







RoBERTa(Robustly Optimized BERT Approach)是由Facebook AI Research在2019年提出的一种自然语言处理模型。它是在Google的BERT模型基础上进行了一系列的改进和优化,以提高BERT在各种自然语言理解任务上的表现。RoBERTa模型的主要改进包括:
-
更多数据:RoBERTa采用了更大的训练数据集,包括160GB的训练文本,而BERT仅使用了16GB的数据。这些数据涵盖了更多的新闻、社区问答、百科等内容,使得模型能够学习到更丰富的语言表征。
-
更大的模型参数量:RoBERTa模型使用了更大的模型参数量,通过使用更多的GPU资源和训练时间,以达到更高的模型性能。
-
更大batch size:RoBERTa在训练过程中使用了更大的batch size,以提高训练效率和模型性能。
-
动态掩码:RoBERTa使用了动态掩码策略,每次输入序列时都会生成新的掩码模式,使得模型能够适应不同的掩码策略,学习到更丰富的语言表征。
-
文本编码:RoBERTa采用了更大的byte级别BPE词汇表,包含50K的词汇,以支持处理自然语言语料库中的众多常见词汇。
通过这些改进和优化,RoBERTa模型在各种自然语言理解任务上取得了更好的性能,完胜了当时所有的后BERT模型。RoBERTa模型的出现,进一步推动了自然语言处理领域的发展,为后续的研究和应用提供了重要的基础。
background
Setup
BERT将两个段落(由多个自然句子组成的序列)作为输入,这两个段落被特殊分隔符分开,作为一个序列输入到BERT中:[CLS],x1,…,xN,…,[SEP],y1,…,yM,…,[EOS]。M和N的限制是M+N < T,其中T是在训练过程中控制最大序列长度的参数。这个模型首先在大量未标记文本语料库上进行预训练,然后在使用端任务标记数据上进行微调。
Architecture
BERT中使用了transformer结构,本节不再做详细介绍。我们使用L表示transformer的网络层数,A表示self-attention,H表示隐藏维度。
Training objectives
在预训练阶段,bert主要使用了以下两种方法:
Masked Language Model (MLM):随机选取输入序列中的 tokens 并将它们替换为特殊的 token [MASK]。MLM 目标是在预测遮蔽的 tokens 时计算交叉熵损失。BERT 均匀地选择输入 token 的 15% 作为可能的替换候选。在选定的 token 中,80% 被替换为 [MASK],10% 保持不变,另外 10% 被随机选择的词汇表 token 替换。
在BERT的原始实现中,遮蔽语言建模任务中的随机遮蔽和替换操作只在一开始的时候对输入序列执行一次。一旦执行过这个操作,被遮蔽的token就不会再改变,它们在随后的训练过程中保持不变。这种做法的目的是为了保持模型的稳定性和可复现性。
Next Sentence Prediction (NSP):NSP是一个二分类损失,用于预测两个段落是否在原始文本中连续出现。正样例是通过从文本语料库中连续取句子创建的。负样例是通过将来自不同文档的段落配对创建的。正样例和负样例以相等概率采样。
NSP目标旨在提高下游任务的性能,如自然语言推理(Bowman et al., 2015),这些任务需要推理关于句子对之间的关系。
Optimization
以下是BERT模型的训练细节:
-
优化器:BERT使用Adam优化器,这是一种普遍使用的优化算法,它结合了AdaGrad和RMSProp的方法,具有两个超参数:β1和β2。β1通常设置为0.9,β2设置为0.999。这些参数控制着梯度更新的速度。此外,还设置了ε = 1e-6的数值稳定性项,以及L2权重衰减(正则化)为0.01。
-
学习率调度:BERT使用一个学习率调度策略,首先在前10,000步内将学习率线性增加到最高值,通常设置为1e-4。之后,学习率会线性衰减,这意味着随着时间的推移,学习率会逐渐减小,帮助模型在训练初期快速适应,并在预训练后期更加精细地调整参数。
-
正则化:BERT通过dropout来防止过拟合。在训练过程中,每个神经元有10%的概率放弃其输出,这有助于模型泛化到未见过的数据。Dropout应用于所有层和注意力权重。
-
激活函数:BERT使用GELU(门控ELU)激活函数作为其隐藏层的激活函数。GELU是一种改进的激活函数,它在数学上与ReLU相似,但在训练速度和性能上有所改进。
-
预训练迭代:模型进行1,000,000次更新,这意味着在整个训练数据集上多次迭代,以学习语言的复杂模式和结构。
-
批量大小和序列长度:BERT在批量中处理256个序列,每个序列的最大长度为512个tokens。批量大小(B)和序列长度(T)的选择会影响模型的训练效率和性能。
这些训练细节共同构成了BERT模型的预训练过程,使其能够在多种自然语言处理任务中表现出色,如文本分类、问答、命名实体识别等。
Data
BERT模型在BOOKCORPUS和英文维基百科上进行了预训练,学习了文本中的语言模式和知识。这些预训练目标包括遮蔽语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)两个任务。
-
BOOKCORPUS:BOOKCORPUS是一个由Zhu等人于2015年提出的小型文本语料库,包含了大约1300本英文电子书的压缩版本。这个语料库被用来训练用于问答系统的语言模型。BOOKCORPUS的特点是它的规模适中,便于下载和处理,同时涵盖了各种类型的书籍,能够提供丰富的语言知识。
-
英文维基百科:英文维基百科是一个巨大的在线百科全书,包含了大量的英文文本。BERT模型使用了维基百科的全量数据作为训练的一部分,以学习更加广泛和多样化的语言知识。
-
数据总大小:BERT模型训练时使用的文本数据总大小约为16GB的未压缩文本。这个数据量对于深度学习模型来说是适中的,足以让模型学习到丰富的语言特征,同时也不会导致训练时间过长。
Experimental Setup
Data
BERT风格的预训练依赖于大量的文本数据来训练深度神经网络以理解语言结构和意义。Baevski等人(2019年)证明了增加数据量可以导致最终任务应用的性能提高。
为了提升模型效果,作者使用了如下的数据:
-
BOOKCORPUS是一个包含英语书籍文本的小型语料库,由Zhu等人于2015年创建,用于预训练BERT模型。它包含了来自不同领域的书籍,共计约16GB的大小。这个语料库的特点是它包含了多种类型的文本,从而为BERT模型提供了丰富的语言信息。
-
CC-NEWS是一个大型英文新闻文章数据集,由CommonCrawl提供。我们从CommonCrawl News数据集中提取了6300万篇英文新闻文章,时间跨度从2016年9月至2019年2月。经过过滤后,数据集的大小约为76GB。这个数据集涵盖了各种新闻主题和风格,可以为BERT模型提供丰富的上下文信息。
-
OPENWEBTEXT是一个开源的WebText语料库复制品,由Gokaslan和Cohen于2019年发布。这个数据集是从Reddit上至少有三个点赞的URL中提取的网页内容,大小约为38GB。这个数据集的特点是它包含了用户生成的文本,从而为BERT模型提供了更具多样性和真实性的训练数据。
-
STORIES是一个由Trinh和Le于2018年介绍的数据集,它包含了一个过滤后与Winograd情景匹配的CommonCrawl数据的子集,以匹配故事式的风格。这个数据集的大小约为31GB。这个数据集的特点是它专注于故事类的文本,可以为BERT模型提供有关叙事和情节的理解能力。
Evaluation
为了评估模型效果,作者在GLUE、SQuAD、RACE进行了评估,这个不做详细介绍了。
Training Procedure Analysis
在这一节中,我们将详细介绍如何探索和量化对于成功预训练BERT模型的关键选择。我们假设模型的架构是固定的,即我们不改变模型的层数、隐藏单元大小、注意力头数等核心结构。
首先,我们将训练一系列的BERT模型,这些模型的配置与BERTBASE相同,即:
-
L = 12:模型包含12层Transformer编码层。
-
H = 768:每层中的隐藏单元数量为768。
-
A = 12:每层中的注意力头数量为12。
-
110M params:模型的总参数数量约为110百万。
通过保持模型架构不变,我们可以更好地理解不同预训练设置对模型性能的影响。在这个基础上,我们可以进行以下探索:
-
数据集的选择:不同的数据集可能包含不同的语言特征和知识,使用不同的数据集进行预训练可能会对模型的性能产生显著影响。
-
预训练任务的设计:预训练任务的设计也会影响模型的表现。例如,使用不同类型的掩码语言建模(MLM)任务或下一句预测(NSP)任务可能会导致模型学习不同的语言特征。
-
模型超参数的选择:虽然我们保持模型架构不变,但模型超参数(如学习率、批次大小、训练轮数等)的选择也会对预训练结果产生重要影响。
-
训练环境的差异:不同的硬件设备和软件环境可能会对模型的预训练产生影响。例如,使用不同的GPU或TPU、不同的操作系统和Python版本等。
通过以上探索,我们可以更好地理解哪些选择对于成功预训练BERT模型至关重要。这些发现对于改进预训练方法和提高模型性能具有重要意义。
Static vs. Dynamic Masking
这一节中,详细介绍了BERT模型在预训练阶段使用的两种不同的masking策略:静态masking和动态masking。
-
静态masking:在原始的BERT实现中,采用的是静态masking策略。这意味着在数据预处理阶段,每个输入序列只被随机mask一次,生成的mask pattern在整个训练过程中保持不变。为了避免在每轮训练中每个训练实例都使用相同的mask,训练数据被复制了10倍,这样在每个40个训练周期的训练中,每个序列都以10种不同的方式被masked。因此,在每个训练周期中,每个训练序列都会以相同的mask出现四次。
-
动态masking:与静态masking不同,动态masking策略是在每次将序列输入模型时都生成一个新的masking模式。这意味着在训练过程中,每个序列都有机会被以多种不同的方式masked,从而使模型能够学习到更多样化的语言特征。动态masking特别重要,当预训练的步数更多或数据集更大时,因为它可以避免模型在学习过程中产生偏差,并且提高模型的泛化能力。
通过比较这两种masking策略,我们可以了解它们对BERT模型性能的影响,以及在不同场景下应该选择哪种策略。这对于改进BERT模型的预训练过程和提高其性能具有重要意义。
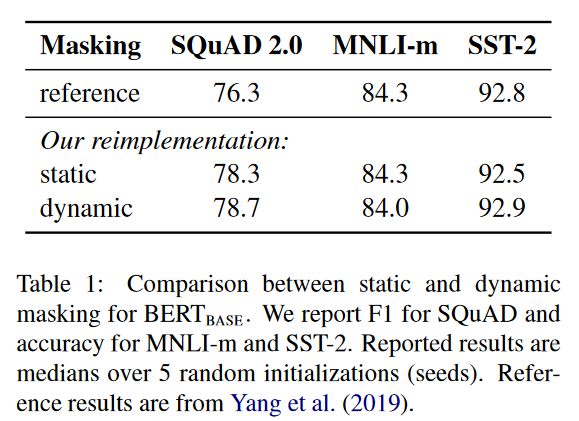
结果表1比较了Devlin等人(2019)发表的BERTBASE结果与我们使用静态或动态masking重新实现的结果。我们发现,我们使用静态masking的重新实现与原始BERT模型表现相似,而动态masking与静态masking相当或略好。鉴于这些结果以及动态masking额外的效率优势,我们在后续实验中使用动态masking。
Model Input Format and Next Sentence Prediction
在原始的BERT预训练过程中,模型会接受两种类型的文档片段作为输入。这两种文档片段要么来自同一个文档,要么来自不同的文档。模型需要学习如何处理这两种类型的输入,以便在各种下游任务中取得良好的表现。
除了 masked language modeling之外,BERT模型还需要完成一个辅助任务,即下一句预测(Next Sentence Prediction,NSP)。NSP任务的目的是让模型判断两个文档片段是否来自同一个文档。这个任务可以帮助模型学习文档的结构和语义关系。
在原始的BERT模型中,NSP损失被认为是一个重要的因素,有助于模型的训练和性能。Devlin等人(2019)在实验中发现,如果移除NSP损失,模型的性能会下降,特别是在QNLI、MNLI和SQuAD 1.1等任务上。这表明NSP损失在BERT模型的训练中起到了一定的作用。
然而,近年来的一些研究对NSP损失的必要性提出了质疑。Lample和Conneau(2019)、杨等人(2019)以及Joshi等人(2019)的研究表明,在某些情况下,移除NSP损失并不会对模型的性能产生负面影响。这可能意味着NSP损失并非在所有情况下都是必需的,而是取决于具体的下游任务和数据集。
为了更好地理解这种差异,我们比较了几种不同的训练格式:
-
SEGMENT-PAIR+NSP:这种格式遵循BERT(Devlin等人,2019年)原始的输入格式,包含NSP损失。每个输入包含一对片段,每个片段可以包含多个自然句子,但总共组合的长度必须小于512个标记。
-
SENTENCE-PAIR+NSP:每个输入包含一对自然句子,这对句子要么从同一文档的连续部分中采样,要么从不同的文档中采样。由于这些输入明显短于512个标记,我们增加了批量大小,以便总标记数与SEGMENT-PAIR+NSP相似。我们保留了NSP损失。
-
FULL-SENTENCES:每个输入包含从一到多个文档中连续采样完整的句子,总长度不超过512个标记。输入可能跨越文档边界。当我们在一个文档的末尾时,我们开始从下一个文档中采样句子,并在文档之间添加一个额外的分隔符标记。我们去掉了NSP损失。
-
DOC-SENTENCES:输入的构造方式与FULL-SENTENCES类似,只不过它们不允许跨越文档边界。从文档末尾附近采样的输入可能短于512个标记,因此在这些情况下,我们动态地增加批量大小,以实现与FULL-SENTENCES相似的总标记数。我们去掉了NSP损失。
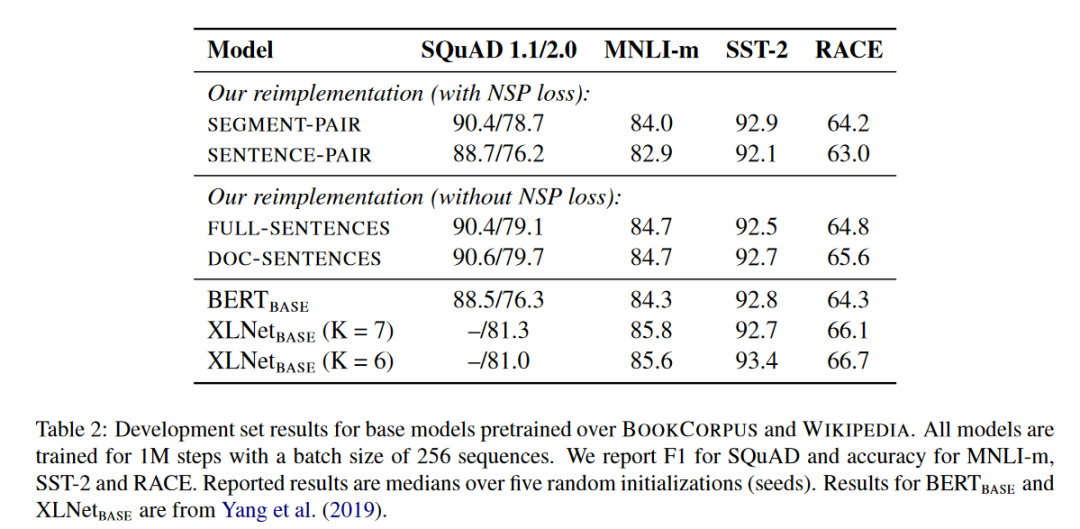
结果表2展示了四种不同设置的结果。我们首先比较了Devlin等人(2019)原始的SEGMENT-PAIR输入格式与SENTENCE-PAIR格式;这两种格式都保留了NSP损失,但后者的输入是单个句子。我们发现,使用单个句子会对下游任务的表现产生负面影响,我们假设这是因为模型无法学习长距离依赖关系。
接下来,我们比较了不使用NSP损失的训练和使用单一文档中的文本块(DOC-SENTENCES)的训练。我们发现,这种设置超过了原始发布的BERTBASE结果,并且移除NSP损失与下游任务的表现相匹配或略有提高,这与Devlin等人(2019)的结果相反。可能的情况是,原始BERT实现可能只是去除了损失项,而仍然保留了SEGMENT-PAIR输入格式。最后,我们发现限制序列来自单一文档(DOC-SENTENCES)略优于从多个文档中打包序列(FULL-SENTENCES)。然而,由于DOC-SENTENCES格式导致批量大小不一致,为了更容易与相关工作进行比较,我们将在剩余的实验中使用FULL-SENTENCES格式。
Training with large batches
在神经机器翻译领域,过去的研究表明,当学习率适当增加时,使用非常大的小批量可以提高优化速度和最终任务的性能(Ott等人,2018)。最近的研究也表明,BERT也适用于大规模批量训练(You等人,2019)。
Devlin等人(2019)最初使用256个序列的批量大小对BERTBASE进行了100万步的训练。通过梯度累积,这相当于用2000个序列的批量大小训练125000步,或者用8000个序列的批量大小训练31000步。
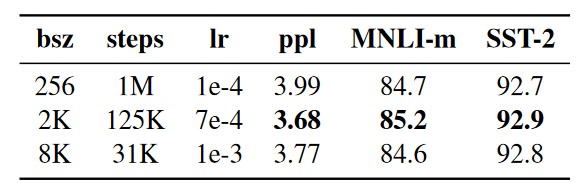
在我们控制训练数据遍历次数的情况下,随着批量大小的增加,我们观察到BERTBASE在各项任务表现上的提升。我们发现,使用大批量训练可以提高遮蔽语言建模目标的困惑度,以及最终任务的准确性。大批量也更容易通过分布式数据并行训练进行并行化,并且在后来的实验中,我们使用8000个序列的批量进行训练。
Text Encoding
Byte-Pair Encoding(BPE)(Sennrich等人,2016)是一种字符级别和单词级别表示的混合方法,它允许处理自然语言语料库中常见的较大词汇量。BPE不是依赖于完整的单词,而是依赖于子词单位,这些子词单位是通过对训练语料库进行统计分析提取的。
BPE词汇量通常从10K到100K的子词单位不等。然而,当建模大量多样化的语料库时,如本工作中考虑的语料库,Unicode字符可以占据这个词汇量的一个相当大的部分。Radford等人(2019)提出了一种聪明的BPE实现方法,它使用字节而不是Unicode字符作为基础子词单位。使用字节使得可以学习一个适度的子词词汇量(50K单位),这仍然可以编码任何输入文本,而不会引入任何“未知”的标记。
什么是BPE?
yte-Pair Encoding(BPE)是一种用于处理自然语言文本的分词和编码方法,它结合了字符级别和单词级别的表示。BPE特别适用于处理拥有大量词汇的语料库,这在自然语言处理(NLP)任务中是非常常见的。
BPE的工作原理是将文本分割成更小的单元,即子词(subwords),然后为这些子词分配唯一的编码。这些子词不是预先定义的单词,而是通过分析训练语料库中的统计数据自动提取的。BPE通过逐步合并出现频率最高的字节对(byte pairs)来构建子词单元,直到无法进一步合并为止,从而形成一个子词词汇表。
BPE的优势在于它能够适应大规模和多样化的词汇,这对于翻译、文本生成和其他NLP任务非常重要。与仅使用单词作为基本单元的方法相比,BPE可以更好地捕捉单词内部的结构信息,这对于处理一词多义和语言变体等现象非常有用。
Radford等人(2019)提出的改进版BPE使用字节作为基础子词单位,而不是Unicode字符。这种方法的一个优点是,它可以学习一个更小的子词词汇表,同时仍然能够编码任何输入文本,而不会遇到未知的标记。这意味着在训练过程中,模型不太可能遇到它无法识别的子词,这在处理大规模和多样化的文本数据时是一个重要的问题。
总之,BPE是一种灵活且有效的子词划分方法,它在NLP领域中被广泛应用,尤其是在机器翻译和自然语言生成等任务中。通过使用字节作为基本单元,BPE提供了一种在保持编码效率的同时处理复杂词汇的方法。
原始的BERT实现(Devlin等人,2019)使用了一个大小为30K的字符级BPE词汇表,这个词汇表是在使用启发式分词规则预处理输入后学习的。遵循Radford等人(2019)的方法,我们考虑使用一个更大的字节级BPE词汇表来训练BERT,该词汇表包含50K子词单位,而无需对输入进行额外的预处理或分词。这分别为BERTBASE和BERTLARGE增加了大约15M和20M的额外参数。
早期实验发现,这些编码之间的差异很小,Radford等人(2019)的BPE在某些任务上略微降低了端任务性能。尽管如此,我们认为通用编码方案的优点超过了性能上的一些轻微下降,并在我们剩余的实验中使用这种编码。
RoBERTa
在前一节中,我们提出了对BERT预训练过程的修改,这些修改可以提高端任务的表现。现在,我们将这些改进汇集起来,评估它们组合起来的影响。我们称这种配置为RoBERTa,意为“稳健优化的BERT方法”。
具体来说,更大的数据、更大的batch size、动态编码、不使用NSP、更大的BPE等等。
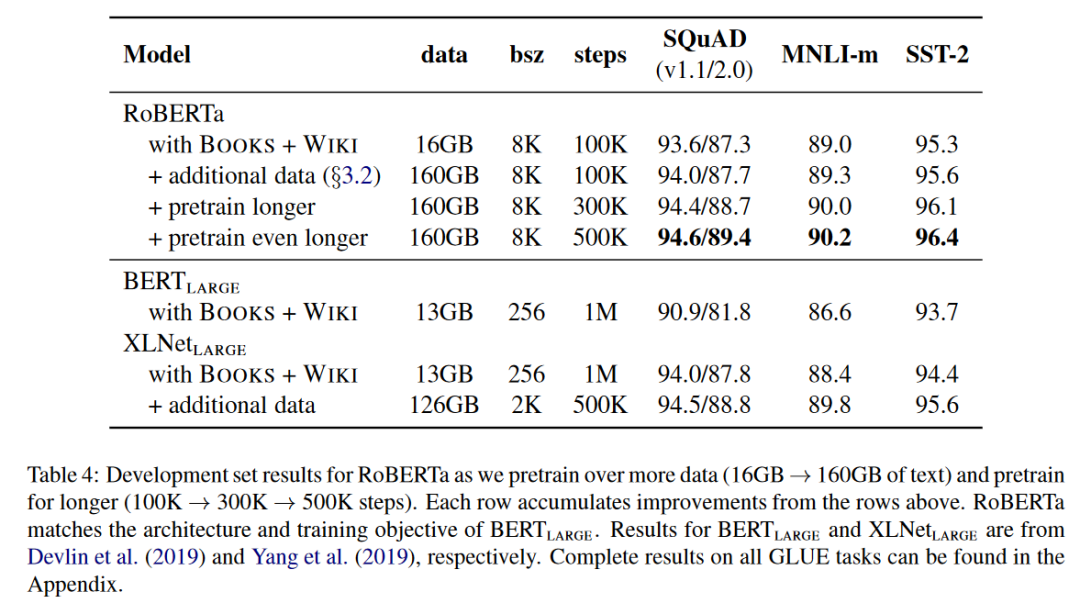
在表4中展示了我们的结果。当控制训练数据时,我们观察到RoBERTa相比于原始的BERTLARGE结果提供了很大的改进,这再次确认了我们在前述第4节中探索的设计选择的重要性。
接下来,我们将这个数据与前面描述的三个额外数据集结合起来。我们用相同的训练步骤数(100K)在结合的数据上训练RoBERTa。总共,我们在预训练过程中使用了160GB的文本。我们观察到在所有下游任务上的性能都有进一步的提高,这验证了预训练数据的大小和多样性的重要性。
最后,我们显著延长了RoBERTa的预训练时间,将预训练步骤从100K增加到300K,然后进一步增加到500K。我们再次观察到下游任务性能的显著提高,并且300K和500K步骤的模型在大多数任务上超过了XLNetLARGE。我们注意到,即使是我们的最长训练模型也没有出现在我们的数据上过拟合,并且很可能会从进一步的训练中受益。
在论文的剩余部分,我们评估了我们的最佳RoBERTa模型在三个不同的基准上:GLUE、SQuaD和RACE。
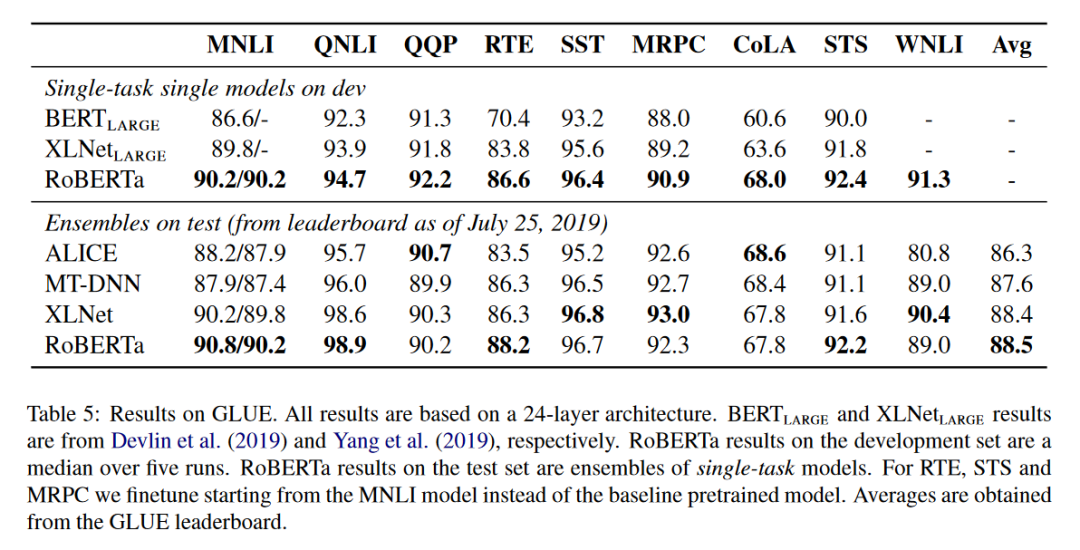
GLUE Results
下面是GLUE中模型的效果,其他数据集中的效果,我们就不再进行展示了,感兴趣的化,可以查看原论文。
参考
-
https://arxiv.org/pdf/1907.11692.pdf



















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











