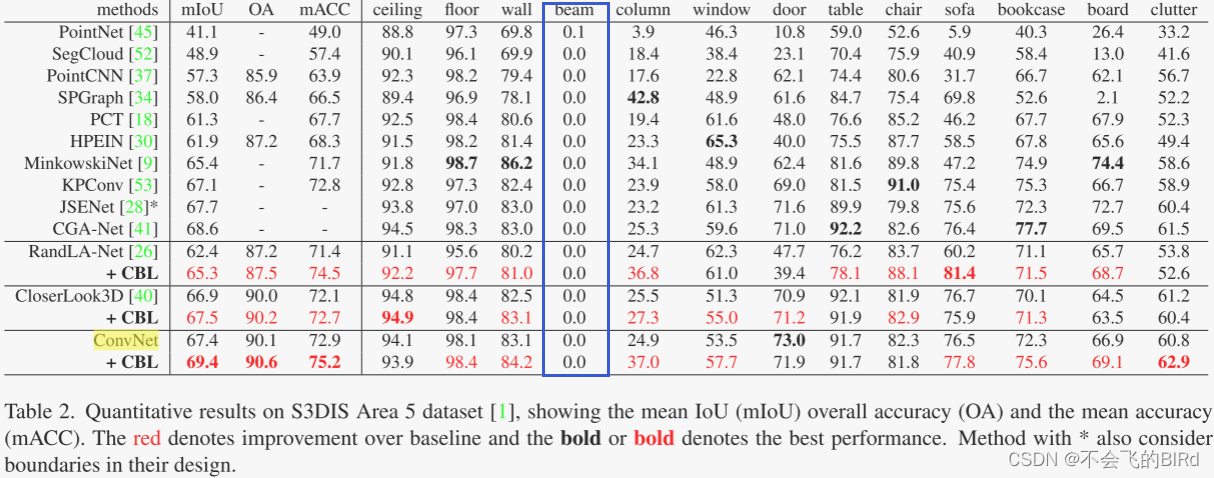
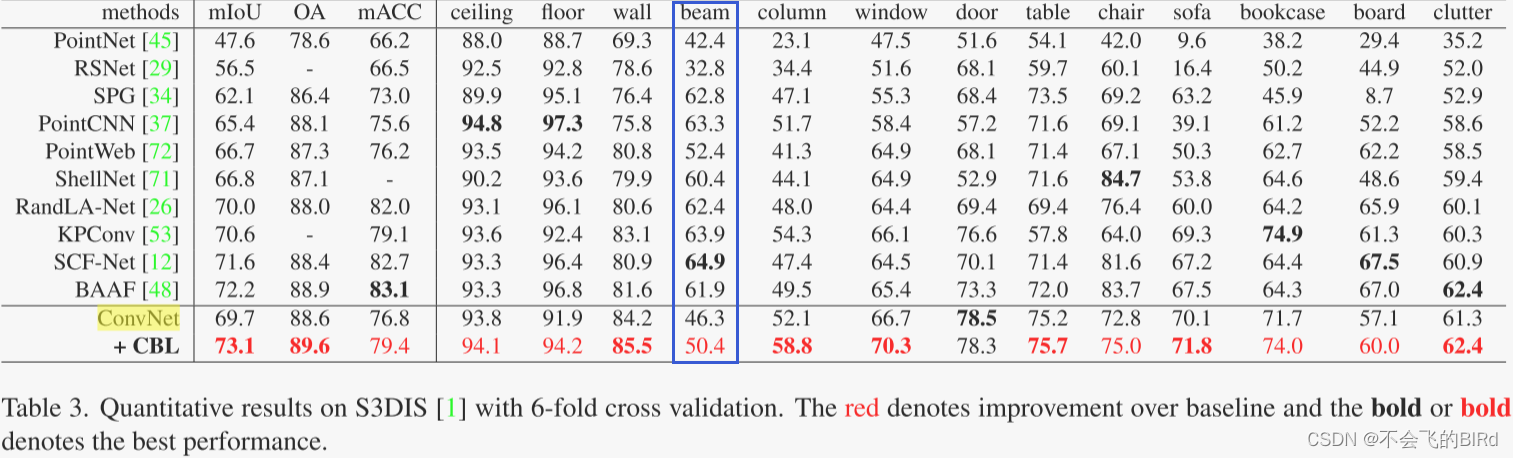
解谜
感觉应该是Area5 中beam的样本太少了,于是就去Area5 里查了一下,结果就是这样子:
首先看了正常样本(table为例):
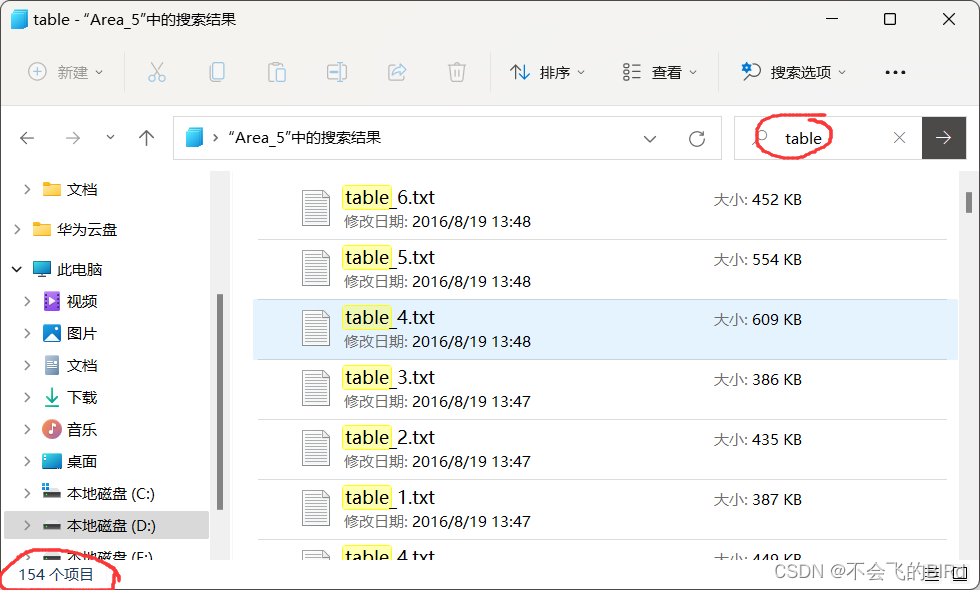
发现有154个文件用来标注,每个文件里有3000~46000个语义为桌子的点。
接下来再看看beam:
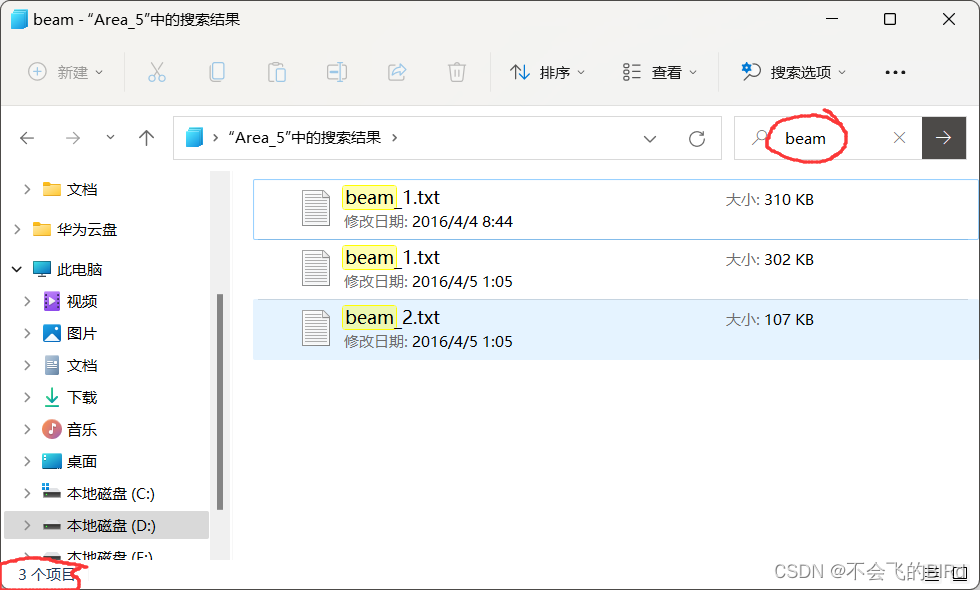
发现一共只有3个文件,总计加起来只有9497+9520+3410 = 22472个类别为beam的点。
定论
ok破案了:
原因是数据不平衡,也就是在特定区域(area5)中beam类的样本数量非常少。如果在训练集中beam类的实例非常少或者完全没有,模型可能就无法学习到如何正确识别该类别,导致在验证时IoU为0。
进行6折交叉验证时,模型在不同的数据子集上进行训练和验证,这样可以确保每个类别在某些折中有足够的表示。这意味着即使area5中beam类的样本很少或者标注有问题,其他区域的数据可以帮助模型学习到beam类的特征,从而在整体的6折交叉验证中得到正常的IoU值。















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









