






 本文介绍了如何使用Java技术栈,如SpringBoot和langchain4j,构建一个基于大模型RAG系统的知识库,涉及数据预处理、用户提问流程、嵌入模型和LLM的整合。核心代码展示了知识库预处理和用户提问的逻辑,以及PostgreSQL作为向量数据库的应用。
本文介绍了如何使用Java技术栈,如SpringBoot和langchain4j,构建一个基于大模型RAG系统的知识库,涉及数据预处理、用户提问流程、嵌入模型和LLM的整合。核心代码展示了知识库预处理和用户提问的逻辑,以及PostgreSQL作为向量数据库的应用。
目前大部分基于大模型的应用都是用python写的,本文使用java实现一个基于大模型的知识库(RAG系统)。
一、技术栈
1.1 开发框架:SpringBoot、langchain4j
1.2 数据库: Postgresql(需要安装pgvector插件以支持向量数据)
1.3 嵌入模型(embedding model):all-minilm-l6-v2、e5-small-v2、bge-small-en、bge-small-zh
1.4 大语言模型(LLM):GPT
二、RAG基本流程
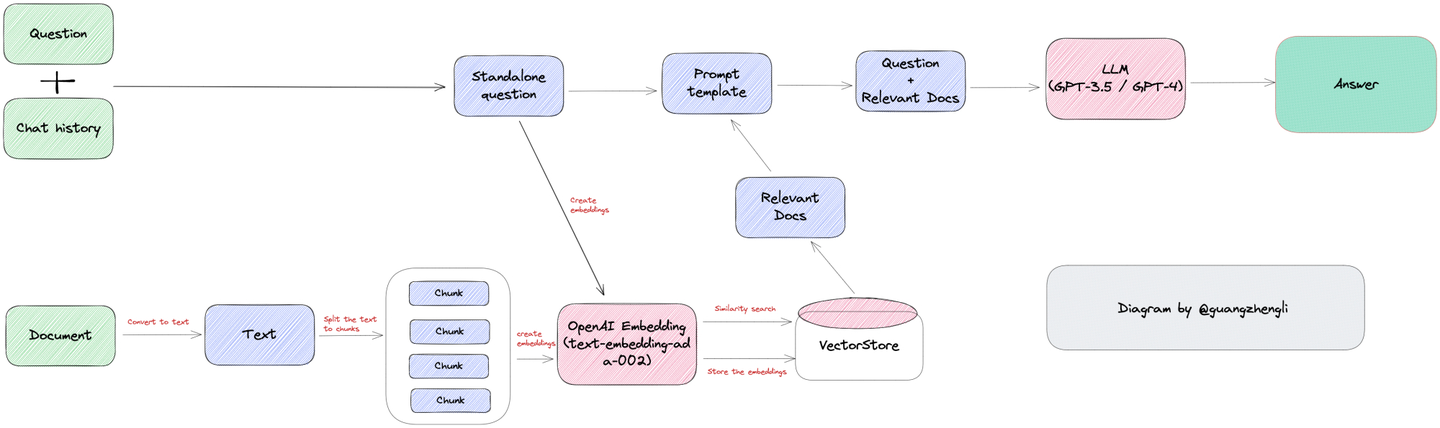
主要分为两步:
步骤一:知识库数据预处理(向量化)
由分词器将知识切块,再交由embeding model向量化,接着将向量数据存储向量数据库中(此时我们将这些数据存储到postgres中)
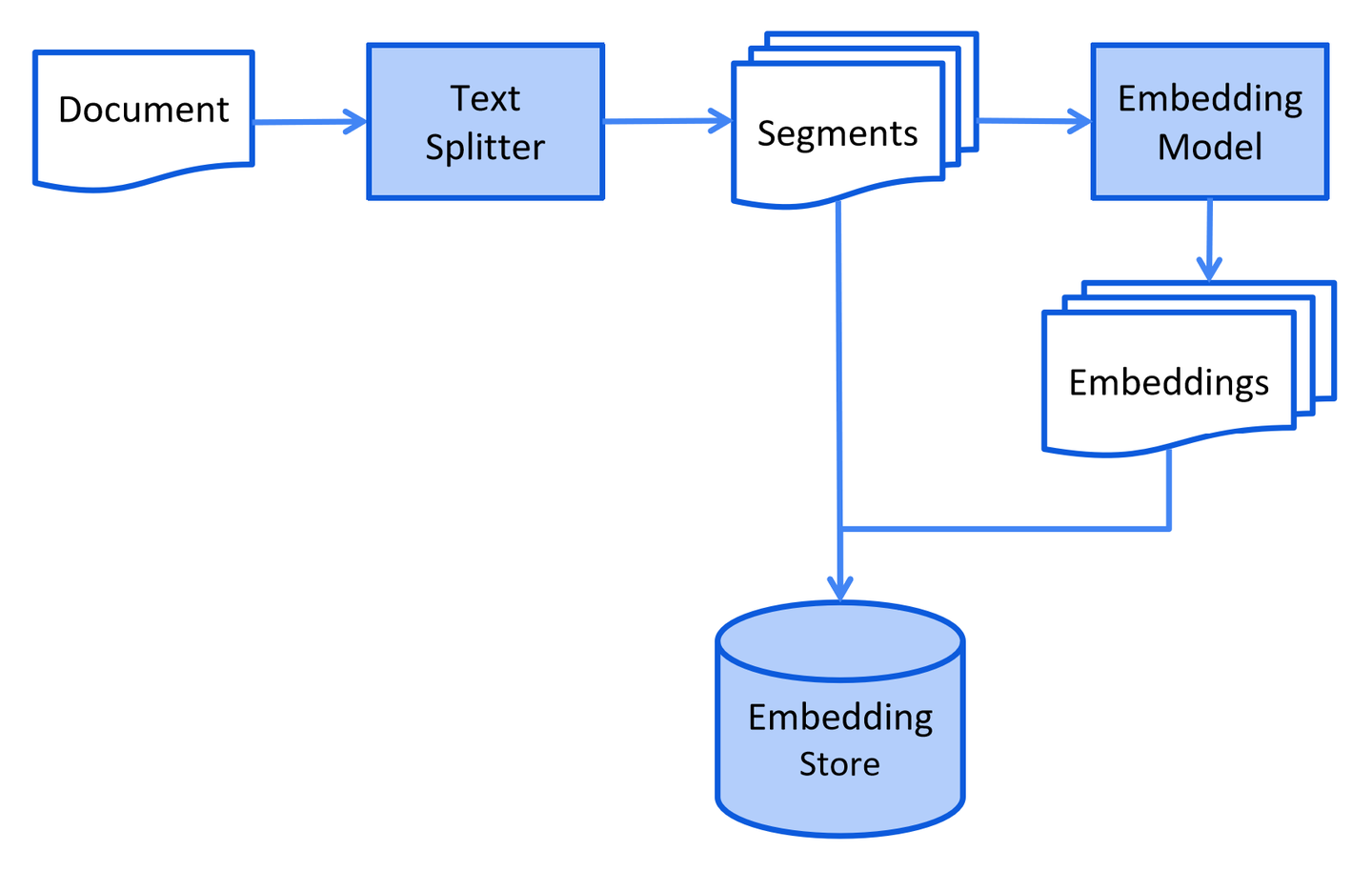
步骤二:用户提问
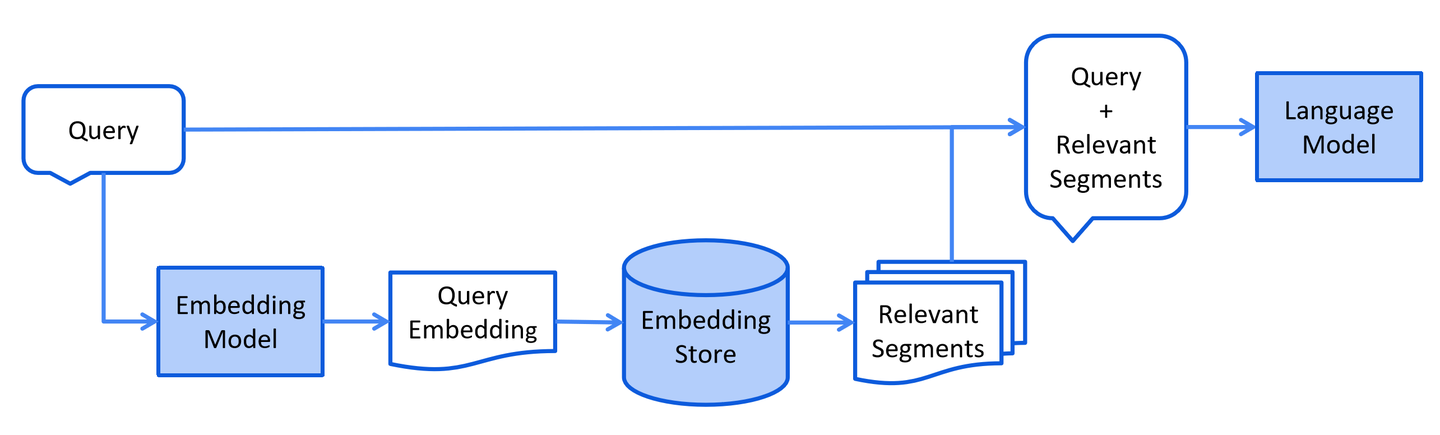
用户提问(搜索)这一流程也可以分为两步:
-
文档召回:用户的问题交由embedding model向量化,并从向量数据库中进行近似搜索,返回匹配的top k个向量数据(此时通常将对应的文本块也一并返回)
-
向LLM提问:程序自动将匹配的内容与用户问题组装成一个Prompt,向大语言模型提问,大语言模型返回答案
三、代码
知识库预处理核心代码:
EmbeddingStoreIngestor.builder()
.documentSplitter(documentSplitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build()
.ingest(document);用户提问逻辑核心代码:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(2) // on each interaction we will retrieve the 2 most relevant segments
.minScore(0.5) // we want to retrieve segments at least somewhat similar to user query
.build();
CustomerSupportAgent agent = AiServices.builder(CustomerSupportAgent.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
agent.answer("用户的问题");四、最终效果
4.1 上传知识库文件
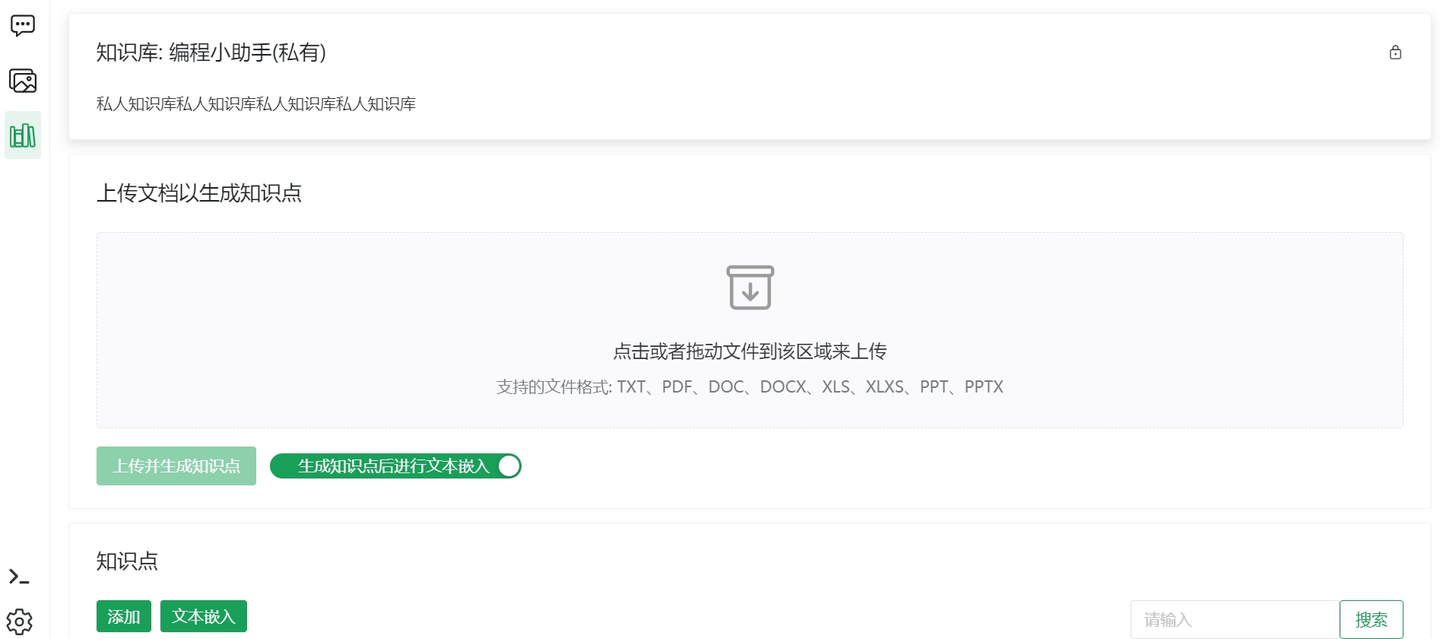
4.2 文本分块并向量化
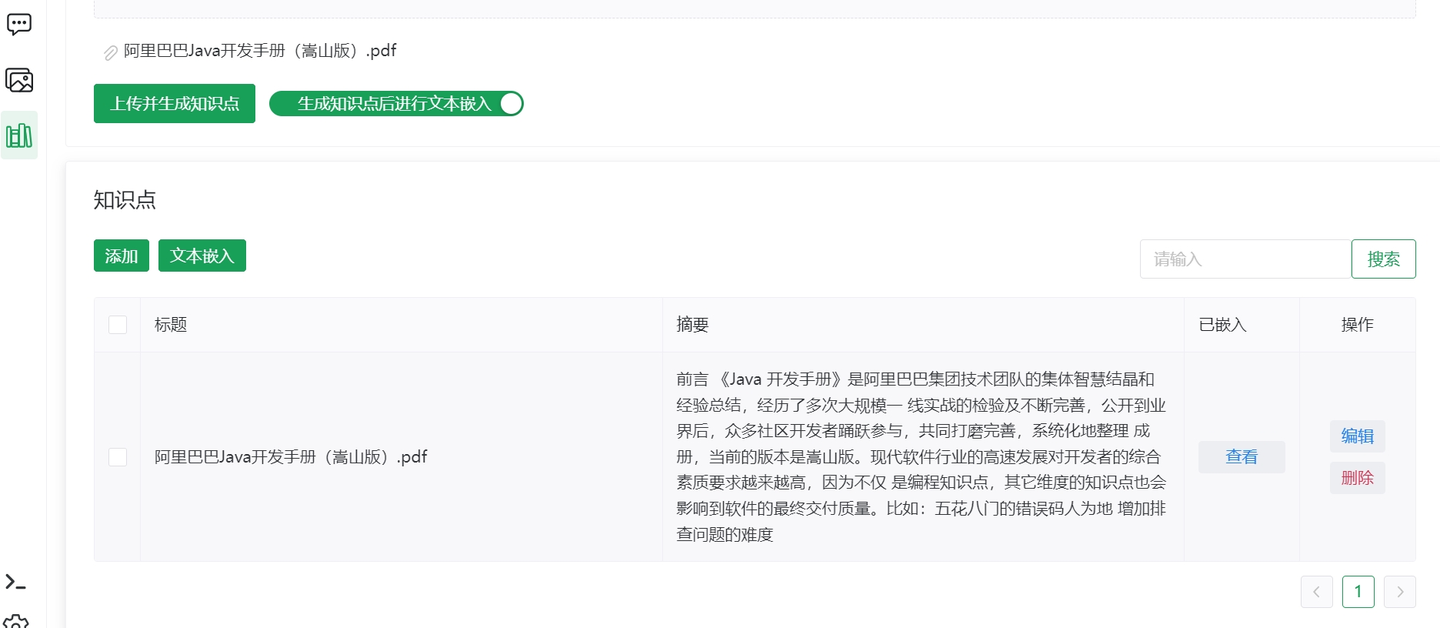
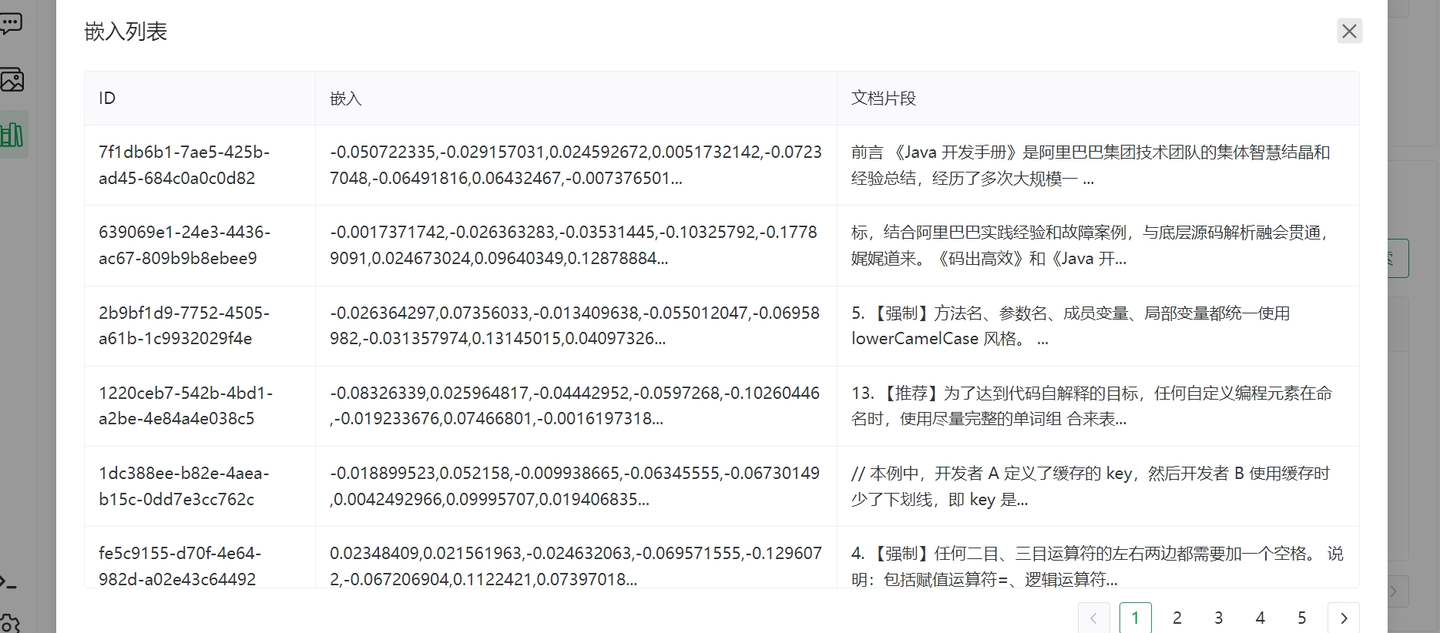
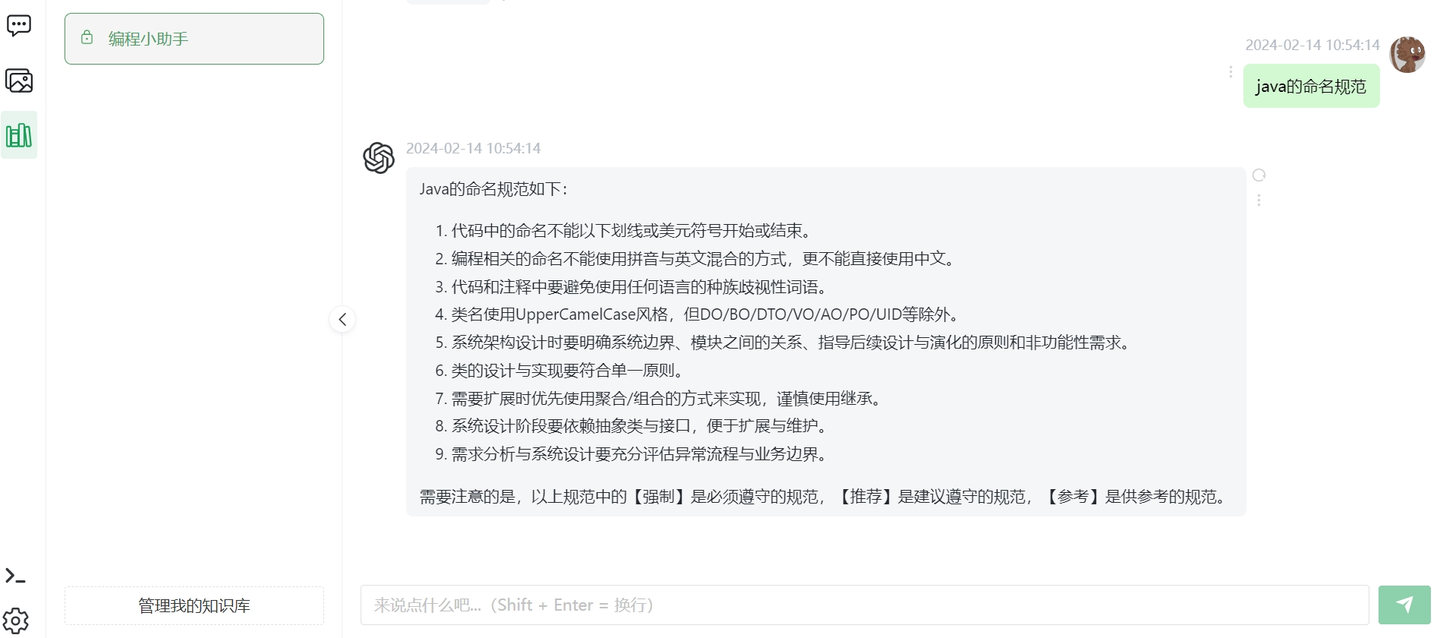
4.3 搜索效果
完整代码见:GitHub - moyangzhan/langchain4j-aideepin: JAVA版本的检索增强(RAG)大模型知识库项目

















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









