







前段时间又被人问了会不会爬虫,然后感觉现在爬取数据好像还是挺有用的,所以就在网上找了课程学习了一下,利用Python对网站进行爬取和解析等等。原来使用过八爪鱼这个软件,不太需要有什么编程基础,但是也已经忘得差不错了,所以就想着学习利用Python进行爬取。
一、对爬虫的理解:
爬虫听上去似乎很高大上,其实简单一句话就是:模仿浏览器对网页进行访问并解析,进一步从中复制我们想要的信息,然后将其保存起来。
总共可以将其分为3个步骤:
- 爬取网页
- 解析数据
- 保存数据
这个时候我们就要想一想我们平时怎么使用浏览器浏览网页的,首先我们需要一个网址,然后回车后就会看到我们想看到的内容,然后利用鼠标点击进行点击相应的超链接进行进一步的访问。
接下来我们就要开启模拟浏览器访问数据了。
二、爬取网页
1.模仿浏览器
当浏览器对网址进行访问时,首先需要向服务器发送一个访问请求,并且将浏览器自身的一些信息发送给服务器,服务器接收到浏览器发送的信息之后开始检查,看这个“浏览器”是否有访问的权限,以及可以接受什么样的文件,然后服务器才能将信息发送到相应的浏览器上呈现给用户。
那么显而易见,我们现在要做的事情就是 模仿浏览器 给服务器发送信息:用户代理(User-Agent)!至于这个用户代理具体的含义以及用法还不是很清楚,但是可以简单的理解为我的浏览器的一个标志,表示我们是一个浏览器,而不是爬虫。
2.实例分析
下面以豆瓣为例,爬取前250名的高分电影的信息。其中需要导入一些包,包括网页解析、网页访问的和一些数据库操作的包。先来进行获取网页数据,对于解析和保存后面再慢慢学习。
(1)代码
# 导入所用到的包
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 指定URL,获取网页数据
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite数据库操作
# 主函数
def main():
baseurl = "https://movie.douban.com/top250?start="
# 1.爬取网页
datalist = getData(baseurl)
# 2.解析网页
# 3.保存数据
# 爬取网页函数
def getData(baseurl):
datalist = []
for i in range(0,10):
n = str(i*25) # 页数
url = baseurl + n # 每一页的网址
html = askURL(url) # 访问每一个网页的内容
datalist.append(html)
return datalist
# 得到指定一个url的网页内容函数
def askURL(url):
# 模拟浏览器头部信息,向豆瓣服务器发送消息(伪装)
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器/浏览器(本质上告诉浏览器,我们可以接受什么水平的文件内容)
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == "__main__":
# 调用函数
main()
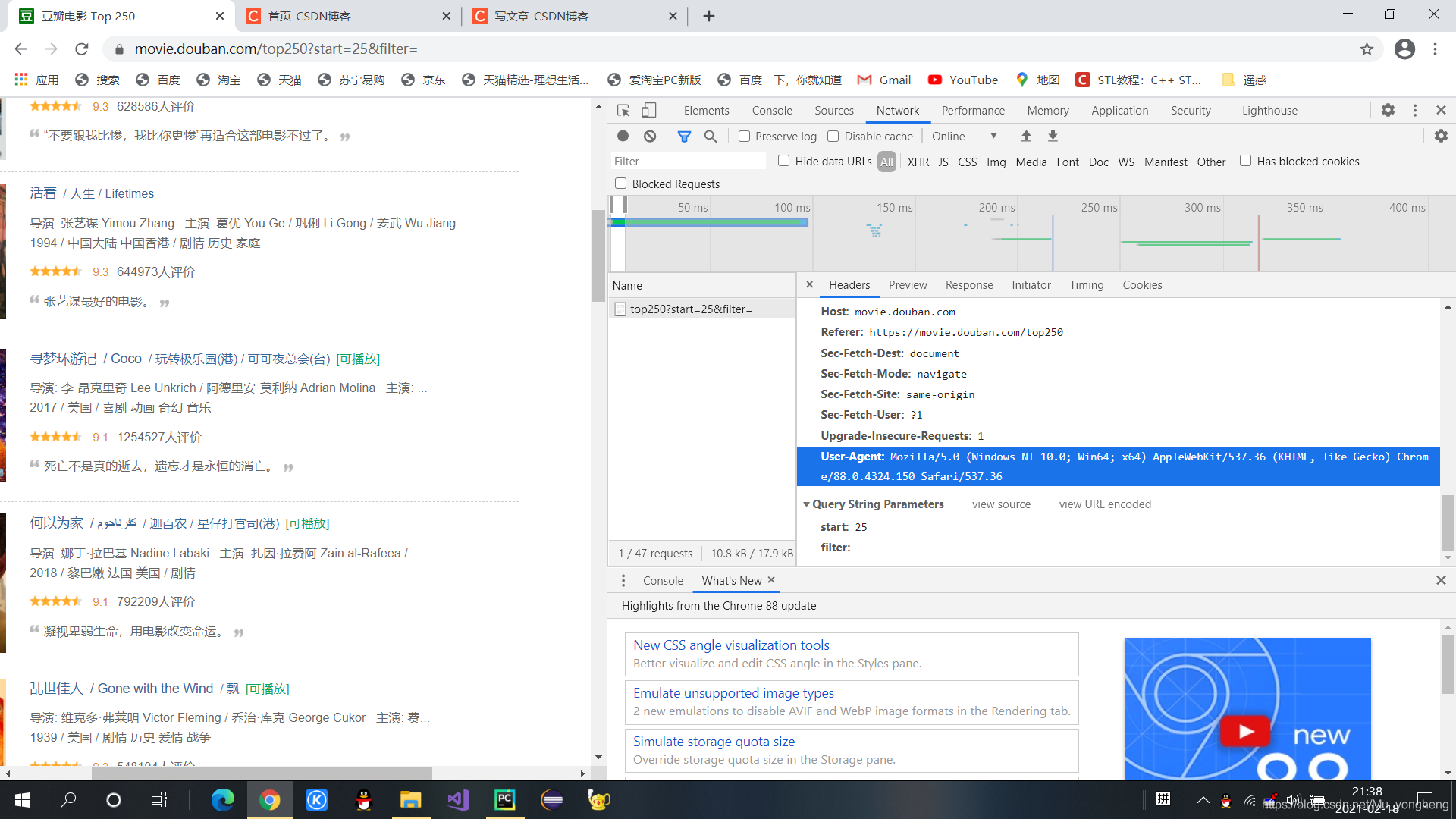
(2)获取浏览器User-Agent
上面代码中需要说明的就是用户代理的那个变量head,可以直接在我们现有的浏览器中复制粘贴,打开一个网页,按F12键,然后点击Network,然后将网页刷新一下,点击红点暂停,点击一个请求,然后下拉到最后就会看到 User-Agent,直接复制粘贴过来即可!下面为操作截图。
1、打开网址
2、按F12键,然后点击Network
3、刷新网页
4、点击请求
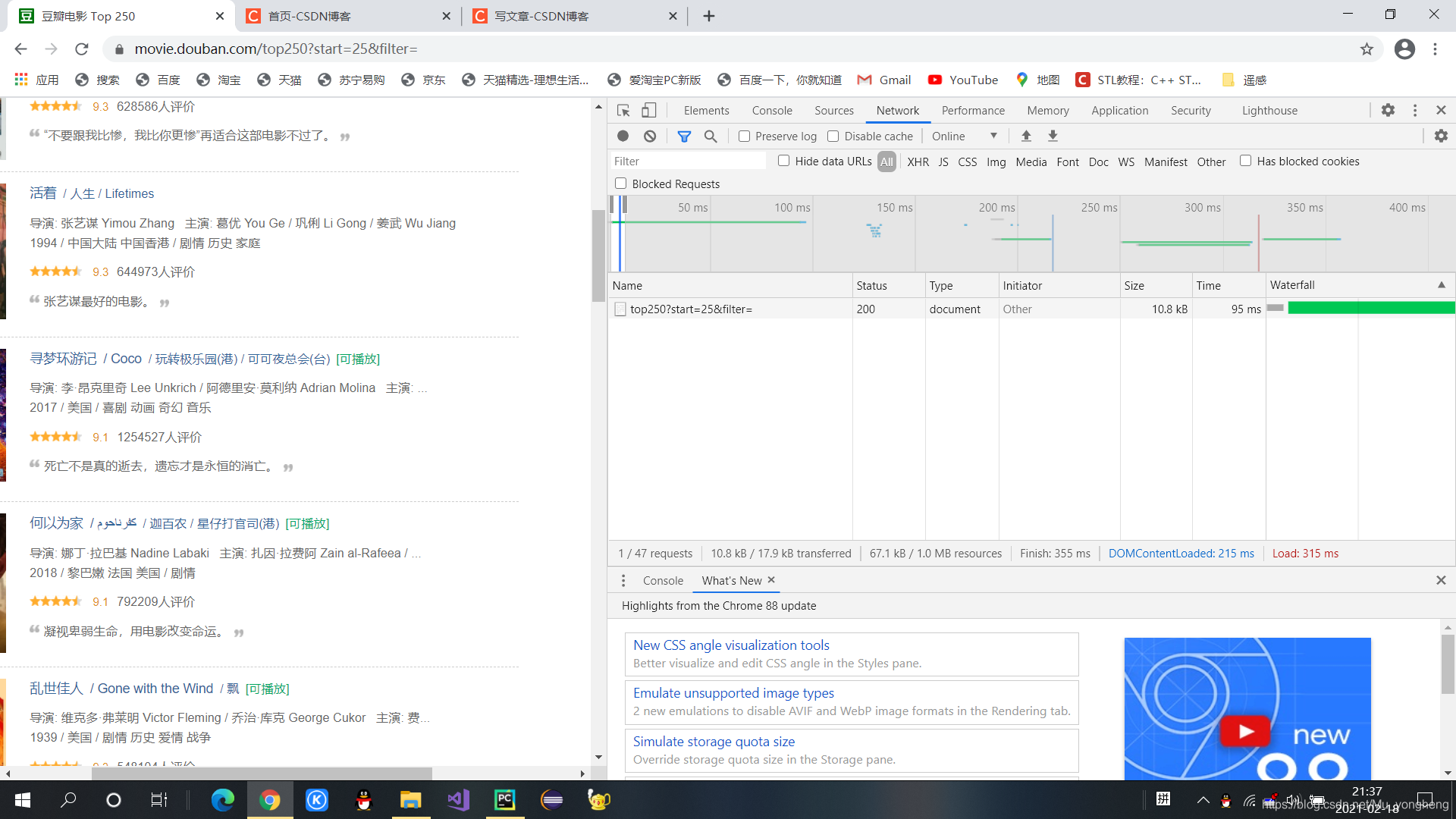
5、复制粘贴User-Agent
总结
以上就是对网页访问的的一个基本的操作和代码,只实现了网页的简单访问,对于网页的解析和数据的保存后续在慢慢学习!
















 2774
2774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











