







AutoDis 一文小结
这篇文章介绍了AutoDis,一个创新的框架,旨在解决推荐系统中点击率(CTR)预测的一个关键问题:如何有效地嵌入数值特征。在现有的CTR预测模型中,数值特征的嵌入通常受限于固定数量的参数,导致模型无法充分捕捉特征之间的复杂交互,或者依赖于无法与模型目标共同优化的硬离散化规则。
要解决的问题:
-
现有模型通常忽视了嵌入模块在处理数值特征时的重要性。
-
数值特征的传统嵌入方法(如规范化和离散化)存在性能瓶颈,例如低容量问题、两阶段问题(TPP)、相似值但不同嵌入(SBD)和不同值但相同嵌入(DBS)。
文章的创新点:
-
端到端优化:AutoDis框架首次实现了与CTR模型的最终目标联合优化数值特征的离散化过程。
-
连续但不同:提出了一种新的嵌入表示方式,保证了不同数值特征值的嵌入表示既连续又具有差异性,增强了模型对细微特征变化的捕捉能力。
-
元嵌入:引入了元嵌入的概念,为每个数值字段设计一组共享的元嵌入,以高效地学习字段内特征值间的关系。
-
自动微分离散化和聚合方法:提出了一种自动的、可微分的离散化方法,以及一种加权平均聚合函数,用于捕获数值特征与元嵌入之间的相关性,并生成信息丰富且连续的嵌入表示。
-
实验验证:通过在多个数据集上的实验,验证了AutoDis在CTR预测任务中的有效性,以及与多种深度CTR模型的兼容性。
文章通过AutoDis框架,为数值特征的嵌入学习提供了一种全新的视角,推动了CTR预测技术的发展。
Abstract
在推荐系统中,对复杂特征交互的学习对于点击率(CTR)预测至关重要。各种深度CTR模型都遵循了“Embedding & Feature Interaction paradigm”的模式。大多数研究集中在Feature Interaction的网络架构设计上,以更好地模拟特征间的交互,但却忽视了作为数据与特征交互模块间瓶颈的嵌入模块。数值特征嵌入的常规方法包括规范化(Normalization)和离散化(Discretization)。规范化方法在字段内部特征之间共享单一嵌入,而离散化方法则通过不同的离散化策略将特征转换为分类形式。然而,规范化方法因表示能力有限而受限,而离散化方法也因无法与CTR模型的最终目标同步优化而影响性能。为了填补在数值特征表示方面的空白,本文提出了AutoDis,这是一个自动离散化数值字段中特征,并与CTR模型以端到端方式联合优化的框架。
具体来说,我们为每个数值字段引入了一组元嵌入(meta-embeddings),用以模拟字段内特征之间的关系,并提出了一种自动可微分的离散化和聚合方法,以捕获数值特征与元嵌入之间的相关性。我们在两个公共和一个工业数据集上进行了全面实验,以证明AutoDis相较于现有最先进方法的有效性。
Introduction
为了缓解信息爆炸的问题,推荐系统被广泛部署,以在网络信息服务中提供个性化的信息过滤,例如网络搜索、新闻推荐和在线广告。在推荐系统中,点击率(CTR)预测至关重要,它需要估计用户在特定情境下点击推荐项目的概率,以便可以根据预测的CTR值做出推荐决策(McMahan等人,2013年;Zhou等人,2018年;Wang等人,2020年)。
由于在计算机视觉和自然语言处理中特征表示的卓越性能,深度学习技术吸引了推荐系统的广泛关注。因此,许多工业公司提出了各种深度CTR模型,并在他们的商业系统中进行了部署,例如Google Play中的Wide & Deep(Cheng等人,2016年)、华为应用市场中的DeepFM(Guo等人,2017年)、淘宝中的DIN(Zhou等人,2018年)。
大多数现有的深度CTR模型都遵循了嵌入(Embedding)和特征交互(Feature Interaction,FI)的范式。由于特征交互在CTR预测中的重要性,大部分研究工作集中在FI模块的网络架构设计上,以更好地建模显式或隐式的特征交互,例如Wide & Deep中的宽组件(Cheng等人,2016年)、DeepFM中的FM组件(Guo等人,2017年)以及DIN中的注意力机制(Zhou等人,2018年)。尽管文献中对此研究不多,嵌入模块也是深度CTR模型的一个关键因素,原因有二:1)嵌入模块是随后FI模块的基石,直接影响FI模块的有效性(Zhang, Du, 和 Wang 2016年;Liu等人,2020c);2)深度CTR模型中的参数大量集中在嵌入模块,自然对预测性能有很高的影响(Joglekar等人,2019年)。然而,研究界忽视了嵌入模块,这促使我们进行深入研究。
嵌入模块以查找表的方式工作,将输入数据的每个特征,无论是在分类字段还是数值字段,都映射到具有可学习参数的潜在嵌入空间(Zhou等人,2019b)。以一个示例实例为例(Gender=Male, Day=Tuesday, Height=175.6, Age=18),分类字段Gender中的特征通过为每个单独的特征分配一个独特的嵌入来简单地映射到嵌入,这在现有工作中被广泛使用(Guo等人,2017年;Qu等人,2019年)。不幸的是,这种分类策略不能用于处理数值特征,因为数值字段中可能存在无限多的特征值(例如Height)。为了解决这个问题,从业者通常会采用规范化(Guo等人,2017年;Song等人,2019年)或离散化方法(Qu等人,2019年)。然而,前者可能导致性能不佳,因为每个字段中的特征共享单一嵌入,导致表示能力的低下。后者也限制了性能,因为这种基于启发式的离散化规则无法与CTR模型的最终目标一起优化,这后面被称为TPP(Two-Phase Problem,两阶段问题)。此外,通过离散化方法学习到的嵌入遭受SBD问题(Similar value But Dis-similar embedding,相似值但不同嵌入)和DBS问题(Dis-similar value But Same embedding,不同值但相同嵌入)。例如,在Age字段中应用离散化的常用策略是确定[18,40]为青少年桶,[41,65]为中年桶,这导致:1) 数值40和41具有显著不同的嵌入(SBD问题);2) 18到40之间的数值具有相同的嵌入(DBS问题)。
为了实现这两项进步,在AutoDis中,我们精心设计了一套元嵌入(meta-embeddings)为每个数值字段,这些元嵌入在字段内所有特征值之间共享。元嵌入学习该字段内不同特征值之间的关系,同时只用数量可控的嵌入参数。使用元嵌入能够避免简单地为每个数值特征分配独立嵌入时引入的参数爆炸问题。此外,数值特征的嵌入被设计为在共享的元嵌入上的可微分聚合,这使得数值特征的离散化能够以端到端的方式与深度CTR模型的最终目标一起优化。总结来说,这项研究工作的主要贡献如下所列。
Preliminary
-
Deep CTR prediction
大多数现有的深度CTR模型遵循嵌入(Embedding)和特征交互(Feature Interaction,FI)的范式。嵌入模块将输入特征映射到低维嵌入空间。基于这些可学习的嵌入,FI模块模拟隐式和显式的低阶和高阶特征交互,并通过学习特征间的进一步非线性关系来拟合目标。下面,我们将简要介绍深度CTR模型中的这些模块。
-
Embedding
嵌入作为深度CTR模型的基石,嵌入模块对模型性能有着重大影响,因为它占据了模型参数的大部分。现有的研究主要集中在通过为不同特征分配可变长度嵌入或多嵌入来设计适应性嵌入算法,如Mixed-dimension(Ginart等人,2019年)、NIS(Joglekar等人,2019年)和AutoEmb(Zhao等人,2020年)。然而,这些方法只能以查找表的方式应用于分类特征或离散化后的数值特征。很少有研究关注数值特征的自动化嵌入学习,这在工业界的深度CTR模型中至关重要。
-
Feature Interaction
为了有效地捕获特征交互,CTR预测的研究社区提出了不同的网络架构,例如DeepFM中的FM组件(Guo等人,2017年)、xDeepFM中的CIN(Lian等人,2018年)以及DIN中的注意力机制(Zhou等人,2018年)。我们根据模型对特征交互的建模方式对现有模型进行分类。
-
仅隐式(Only-Implicit):仅基于可学习的嵌入直接建模隐式特征交互,例如FNN(Zhang, Du, 和 Wang 2016年)。
-
显式直接(Explicit-Direct):同时建模显式和隐式特征交互。显式和隐式交互通过基于乘积的组件和MLP(多层感知机)并行建模。注意,显式交互在不经过MLP的情况下直接输入最终预测。Wide & Deep(Cheng等人,2016年)、DeepFM(Guo等人,2017年;2019年)、AFM(Xiao等人,2017年)、DCN(Wang等人,2017年)和AutoFIS(Liu等人,2020b年)就是这样的例子。
-
显式MLP(Explicit-MLP):同时建模显式和隐式特征交互。显式交互通过一个特殊网络建模,然后连接到MLP。最后,MLP的输出作为最终预测。IPNN(Qu等人,2016年)、DIN(Zhou等人,2018年)、DIEN(Zhou等人,2019a年)、xDeepFM(Lian等人,2018年)、PIN(Qu等人,2019年)、FGCNN(Liu等人,2019年)、FiBiNET(Huang, Zhang, 和 Zhang 2019年)、AutoInt(Song等人,2019年)和AutoGroup(Liu等人,2020a年)属于这一类。
什么是显示、什么是隐式?
在机器学习和特别是深度学习中,"显式"(Explicit)和"隐式"(Implicit)这两个术语通常用来描述特征交互(Feature Interactions)的两种不同类型:
显式交互(Explicit Interactions):
显式交互指的是在模型设计中明确定义和建模的特征之间的关系。这种交互通常是可解释的,模型开发者有意识地将某些特征组合在一起,以期望模型能够捕捉到这些特征之间的直接关系。
在CTR预测中,显式交互可能是基于领域知识设计的,例如,某些特征的组合(如用户的年龄和性别)可能会直接影响用户对广告的点击概率。
显式交互可以通过特定的网络结构或算法来建模,例如通过产品化操作、特征交叉或特定的网络层来实现。
隐式交互(Implicit Interactions):
隐式交互指的是模型在学习过程中自动捕捉的特征之间的关系,而不是由模型设计者预先定义的。这种交互通常是不可解释的,因为它是通过模型的隐层自动学习得到的。
在深度学习模型中,隐式交互通过嵌入向量和多层感知机(MLP)等结构来实现,模型通过这些结构学习特征之间的复杂和非线性关系。
例如,在深度神经网络中,隐式交互可以通过嵌入层和后续的隐藏层自动学习,无需显式地定义特征如何交互。
在CTR预测模型中,显式和隐式交互的结合可以帮助模型更全面地理解数据中的模式和关系,从而提高预测的准确性。一些模型可能只关注显式交互或隐式交互,而其他模型则可能同时包含这两种类型的交互来增强模型的表达能力。
Methodology
在本节中,我们首先对现有表示数值特征的方法进行了详细分析,并阐明了它们的局限性。然后,我们介绍了我们提出的AutoDis框架,并解释了其训练细节。
-
Existing Methods for Numerical Features
图1展示了将数值特征(例如年龄)映射到潜在嵌入空间的三种方法:
-
分类(Categorization):类似于分类特征,每个数值特征可以被视为一个单独的分类特征,并分配一个独特的嵌入。
-
规范化(Normalization):同一字段中的所有数值特征共享一个单一的嵌入,并且与它们的值进行标量乘法(Guo等人,2017年;Song等人,2019年)。
-
离散化(Discretization):它通过将数值特征值通过不同的策略分桶(Qu等人,2019年),将它们转换为分类形式,然后为每个单独的桶分配一个独特的嵌入。
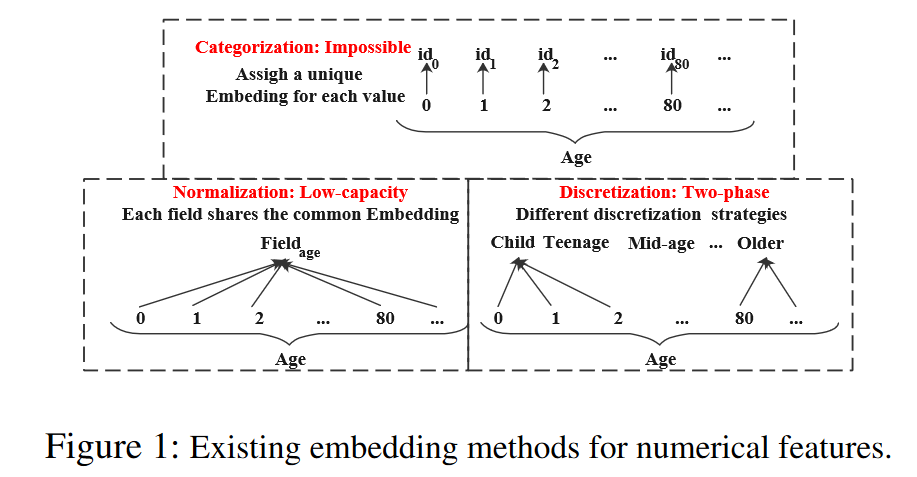
数值字段中可能存在无限多的特征值,因此应用分类(Categorization)会引入数量巨大的嵌入参数,这在实践中是无法承受的。此外,规范化(Normalization)限制了嵌入的表示能力,因为同一字段中不同特征的嵌入彼此之间是线性相关的。因此,由于这些严重的限制,这两种方法在现实世界的应用中都不切实际。
-
Discretization
现有的工业推荐系统通过采用离散化处理数值特征,将数值特征转换为类别特征,通过各种启发式离散化策略实现。我们总结了以下三种广泛使用的方法:
-
EDD/EFD:EDD将特征值的范围划分为k个等宽的桶,其中k是桶的数量。形式上,特征值的范围是[Min, Max],然后区间宽度w定义为w = (Max - Min) / k。相应地,可以通过v ← floor((v - Min) / w)得到特征值的桶。类似地,EFD将范围[Min, Max]划分为几个桶,使得每个桶大约包含相等数量的特征值。
-
LD:Kaggle竞赛中Criteo广告预测任务的冠军团队利用对数和floor操作将数值特征转换为类别形式:v ← floor(log(v)^2)。
-
TD:除了深度学习模型外,基于决策树的模型(如GBDT)在推荐系统中被广泛使用,因为它们能够有效处理数值特征。因此,许多基于树的方法被用来对数值特征进行离散化(He et al. 2014; Ke et al. 2019; Grabczewski and Jankowski 2005)。
-
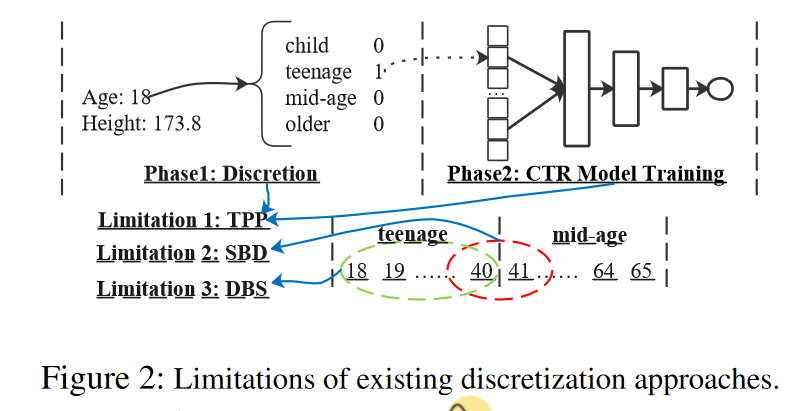
Limitation of Discretization
尽管离散化方法在工业场景中得到了广泛应用(Qu et al. 2019; He et al. 2014),但它们仍然存在三个限制(如图2所示):TPP(双阶段问题),SBD(相似值但不同嵌入)和DBS(不同值但相同嵌入)。
-
TPP:离散化过程是由启发式规则或另一个模型决定的,因此它不能与CTR预测任务的最终目标一起优化,导致次优性能。
-
SBD:这些离散化策略可能会将相似的特征(边界值)划分到两个不同的桶中,因此它们之后的嵌入会显著不同。例如,常用的年龄字段离散化方法是将[18,40]确定为青少年,[41,65]为中年,这导致数值40和41的嵌入显著不同。
-
DBS:现有的离散化策略可能会将明显不同的元素分组到同一个桶中,导致相同的嵌入。使用相同的示例,18岁和40岁之间的数值在同一个桶中,因此被分配了相同的嵌入。然而,18岁和40岁的人很可能具有非常不同的特征。这些策略无法有效描述特征变化的连续性。
AutoDis Framework
为了解决现有方法的局限性,我们提出了AutoDis,它能够以端到端的方式自动学习数值特征的嵌入,并且与现有的深度CTR模型兼容。我们首先描述AutoDis如何与当前的深度CTR模型协同工作。然后,我们将详细阐述AutoDis中的三个核心模块。
-
Framework Overview
如图3所示,AutoDis作为嵌入层的一个组件工作,并为每个数值特征学习独特的嵌入。一个实例x被表示为一个向量x,它是所有字段中特征表示的串联。
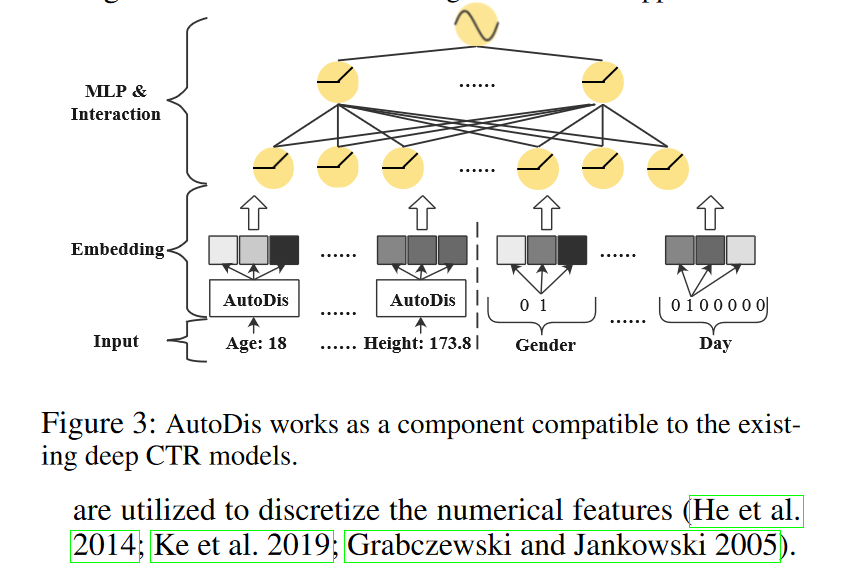
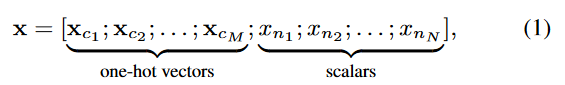
在这个上下文中,x_ci 是第 i 个类别字段中特征值的一位有效向量(one-hot vector),而 x_nj 是第 j 个数值字段的标量值。对于每个类别字段 c_i,可以通过嵌入查找操作获得特征嵌入:e_ci = E_ci * x_ci,其中E_ci 属于n_ci * d 是字段 c_i 的嵌入矩阵,n_ci 和 d 分别是词汇表大小和嵌入大小。

在这里,E_{ci} 是属于字段 c_i 的嵌入矩阵,其尺寸为 R^n_ci * d,其中 n_ci 是词汇表的大小,而 d 是嵌入的维度。对于数值字段 n_j,AutoDis 可以通过以下方式为每个特征值学习一个独特的嵌入:e_nj = f(g(x_nj), M_Enj),这里 M_Enj 是字段 n_j 的元嵌入矩阵,g(.) 是自动离散化函数,而 f(.) 是聚合函数。
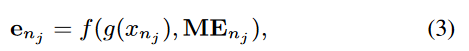
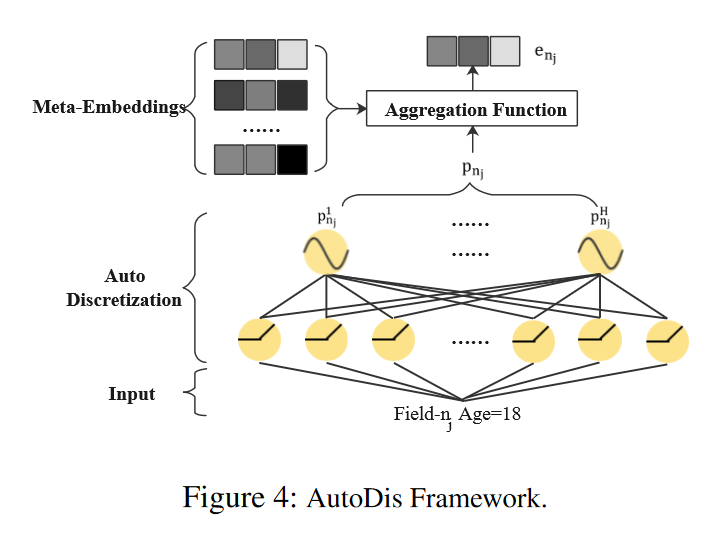
在这里,M_Enj 是字段 n_j 的元嵌入矩阵,g(.) 是自动离散化函数,而 f(.) 是聚合函数。AutoDis 的具体架构在图4中展示。最终,类别特征和数值特征的嵌入被串联起来,输入到深度CTR模型中进行预测:hat{y} = CTR(e_c1, e_c2, ..., e_cM; e_n1, e_n2, ..., e_nN)。这里 e_ci 表示第 i 个类别特征的嵌入,而 e_nj 表示第 j 个数值特征的嵌入。
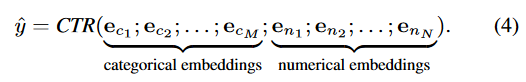
总结一下上面的内容:
Framework Overview 介绍:
AutoDis框架作为一个嵌入层的组件,其目标是为每个数值特征自动学习独特的嵌入表示。这个过程是端到端的,意味着数值特征的离散化可以与深度CTR(Click-Through Rate,点击率)模型的最终目标一起优化。AutoDis的设计允许它与现有的深度CTR模型兼容,并且可以作为一个即插即用的模块来增强这些模型的性能。
详细说明:
实例表示:假设有一个实例x,它在不同的字段中有不同的特征值。x被表示为一个向量,该向量是所有字段中特征表示的串联。例如,如果一个实例具有性别(Gender)、年龄(Age)和身高(Height)这三个特征,那么x可以表示为:
x = [x_c1; x_c2; ...; x_cM; x_n1; x_n2; ...; x_nN]
其中x_ci是性别字段的一位有效向量,x_nj是年龄和身高字段的标量值。
嵌入查找:对于类别字段(categorical field),例如性别,每个特征值通过嵌入查找表获得其嵌入表示。例如,如果性别字段有"Male"和"Female"两个可能的值,那么每个值都会有一个对应的嵌入向量。
元嵌入(Meta-Embeddings):对于数值字段(numerical field),如年龄或身高,AutoDis不是为每个可能的数值分配一个独立的嵌入,而是为每个数值字段设计了一组元嵌入。这些元嵌入能够捕捉字段内不同特征值之间的关系。
自动离散化:AutoDis通过一个自动离散化函数g(.)将数值特征值映射到这些元嵌入上。这个函数为每个数值特征值生成一个与元嵌入相关联的权重向量。
聚合函数:然后,AutoDis使用一个聚合函数f('),根据自动离散化函数生成的权重,对元嵌入进行加权聚合,生成每个数值特征值的最终嵌入表示。
模型训练与预测:所有类别和数值特征的嵌入被串联起来,作为一个整体输入到深度CTR模型中进行训练和预测。模型的目标是通过最小化损失函数来学习嵌入和CTR模型的参数。
通过这种方式,AutoDis框架能够为数值特征提供更加丰富和连续的嵌入表示,从而提高了CTR预测的性能。
具体示例:
假设我们有一个在线广告点击率(CTR)预测任务,特征包括用户的年龄(Age)和用户每天的点击次数(Clicks)。年龄是一个数值字段,而点击次数是一个数值字段。
步骤详解:
实例表示:
假设实例 x 包含用户的年龄为 25 岁,一天内的点击次数为 10 次。在 AutoDis 中,这些特征将被表示为向量:
x = [x_c1, x_n1]
其中 x_c1 是其他类别特征的一位有效向量表示,x_n1 分别是年龄和点击次数的标量值。
嵌入查找:
对于年龄这个数值字段,我们不使用传统的一位有效编码,而是使用 AutoDis 来生成嵌入。
元嵌入(Meta-Embeddings):
AutoDis 为年龄字段创建一组元嵌入,假设有 10 个元嵌入 M_En1,每个元嵌入都是一个向量,这些元嵌入共同表示年龄字段的可能值范围。
自动离散化:
自动离散化函数 g(x_n1) 将用户的实际年龄 25 映射到这些元嵌入上。这通过计算年龄与每个元嵌入之间的相关性来完成,生成一个权重向量,例如:
g(25) = [p_1, p_2, ..., p_10]
这里 p_i 表示年龄 25 与第 i 个元嵌入的相关性。
聚合函数:
使用聚合函数 f(.),例如加权平均,根据权重向量 [p_1, p_2, ..., p_10] 对元嵌入进行聚合,生成年龄 25 的嵌入表示:
模型训练与预测:
将年龄的嵌入e_n1 和其他特征的嵌入 x_c1 串联起来,形成最终的输入向量,输入到深度CTR模型中进行训练和预测:
-
Meta-Embeddings
如前所述,分类方法为每个数值特征值分配一个独特且独立的嵌入,这引入了大量参数,实际上是不可能的。此外,归一化方法降低了模型性能,因为它在字段内的不同特征值之间共享相同的嵌入,导致不同特征嵌入之间的线性关系。我们不是使用独特的嵌入或单个共享嵌入来处理不同的特征值,而是为每个字段nj设计了一组元嵌入M_Enj in R}^{H_j * d} ,其中 H_j 是字段nj中的元嵌入数量。因此,数值特征嵌入可以表示为元嵌入的组合。通过这种设计,学习到的嵌入比归一化方法包含更多信息,因为学习到的嵌入的线性关系被扩展到了非线性。而且,这种元嵌入所需的参数远少于分类方法。
-
Automatic Discretization
自动离散化(Automatic Discretization)是AutoDis框架中的一个核心概念,它允许模型自动将数值特征划分为不同的区间或“桶”,每个区间用一个元嵌入向量表示。这个过程是自动进行的,并且与CTR模型的最终目标联合优化。以下是自动离散化的翻译:
自动离散化(Automatic Discretization)是AutoDis框架的核心组成部分,它使模型能够自动地将数值特征划分为不同的区间或“桶”,每个桶由一个元嵌入(meta-embedding)表示。这一过程是自动执行的,并且与CTR预测模型的最终目标一起进行端到端的优化。
在自动离散化中,数值特征值首先被映射到元嵌入上,通过一个自动离散化函数 \( g(\cdot) \) 来实现,该函数为每个数值特征生成一个与元嵌入相关联的权重向量。然后,这些权重用于通过聚合函数来组合元嵌入,形成每个数值特征的最终嵌入表示。这种方法克服了传统离散化方法的一些限制,如两阶段问题(TPP)、相似值但不同嵌入(SBD)和不同值但相同嵌入(DBS),从而提高了模型的性能和数值特征表示的连续性。
通过这种方式,AutoDis能够为数值特征生成更加丰富和连续的嵌入表示,同时避免了传统离散化方法可能导致的“不相似值但相同嵌入”(DBS)和“相似值但不同嵌入”(SBD)的问题。
概率p是如何计算的?

-
Aggregation Function
聚合函数(Aggregation Function)是AutoDis框架中用于将元嵌入(meta-embeddings)根据相关性权重组合起来生成最终嵌入表示的方法。以下是不同类型聚合函数的翻译:
-
Max-Pooling:选择与特征值相关性最高的元嵌入作为最终嵌入。
-
Max-Pooling: Selects the most relevant meta-embedding with the highest correlation as the final embedding.
-
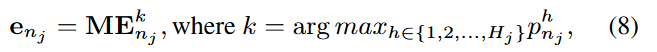
-
Top-K-Sum:选择相关性最高的K个元嵌入,将它们相加作为最终嵌入。
-
Top-K-Sum: Sums up the top-K meta-embeddings with the highest correlations to form the final embedding.
-
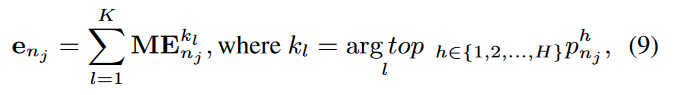
-
Weighted-Average:使用所有元嵌入,但是根据它们与特征值的相关性进行加权平均,得到最终嵌入。
-
Weighted-Average: Utilizes all meta-embeddings and aggregates them into the final embedding by applying a weighted average based on their correlation values with the feature value.
-
这些聚合函数的选择直接影响模型的性能,因为它决定了如何利用元嵌入集合来表示每个数值特征。Weighted-Average聚合函数因其灵活性和能够综合考虑所有元嵌入的相关性而在实践中通常表现更佳。
AutoDis是对归一化(normalization)和现有离散化方法的概括和扩展。特别是,在方程6中当温度参数 t 趋向于无穷大时,Softmax分布变得均匀,导致AutoDis退化为简单的归一化策略。而当 t 趋近于0时,Softmax分布变得趋向于一位有效(one-hot),此时AutoDis转化为一种特定的离散化策略。
-
Normalization
为了确保训练稳定性,我们采用了特征归一化技术,将数值特征值缩放到[0, 1]区间。第j个数值字段的数值特征值 x_nj 被归一化如下:
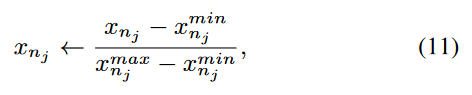
-
training
AutoDis与具体的深度CTR模型的最终目标一起以端到端的方式进行训练。损失函数是广泛使用的LogLoss,加上一个正则化项,定义如下:
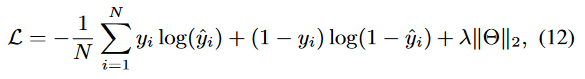
其中 y_i 和 hat_y_i 分别是第i个实例的真实标签和估计值。N是训练实例的总数,λ是L2正则化权重。Θ包含分类字段特征嵌入的参数、AutoDis中的元嵌入和自动离散化函数的参数,以及深度CTR模型的参数。
![]()
Experiments
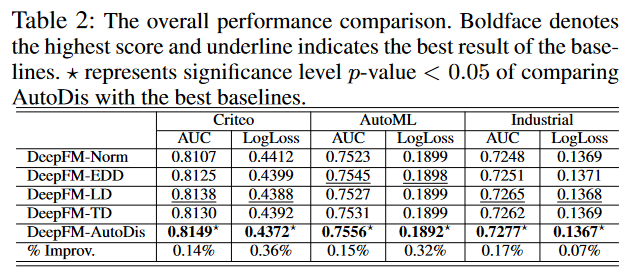
作者们在两个流行的基准数据集Criteo和AutoML以及一个工业数据集上进行了实验,以评估AutoDis的自动化离散框架。实验设置包括了数据集的统计描述,基线模型的选择,以及评估协议的说明。使用了AUC(Area Under the ROC Curve)和LogLoss作为主要的性能评估指标,并对所有实验进行了5次重复以确保结果的可靠性和统计显著性。
在与其他嵌入方法的比较中,AutoDis在所有数据集上均展现出了优越的性能,显著提高了CTR预测的准确性。与归一化方法相比,AutoDis在AUC指标上取得了一致的改进。此外,与其他几种代表性的离散化方法相比,AutoDis在处理数值特征时也显示出了更好的性能,克服了传统方法中的SBD(相似值但不同嵌入)和DBS(不同值但相同嵌入)问题。
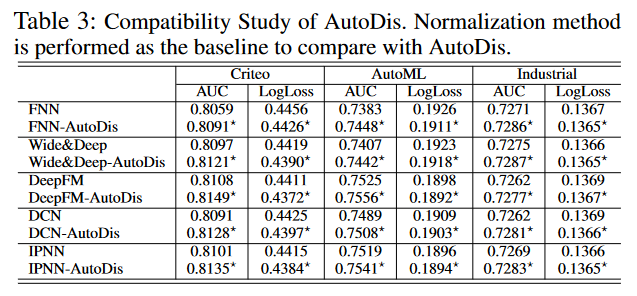
为了展示AutoDis与不同深度CTR模型的兼容性,作者们将其应用于多个流行的模型,包括FNN、Wide & Deep、DeepFM、DCN和IPNN。实验结果表明,AutoDis能够显著提升这些模型的预测性能,证明了其作为一种通用框架的有效性。
此外,作者们还进行了深入的嵌入分析,包括宏观分析和微观分析,以及对模型复杂度、不同聚合策略的影响、温度系数的敏感性以及元嵌入数量的深入研究。这些分析进一步证明了AutoDis学习到的嵌入的连续性,以及其对模型性能的积极影响。
最后,作者们得出结论,AutoDis通过自动化的离散化和嵌入学习,有效地提高了CTR预测的性能,并且与现有的深度CTR模型兼容,为未来的推荐系统模型提供了一个有力的工具。
Embedding Analysis
作者们深入探讨了AutoDis学习到的嵌入表示的特性,通过宏观分析和微观分析来理解这些嵌入如何捕捉数值特征的连续性。以下是该部分的总结:
-
宏观分析(Macro-Analysis):通过使用t-SNE技术将高维嵌入投影到二维空间,作者们可视化了AutoDis和EDD(等宽离散化)方法得到的嵌入。观察到AutoDis为相似的数值特征值学习到了相互接近的嵌入,而EDD方法则将同一桶内的所有特征值映射为相同的嵌入,导致无法区分不同数值的特征。

-
微观分析(Micro-Analysis):进一步地,作者们分析了Softmax得分在元嵌入中的分布情况,特别是对于Criteo数据集中第11个数值字段的相邻特征对和相隔较远的特征对。结果表明,相邻特征值具有相似的Softmax分布,而相隔较远的特征值则具有不同的分布,这有助于AutoDis学习到连续的嵌入表示。
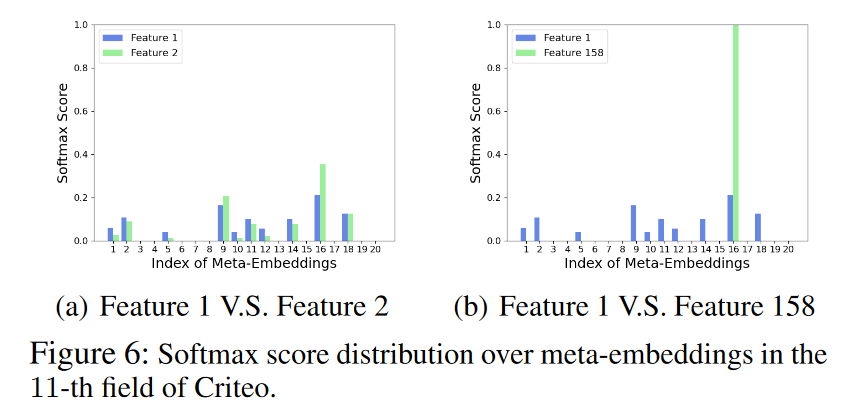
-
数值字段分析(Numerical Fields Analysis):作者们还评估了AutoDis对每个数值字段的影响,通过逐步添加数值字段并观察模型性能的变化。结果表明,即使只有一个数值字段,AutoDis也能提升性能,并且在多个数值字段上具有累积性能提升。
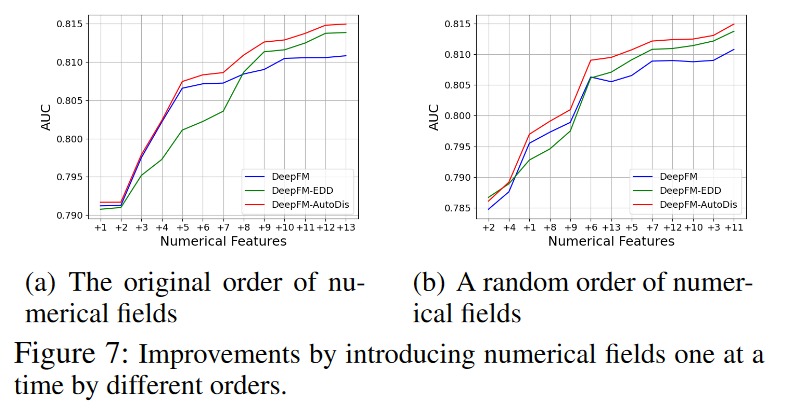
-
模型复杂度(Model Complexity):在对AutoDis的空间和时间复杂度进行分析时,作者们发现与EDD方法相比,AutoDis增加的模型参数量是微不足道的,并且作为一个端到端的框架,没有额外的效率开销。
-
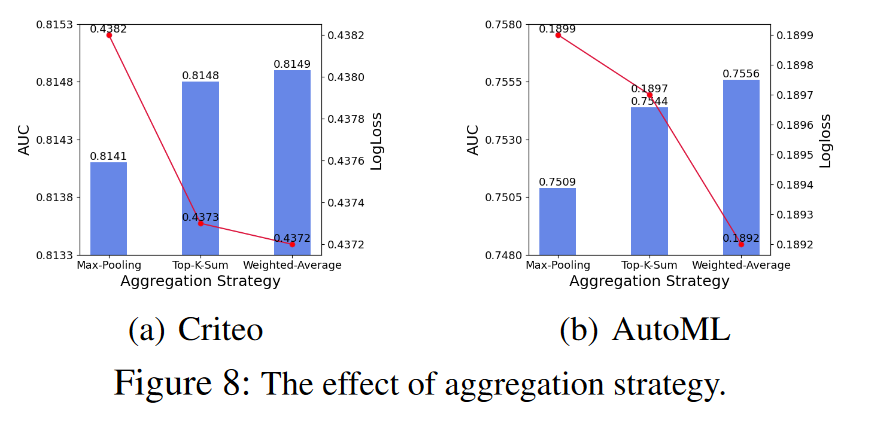
消融研究和超参数敏感性(Ablation Study and Hyper-Parameters Sensitivity):作者们对不同的聚合策略进行了消融研究,并研究了温度系数和元嵌入数量对模型性能的影响。发现加权平均聚合策略表现最佳,并且确定了最优的温度系数范围和元嵌入数量。
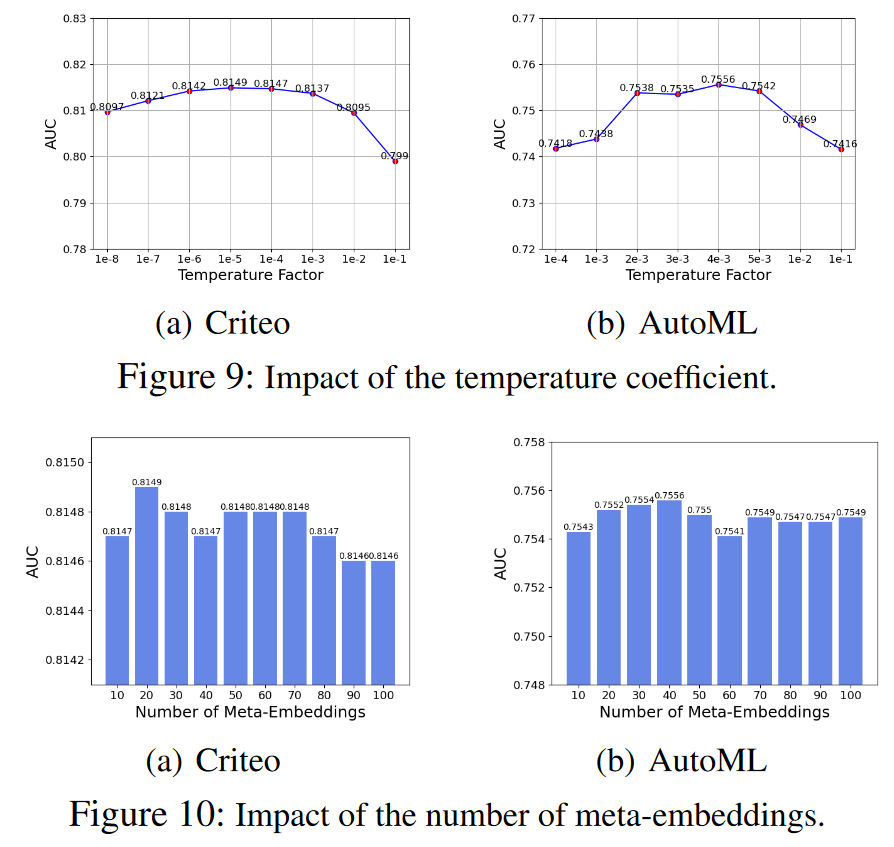
通过这些分析,作者们证明了AutoDis学习到的嵌入不仅能够保持数值特征的连续性,还能够根据不同特征值的相关性提供信息丰富的表示,从而提高了CTR预测模型的性能。

















 5848
5848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











