






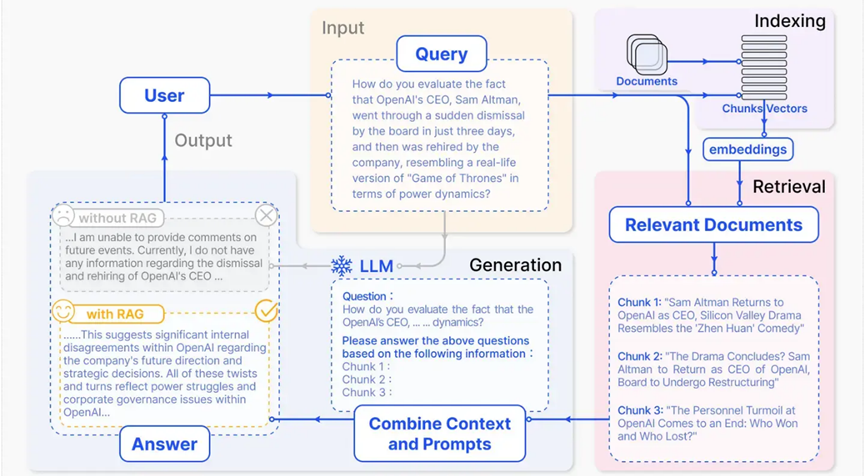
随着深度学习技术的飞速发展,特别是大型语言模型(Large Language Models, LLMs)的涌现,我们正步入一个全新的时代。这些模型通过大规模的训练,能够掌握丰富的语言知识和模式,具备回答复杂问题、生成多样文本的能力。然而,LLMs本身通常缺乏对特定领域知识的了解,因此在实际应用中,我们需要借助外部工具和资源来补充和扩展其能力。
想象一下,大模型就像是一个拥有无尽知识库和卓越沟通能力的超级学者,它拥有非凡的才华。它可以为你详细列出制作美食的步骤,包括原料比例和烹饪技巧,但它自己却无法亲自拿下厨,因此,让大型AI模型与外部工具相结合,就如同给这位超级学者配备了实验室、工厂、厨房等一系列实践场所和工具。这样,它不仅能够提供理论指导,还能通过外部工具将理论知识转化为实际行动,从而在实际应用中发挥更大的价值。
如何让大模型调用外部工具?
首先,需要明确大模型需要执行的任务和调用的外部工具类型。这些外部工具可能包括API、数据库、文件系统等。其次,根据任务需求,选择合适的外部工具,目前使用现有框架为:LangChain、Toolformer、HuggingGPT等等 。上期我们讲过HuggingGPT,今天我们就来讲下LangChain。
LangChain是一个用于开发大语言模型的应用程序框架,其中的Agents组件可以解决调用外部工具的问题。它可以将用户需求拆分成不同任务,并找到适合的工具进行调用。
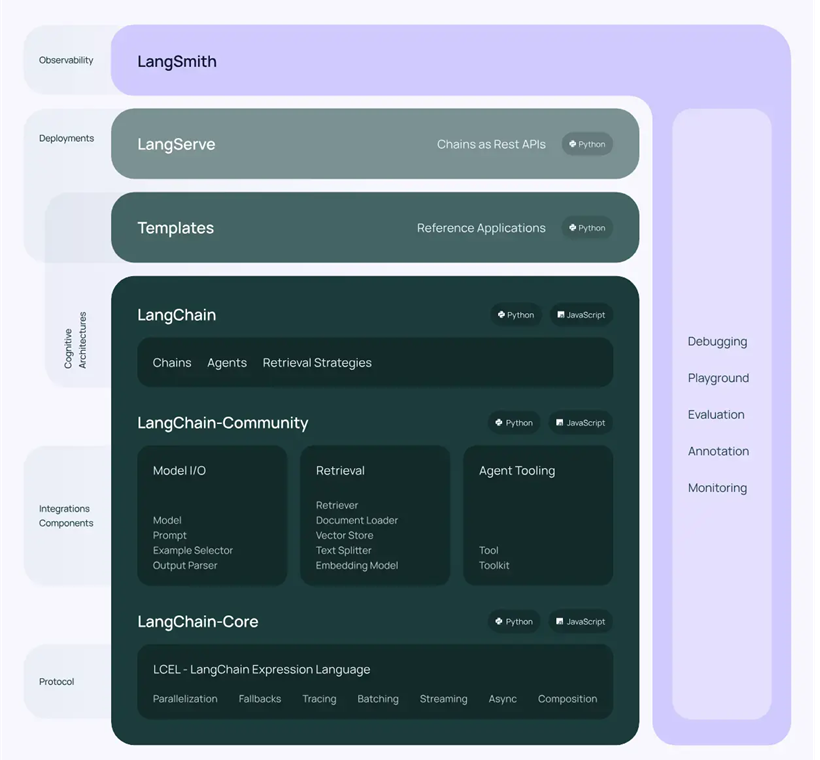
Langchain 的工作流程可以概括为以下几个步骤:
用户提问—问题处理与转换—信息检索—信息整合与输入—生成答案或执行操作—返回给用户。需要注意的是,LangChain本身是一个框架,它提供了一系列的工具和组件来支持上述流程中的各个环节,但具体的实现细节会根据项目的具体需求和所使用的技术栈而有所不同。
Langchain有6大核心模块:
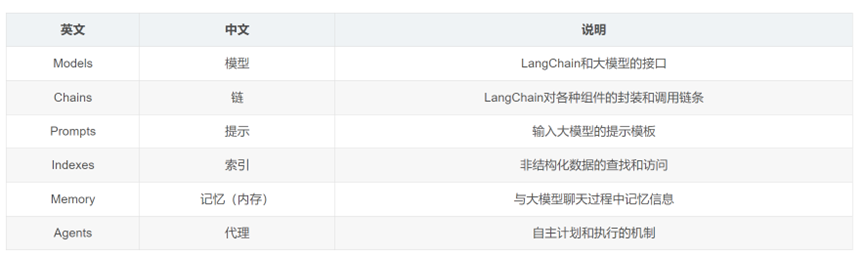
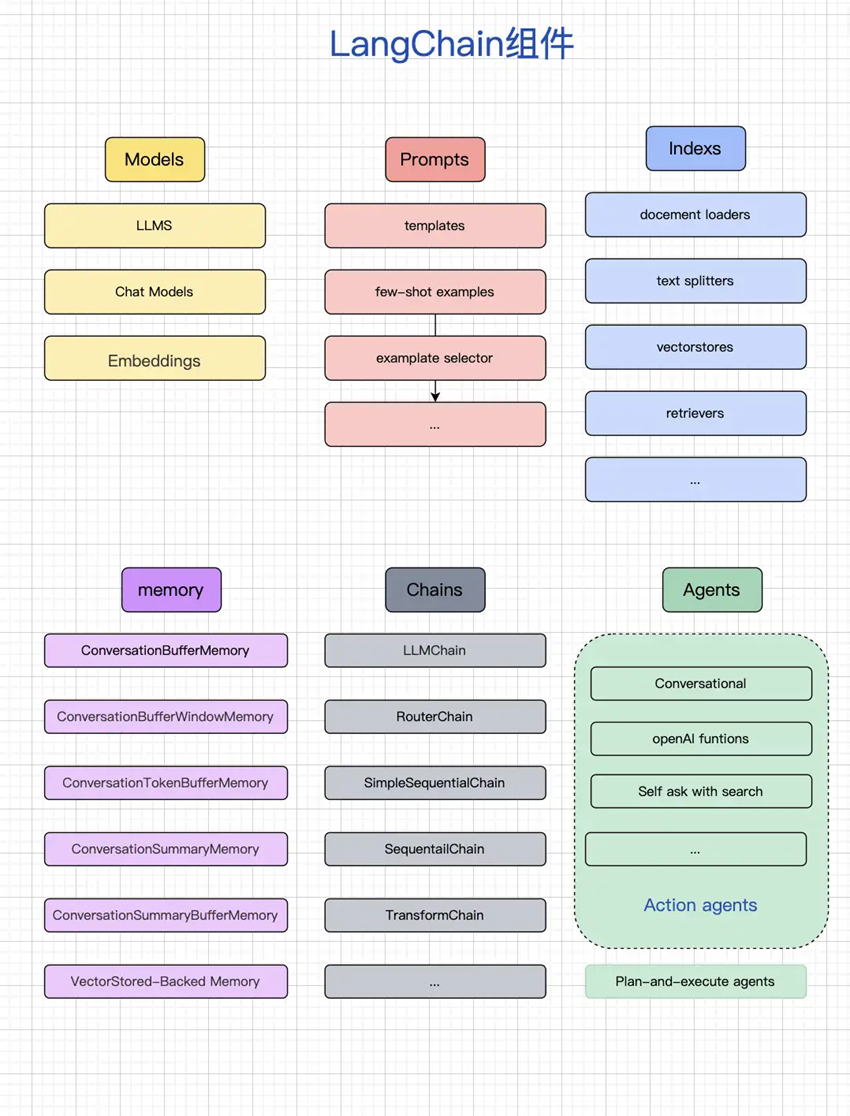
1. 模型(Models):包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。这些模型允许开发者与大语言模型进行交互,如GPT-4、Hugging Face等。
2. 提示模板(Prompts):使提示工程流线化,进一步激发大语言模型的潜力。提示模板用于将原始用户输入转换为更适合大语言模型处理的格式。
3. 数据检索(Indexes):构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。这包括文档加载器、文档转换器、文本嵌入模型、向量存储和检索器等组件。
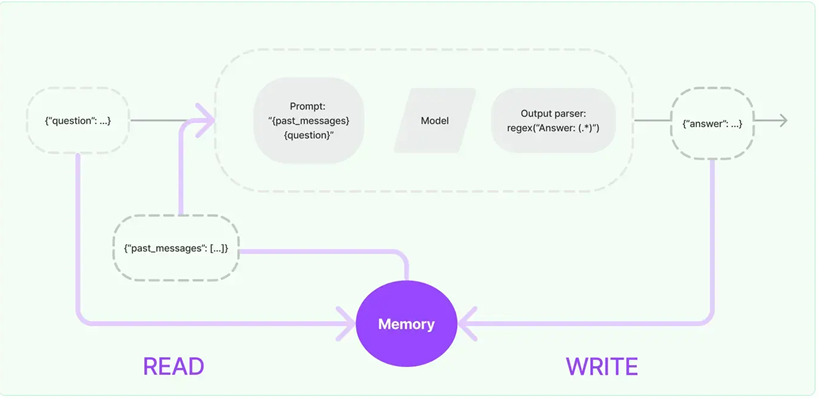
4. 记忆(Memory):通过短时记忆和长时记忆,在对话过程中存储和检索数据,使ChatBot能够记住对话历史。
5. 链(Chains):LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成任务。链是LangChain中用于连接不同组件并执行复杂任务的关键机制。
6. 代理(Agents):通过“代理”让大模型自主调用外部工具和内部工具,使智能Agent成为可能。代理是LangChain中另一个核心机制,它负责根据任务需求调用适当的工具和资源。
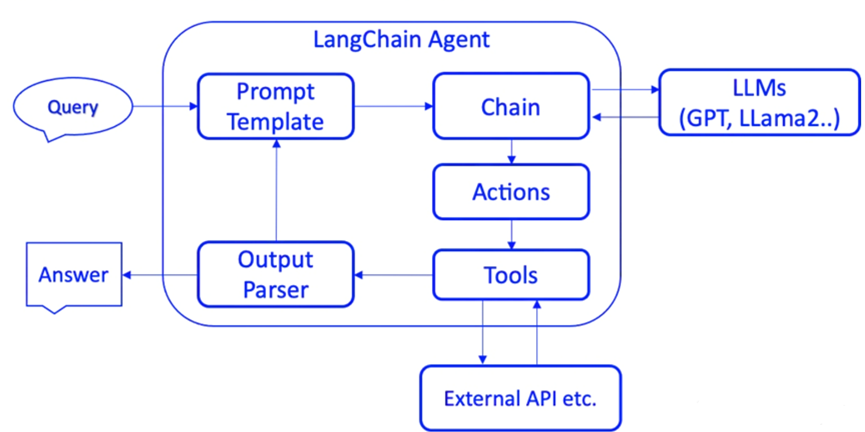
LangChain可以理解为:在一个流程的整个生命周期中,管理和优化prompt,根据prompt使用不同的代理进行不同的动作,在这期间使用内存管理中间的一些状态,然后使用链将不同代理之间进行连接起来,最终形成一个闭环。LangChain 也通常被用作「粘合剂」,将构建 LLM 应用所需的各个模块连接在一起。旨在帮助开发者将大型语言模型与外部计算和数据来源结合起来,以创建复杂的、基于自然语言处理的应用程序。
随着LLM技术的不断发展和普及,LangChain作为一个专注于LLM应用的框架,其价值和重要性也将不断提升。未来,LangChain将继续提供更多强大的组件和工具,支持更多类型的数据源和模型,以满足开发者对复杂LLM应用的需求。同时,LangChain还将加强与其他人工智能技术的集成和协作,推动人工智能技术的创新和发展。

















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











